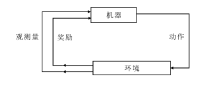
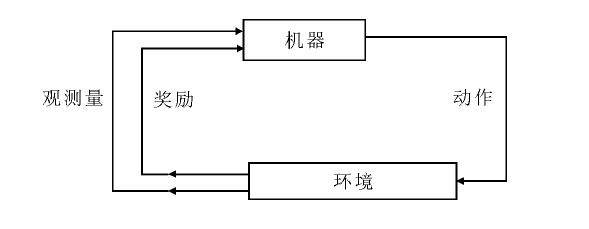
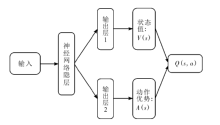
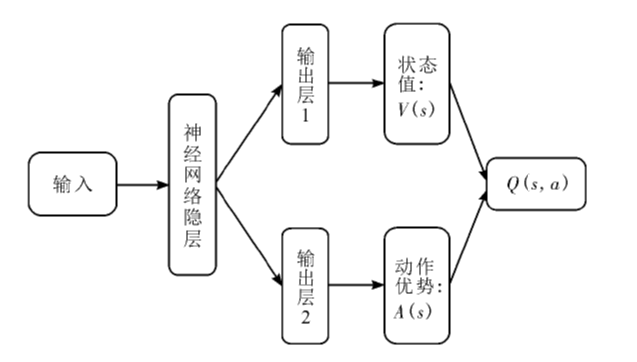
| [1] |
LAVALLE S M . Motion Planning[J]. IEEE Robotics and Automation Magazine, 2011,18(2):108-118.
|
| [2] |
NILSSON N J . Shakey the Robot[J]. Sri International Menlo Park, 1984,42(1991):38-65.
|
| [3] |
ORLIN J . Network Flows[J]. Journal of the Operational Research Society, 1993,45(11):791-796.
|
| [4] |
STENTZ A. The Focussed D* Algorithm for Real-time Replanning [C]//Proceedings of the 1995 IEEE Joint Conference on Artificial Intelligence. Piscataway: IEEE, 1995: 1652-1659.
|
| [5] |
KHATIB O . Real-time Obstacle Avoidance for Manipulators and Mobile Robots[J]. International Journal of Robotics Research, 1986,5(1):90-98.
doi: 10.1007/978-1-4613-8997-2_29
|
| [6] |
SUTTON R S, BARTO A G. Reinforcement Learning: an Introduction[M]. 2nd edition. Cambridge: The MIT Press, 2017.
|
| [7] |
ZHANG Q C, LIN M, YANG L T , et al. Energy-efficient Scheduling for Real-time Systems Based on Deep Q-learning Model[J]. IEEE Transactions on Sustainable Computing, 2017, DOI 10.1109/TSUSC. 2017. 2743704.
doi: 10.1109/TSUSC.2017.2743704
|
| [8] |
DERHAMI V, MAJD V J, AHMADABADI M N . Fuzzy Sarsa Learning and the Proof of Existence of Its Stationary Points[J]. Asian Journal of Control, 2008,10(5):535-549.
doi: 10.1002/asjc.54
|
| [9] |
MNIH V, KAVUKCUOGLU K, SILVER D , et al. Human Level Control Through Deep Reinforcement Learning[J]. Nature, 2015,518:529-533.
doi: 10.1038/nature14236
pmid: 25719670
|
| [10] |
MNIH V, KAVUKCUOGLU K, SILVER D , et al. Playing Atari with Deep Reinforcement Learning[J]. Computer Science, 2013,1312(5602):23-32.
|
| [11] |
PAN J, WANG X CHENG Y , et al. Multisource Transfer Double DQN Based on Actor Learning[J]. IEEE Transactions on Neural Networks and Learning Systems, 2018,29(6):2227-2238.
doi: 10.1109/TNNLS.2018.2806087
|
| [12] |
WANG Z, SCHAUL T, HESSEL M, et al. Dueling Network Architectures for Deep Reinforcement Learning [C]// Proceedings of the 2016 33rd International Conference on Machine Learning. Lille: International Machine Learning Society (IMLS), 2016: 2939-2947.
|