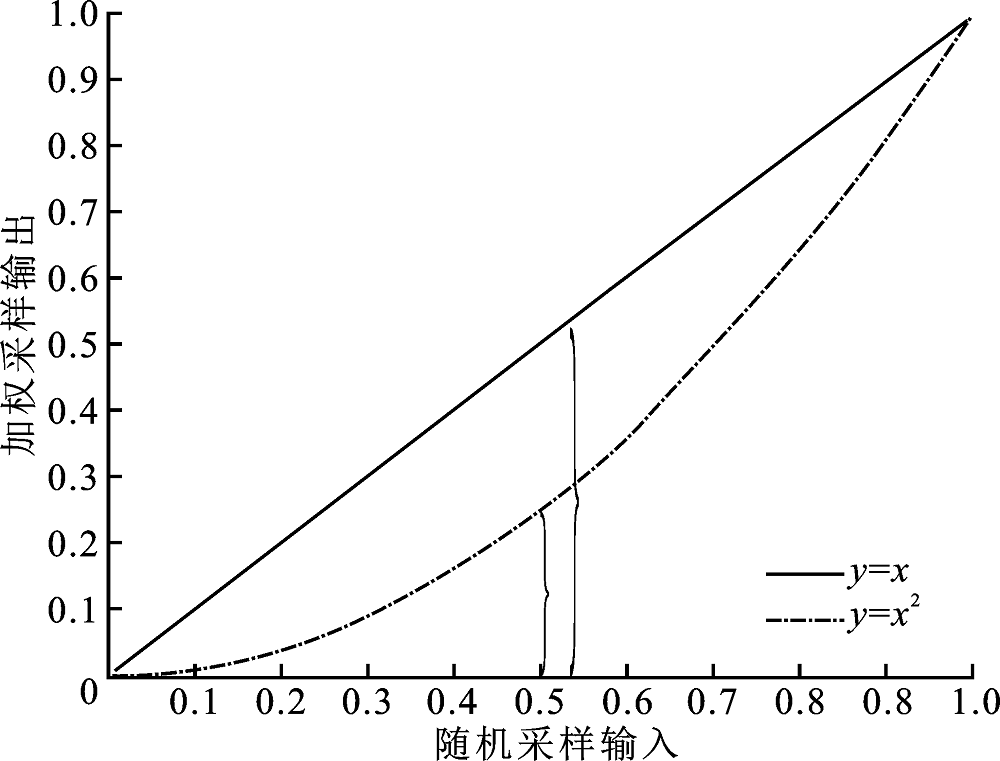
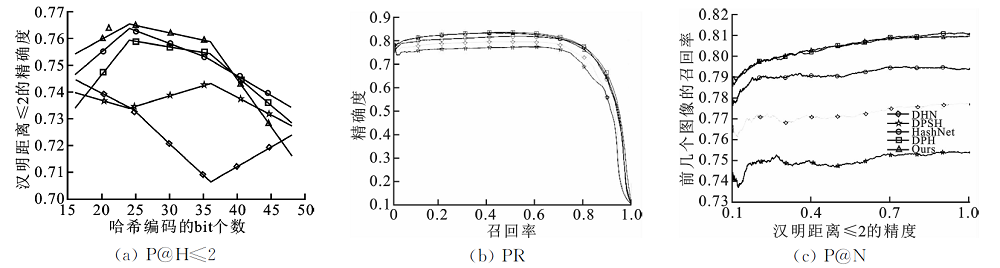
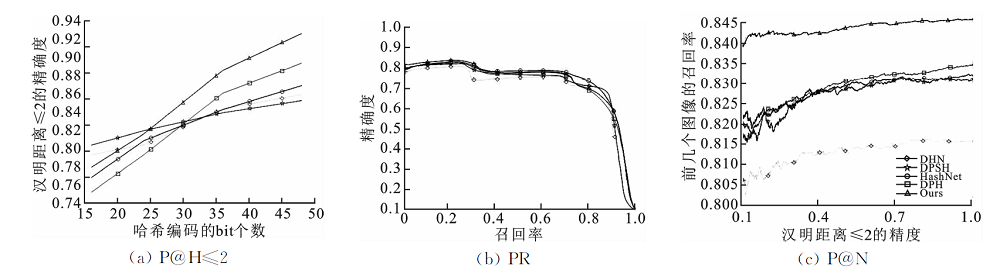
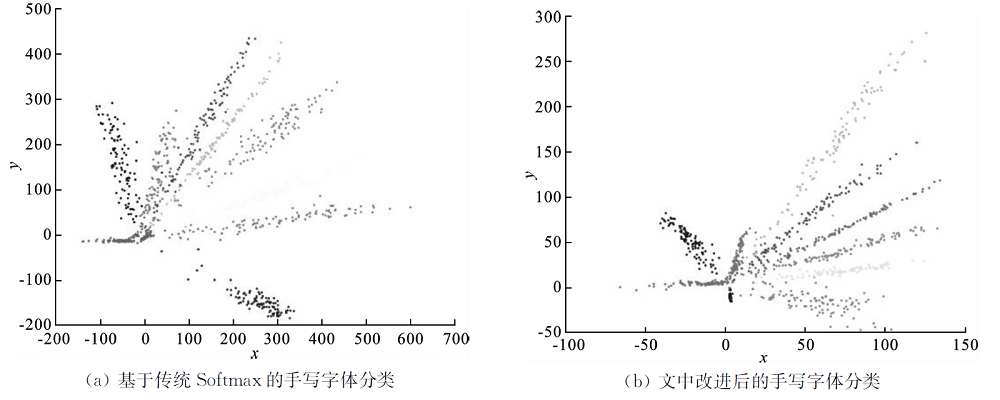
| [1] |
WANG J D, ZHANG T, SONG J K, et al. A Survey on Learning to Hash[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018,40(4):769-790.
doi: 10.1109/TPAMI.34
|
| [2] |
HASHING D P, CAO Z J, SUN Z P, et al. Deep Priority Hashing[C]// Proceedings of the 2018 ACM Multimedia Conference.New York:ACM, 2018: 1653-1661.
|
| [3] |
LIU H M, WANG R P, SHAN S G, et al. Deep Supervised Hashing for Fast Image Retrieval[C]// Proceedings of the 2016 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2016: 2064-2072.
|
| [4] |
CAO Z J, LONG M S, WANG J M, et al. HashNet:Deep Learning to Hash by Continuation[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision.Piscataway:IEEE, 2017: 5609-5618.
|
| [5] |
LI W J, WANG S, KANG W C. Feature Learning Based Deep Supervised Hashing with Pairwise Labels[C]// Proceedings of the 2016 International Joint Conference Artificial Intelligence.New York:International Joint Conferences on Artificial Intelligence, 2016: 1711-1717.
|
| [6] |
ZHU H, LONG M S, WANG J M, et al. Deep Hashing Network for Efficient Similarity Retrieval[C]// Proceedings of the 2016 30th AAAI Conference on Artificial Intelligence.Palo Alto:AAAI, 2016: 2415-2421.
|
| [7] |
曾燕, 陈岳林, 蔡晓东. 结合全局与局部池化的深度哈希人脸识别算法[J]. 西安电子科技大学学报, 2018,45(5):163-169.
|
|
ZENG Yan, CHEN Yuelin, CAI Xiaodong. Face Recognition Algorithm for the Deep Hash Combined with Global and Local Pooling[J]. Journal of Xidian University, 2018,45(5):163-169.
|
| [8] |
YANG H F, LIN K, CHEN C S. Supervised Learning of Semantics-preserving Hash via Deep Convolutional Neural Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018,40(2):437-451.
doi: 10.1109/TPAMI.2017.2666812
|
| [9] |
CAO L F, GAO L L, SONG J K, et al. Multiple Hierarchical Deep Hashing for Large Scale Image Retrieval[J]. Multimed Tools and Application, 2018,77(9):10471-10484.
doi: 10.1007/s11042-017-4489-0
|
| [10] |
SHI X, SAPKOTA M, XING F, et al. Pairwise Based Deep Ranking Hashing for Histopathology Image Classification and Retrieval[J]. Pattern Recognition, 2018,81:14-22.
doi: 10.1016/j.patcog.2018.03.015
|
| [11] |
SHRIVASTAVA A, GUPTA A, GIRSHICK R. Training Region-based Object Detectors with Online Hard Example Mining[C]// Proceedings of the 2016 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2016: 761-769.
|
| [12] |
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal Loss for Dense Object Detection[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision.Piscataway:IEEE, 2017: 2999-3007.
|
| [13] |
TRAN G S, NGHIEM T P, NGUYEN V T, et al. Improving Accuracy of Lung Nodule Classification Using Deep Learning with Focal Loss[J]. Journal of Healthcare Engineering, 2019,2019(2019):5156416.
|
| [14] |
LIU W, CHEN L, CHEN Y. Age Classification Using Convolutional Neural Networks with the Multi-class Focal Loss[C]// Proceedings of the 2018 IOP Conference Series: Materials Science and Engineering.Bristol:IOP Publishing Ltd, 2018: 012043.
|
| [15] |
PULGAR F J, RIVERA A J, CHARTE F, et al. On the Impact of Imbalanced Data in Convolutional Neural Networks Performance[C]// Lecture Notes in Computer Science:10334.Heidelberg:Springer Verlag, 2017: 220-232.
|
| [16] |
SCHROFF F, KALENICHENKO D, PHILBIN J. FaceNet:a Unified Embedding for Face Recognition and Clustering[C]// Proceedings of the 2015 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2015: 815-823.
|
 ),CAI Xiaodong(
),CAI Xiaodong(