

Journal of Xidian University ›› 2022, Vol. 49 ›› Issue (4): 144-155.doi: 10.19665/j.issn1001-2400.2022.04.017
• Computer Science and Technology • Previous Articles Next Articles
GAO Deyong1,2( ),KANG Zibing1(),WANG Song1,2(),WANG Yangping1,3()
),KANG Zibing1(),WANG Song1,2(),WANG Yangping1,3()
Received:2021-03-24
Online:2022-08-20
Published:2022-08-15
Contact:
Zibing KANG
E-mail:258680916@qq.com;914764692@qq.com;wangsong@mail.lzjtu.cn;1328396793@qq.com
CLC Number:
GAO Deyong,KANG Zibing,WANG Song,WANG Yangping. Method to recognize human action by using the convolutional block attention mechanism[J].Journal of Xidian University, 2022, 49(4): 144-155.
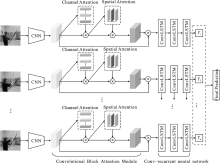
"
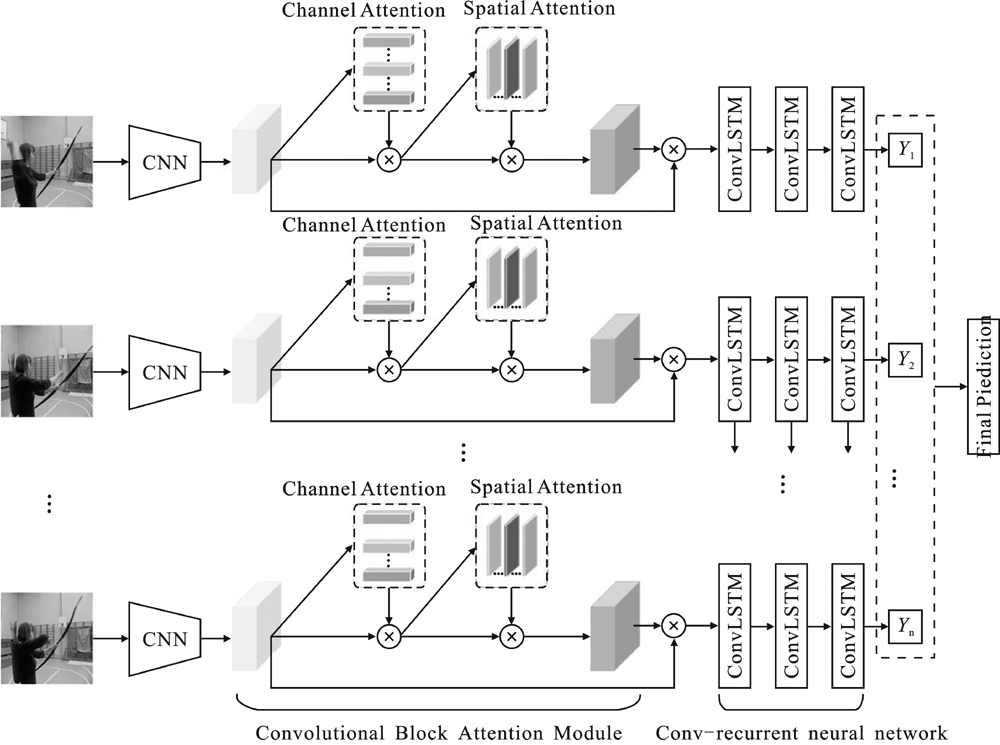
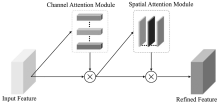
"
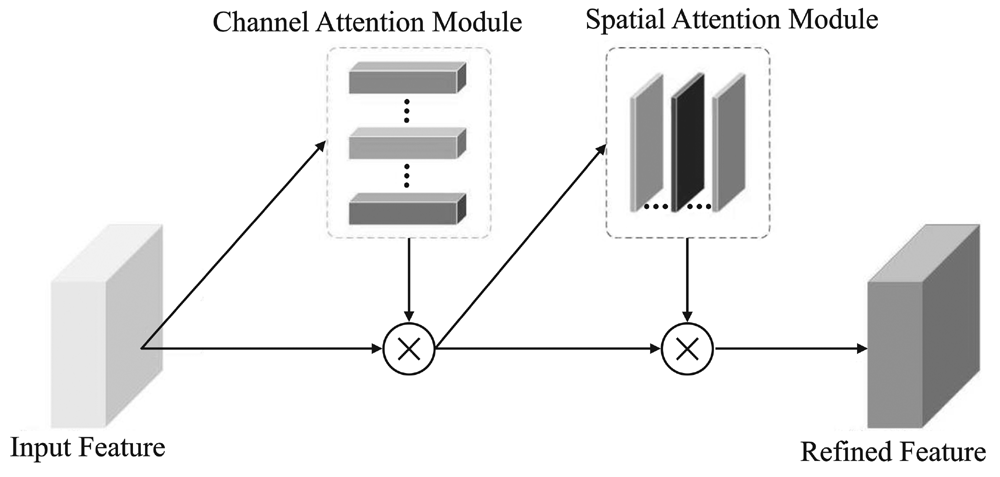
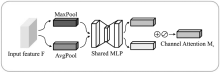
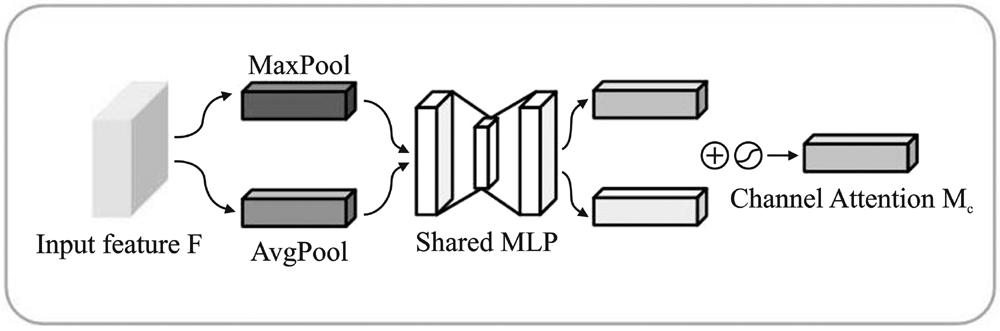
"
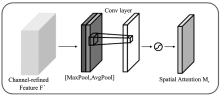
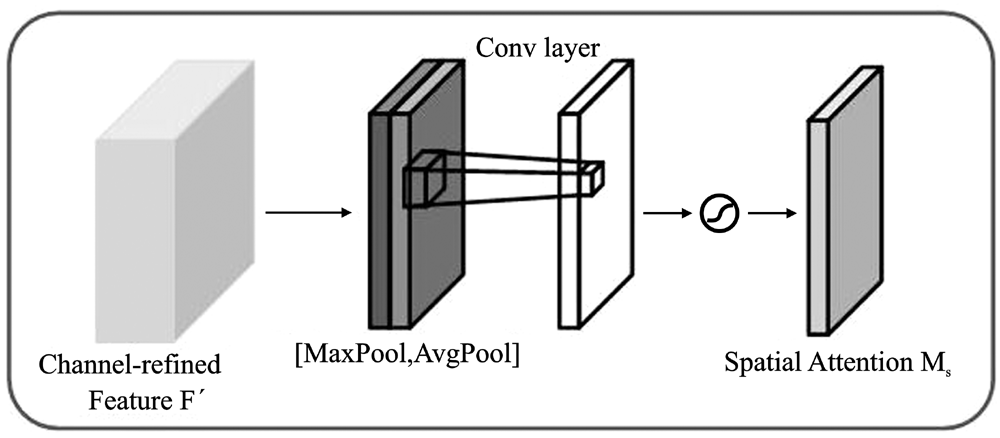
"
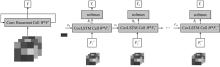
"

"
| 参数 | 设定值 |
|---|---|
| 卷积核的尺寸 | 3×3 |
| 学习率 | 10-3 |
| 权重衰减系数 | 10-5 |
| 丢失率 | 0.9 |
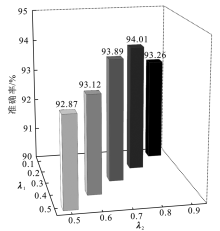
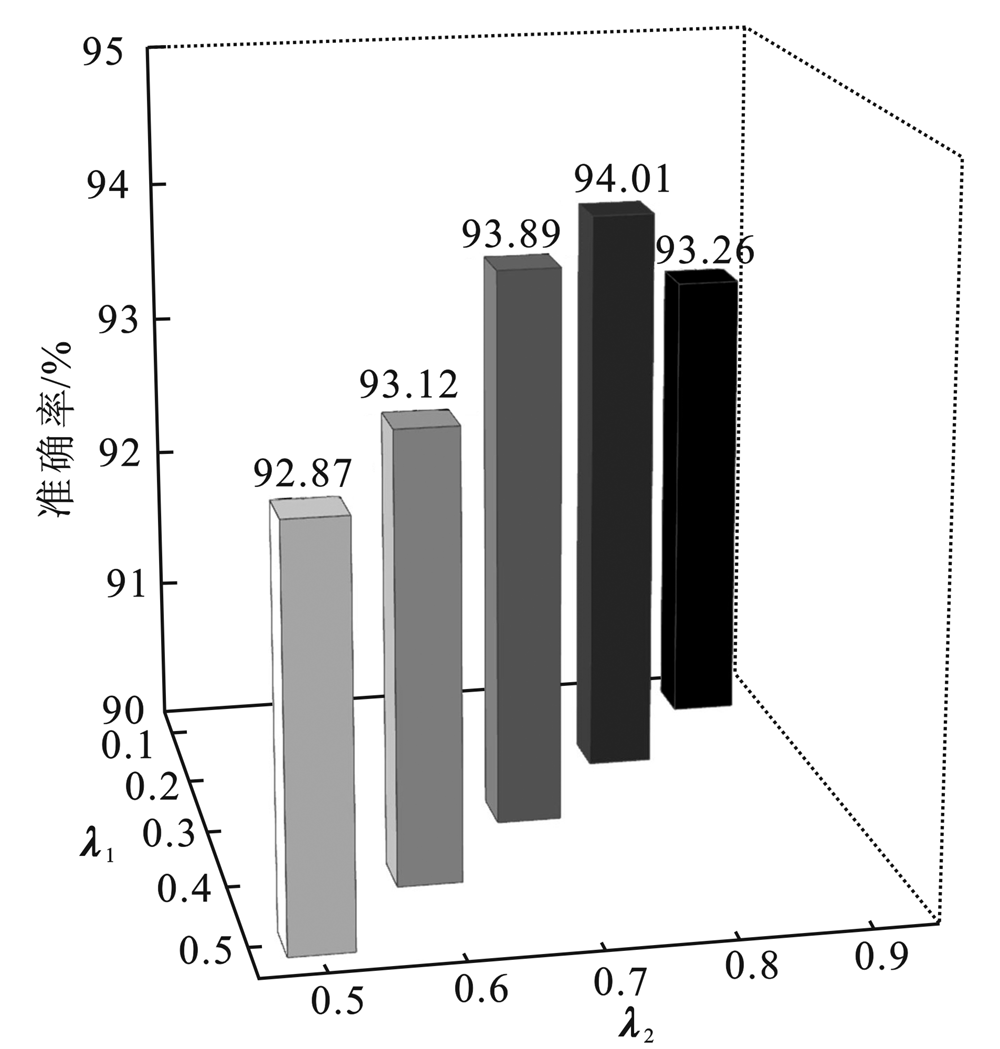
"
"
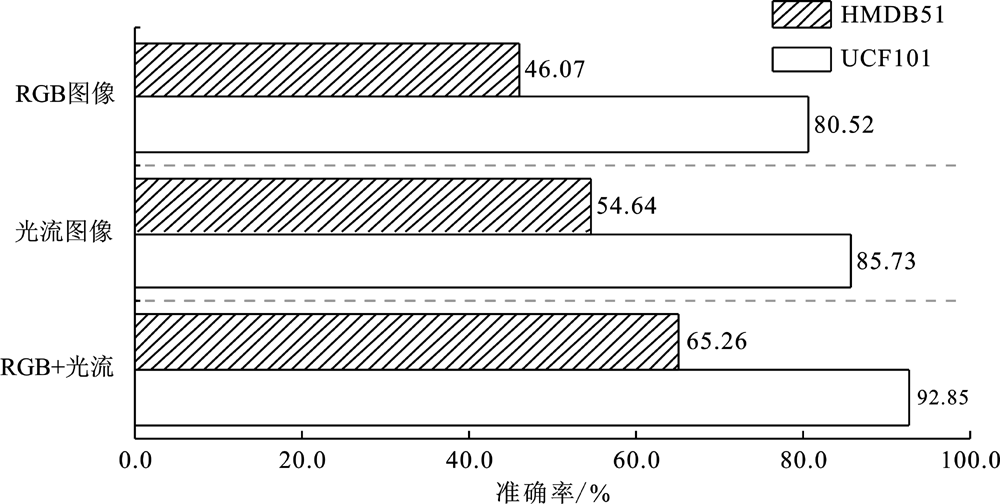
| 模型结构 | YouTube | UCF101 | HMDB51 |
|---|---|---|---|
| 去除注意力机制 | 89.97% | 75.64% | 40.85% |
| 引入注意力机制 | 94.01% | 80.52% | 46.07% |
"
| CNN Model | 精确度/% |
|---|---|
| GoogleNet | 90.2 |
| VGG-16 | 89.6 |
| ResNet-50 | 91.1 |

"
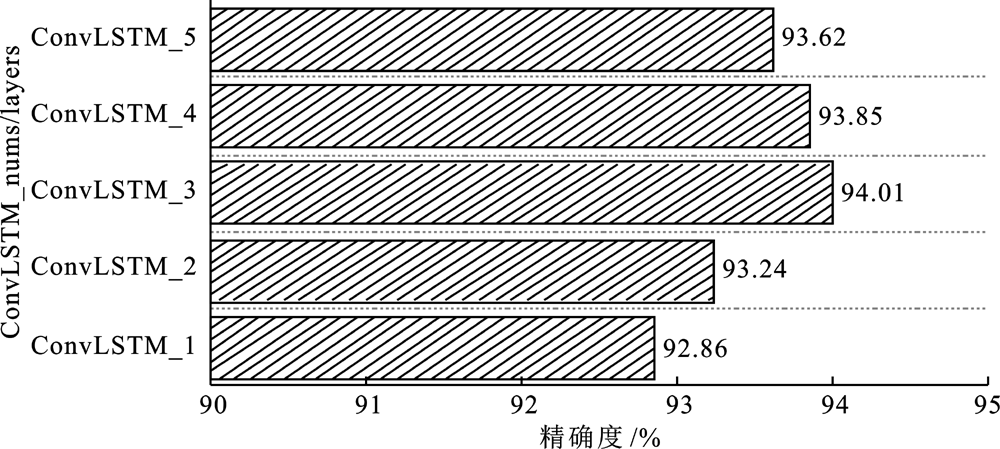
"
"
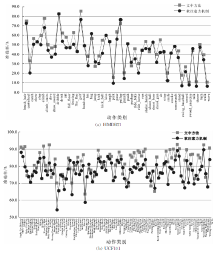
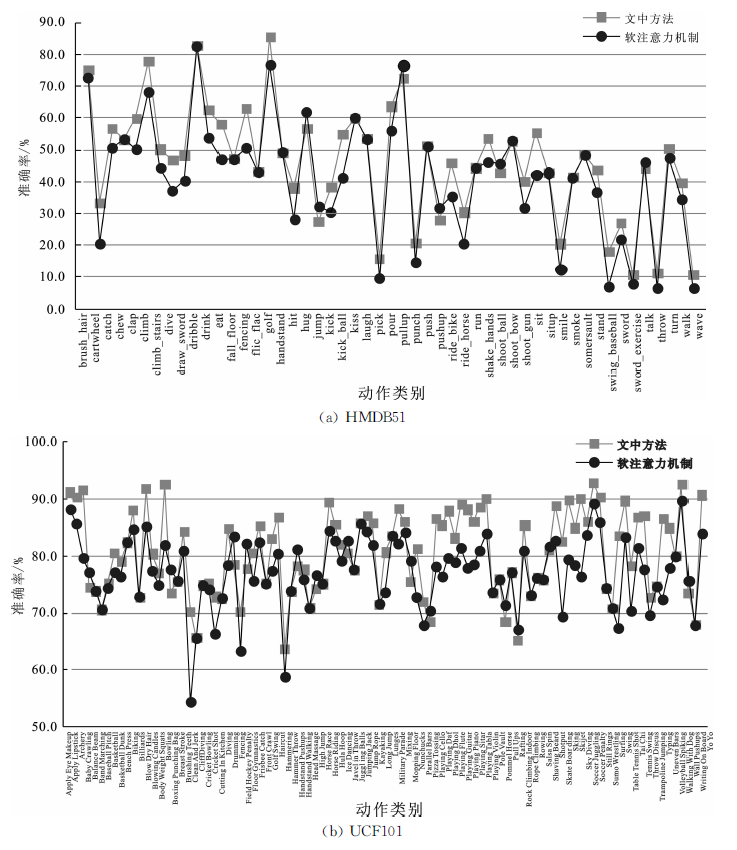
| 动作类别 | HMDB51文中方法 | 软注意力机制 | 动作类别 | UCF101文中方法 | 软注意力机制 |
|---|---|---|---|---|---|
| kick_ball | 54.96 | 41.26 | Surfing | 83.52 | 67.45 |
| it | 55.46 | 42.06 | BrushingTeeth | 70.34 | 54.46 |
| cartwheel | 33.47 | 20.36 | Typing | 86.58 | 72.52 |
| fencing | 63.07 | 50.56 | Skijet | 90.08 | 76.36 |
| eat | 57.98 | 46.98 | Shotput | 82.52 | 69.48 |
| swing_baseball | 18.06 | 7.21 | Archery | 91.55 | 79.72 |
| ride_bike | 45.96 | 35.48 | Bowling | 92.58 | 81.84 |
| hit | 38.08 | 28.08 | SkateBoarding | 89.84 | 79.35 |
| ride_horse | 30.49 | 20.53 | PlayingPiano | 88.23 | 77.92 |
| dive | 46.73 | 37.02 | TennisSwing | 87.13 | 77.59 |
| climb | 77.83 | 68.16 | PlayingDaf | 85.47 | 76.51 |
| clap | 60.00 | 50.37 | Nunchucks | 81.37 | 72.87 |
| drink | 62.46 | 53.64 | PlayingCello | 86.51 | 78.05 |
| golf | 85.54 | 76.73 | PlayingDhol | 87.93 | 79.64 |
| shoot_gun | 40.18 | 31.94 | TableTennisShot | 78.28 | 70.28 |

"
"
| 模型结构 | HMDB51/% | UCF101/% |
|---|---|---|
| CNN+LSTM | 44.13 | 78.39 |
| CNN+ConvLSTM | 46.07 | 80.52 |
"
| 模型结构 | FPS/(帧·秒-1) |
|---|---|
| CNN+LSTM | 16.4 |
| CNN+ConvLSTM | 10.7 |
"
| 算法 | HMDB51 | UCF101 |
|---|---|---|
| LRCN[ | 87.9 | |
| Soft Attention(RGB)[ | 41.3 | 77.0 |
| LTC[ | 64.8 | 91.7 |
| T3D-Transfer[ | 61.1 | 91.7 |
| VideoLSTM[ | 56.4 | 89.2 |
| SOFI+SI[ | 62.5 | 90.3 |
| LSTM spatial transformer[ | 67.1 | 92.8 |
| DKD[ | 64.5 | 92.0 |
| Our Method | 65.3 | 92.8 |

"

| [1] |
HERATH S, HARANDI M, PORIKLI F. Going Deeper into Action Recognition:A Survey[J]. Image and Vision Computing, 2017, 60:4-21.
doi: 10.1016/j.imavis.2017.01.010 |
| [2] | 罗会兰, 童康, 孔繁胜. 基于深度学习的视频中人体动作识别进展综述[J]. 电子学报, 2019, 47(5):1162-1173. |
| LUO Huilan, TONG Kang, KONG Fansheng. The Progress of Human Action Recognition in Videos Based on Deep Learning:A Review[J]. Acta Electronica Sinica, 2019, 47(5):1162-1173. | |
| [3] | KRIZHEVSKYA, SUTSKEVER I, HINTON G, et al. Image Net Classification with Deep Convolutional Neural Networks[J]. Advances in Neural Information Processing Systems, 2012, 25(2):1097-1105. |
| [4] | SIMONYAN K, ZISSERMAN A. Two-Stream Convolutional Networks for Action Recognition in Videos[C]// Advances in Neural Information Processing Systems. San Diego: NIPS, 2014:568-576. |
| [5] | TRAND, BOURDEV L, FERGUS R, et al. Learning Spatiotemporal Features with 3D Convolutional Networks[C]// IEEE International Conference on Computer Vision.Piscataway:IEEE, 2015:4489-4497. |
| [6] | WANGL M, XIONG Y J, WANG Z, et al. Temporal Segment Networks:Towards Good Practices for Deep Action Recognition[C]// European Conference on Computer Vision.Heidelberg:Springer, 2016:20-36. |
| [7] |
DONAHUE J, HENDRICKS L A, ROHRBACH M, et al. Long-Term Recurrent Convolutional Networks for Visual Recognition and Description[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4):677-691.
doi: 10.1109/TPAMI.2016.2599174 |
| [8] | XU K, BA J, KIROS R, et al. Show,Attend and Tell:Neural Image Caption Generation with Visual Attention[C]// In International Conference on Machine Learning. New York: ACM, 2015:2048-2057. |
| [9] | 成磊, 王玥, 田春娜. 一种添加残差注意力机制的视觉目标跟踪算法[J]. 西安电子科技大学学报, 2020, 47(6):148-157. |
| CHENG Lei, WANG Yue, TIAN Chunna. Residual Attention Mechanism for Visual Tracking[J]. Journal of Xidian University, 2020, 47(6):148-157. | |
| [10] | SHARMA S, KIROS R, SALAKHUTDINOV R. Action Recognition Using Visual Attention[C]// Neural Information Processing Systems Time Series Workshop. San Diego: NIPS, 2015:1-6. |
| [11] | DU W, WANG Y, QIAO Y. RPAN:An End-to-End Recurrent Pose-Attention Network for Action Recognition in Videos[C]// IEEE International Conference on Computer Vision.Piscataway:IEEE, 2017:3745-3754. |
| [12] |
GE H W, YAN Z H, YU W H, et al. An Attention Mechanism Based Convolutional LSTM Network for Video Action Recognition[J]. Multimedia Tools and Applications, 2019, 78(14):1-24.
doi: 10.1007/s11042-018-6670-5 |
| [13] | TONG M, LI MY, BAI H, et al. DKD-DAD:A Novel Framework with Discriminative Kinematic Descriptor and Deep Attention-Pooled Descriptor for Action Recognition[J]. Neural Computing and Applications, 2020,5285-5302. |
| [14] | WOO S, PARK J, LEE J Y, et al. CBAM:Convolutional Block Attention Module (2018)[J]. [2018-07-17]. https://arxiv.org/abs/1807.06521. |
| [15] |
LI Z, GAVRILYUK K, GAVVES E, et al. VideoLSTM Convolves,Attends and Flows for Action Recognition[J]. Computer Vision and Image Understanding. 2018, 166:41-50.
doi: 10.1016/j.cviu.2017.10.011 |
| [16] | 王洁然. 基于高低层特征融合与卷积注意力机制的视频动作识别方法研究[D]. 武汉: 华中科技大学, 2019. |
| [17] | HE K M, ZHANG X Y, RENS Q, et al. Deep Residual Learning for Image Recognition[C]// IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2016:770-778. |
| [18] | SHI X, CHEN Z, WANG H, et al. Convolutional LSTM Network:A Machine Learning Approach for Precipitation Nowcasting (2015)[J/OL]. [2015-06-13]. https://arxiv.org/abs/1506.04214. |
| [19] | LIU J, LUO J, SHAH M, et al. Recognizing Realistic Actions From Videos “In the Wild”[C]// IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2009:1996-2003. |
| [20] | SOOMRO K, ZAMIR A R, SHAH M. UCF101:A Dataset of 101 Human Action Classes From Videos in the Wild (2012)[J/OL]. [2012-12-03]. https://arxiv.org/abs/1212.0402. |
| [21] | JHUANG H, GARROTE H, POGGIO E, et al. A Large Video Database for Human Motion Recognition[C]// Proceedings of IEEE International Conference on Computer Vision.Piscataway:IEEE, 2011:2556-2563. |
| [22] | KINGMA D P, BA J. Adam:A Method for Stochastic Optimization (2014)[J]. [2014-12-22]. https://arxiv.org/abs/1412.6980. |
| [23] | NG Y H, HAUSKNECHT M, VIJAYANARASIMHAN S, et al. Beyond Short Snippets:Deep Networks for Video Classification[C]// IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2015:4694-4702. |
| [24] |
VAROL G, LAPTEV I, SCHMID C. Long-Term Temporal Convolutions for Action Recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(6):1510-1517.
doi: 10.1109/TPAMI.2017.2712608 |
| [25] | DIBA A, FAYYAZ M, SHARMAV, et al. Temporal 3D Convnets:New Architecture and Transfer Learning for Video Classification (2017)[J]. [2017-11-22]. https://arxiv.org/abs/1711.08200. |
| [26] | 李庆辉, 李艾华, 王涛. 结合有序光流图和双流卷积网络的行为识别[J]. 光学学报, 2018, 38(6):234-240. |
| LI Qinghui, LI Aihua, WANG Tao, et al. Double-Stream Convolution Networks with Sequential Optical Flow Image for Action Recognition[J]. Acta Optical Sinica, 2018, 38(6):234-240. |
| [1] | LIU Di,GUO Jichang,WANG Yudong,ZHANG Yi. Multi-scale salient object detection network combining an attention mechanism [J]. Journal of Xidian University, 2022, 49(4): 118-126. |
| [2] | MA Sike,ZHAO Meng,SHI Fan,SUN Xuguo,CHEN Shengyong. Attention driven nuclei segmentation method for cell clusters [J]. Journal of Xidian University, 2022, 49(2): 198-206. |
| [3] | YANG Jun,WANG Xingxing,LU Youpeng. Shape correspondence calculation using the unsupervised siamese functional maps network [J]. Journal of Xidian University, 2022, 49(1): 225-235. |
| [4] | DONG Ruchan,JIAO Licheng,ZHAO Jin,SHEN Weiyan. Application of the deep fusion mechanism in object detection of remote sensing images [J]. Journal of Xidian University, 2021, 48(5): 128-138. |
| [5] | CHENG Lei,WANG Yue,TIAN Chunna. Residual attention mechanism for visual tracking [J]. Journal of Xidian University, 2020, 47(6): 148-157. |
| [6] | DU Lizhao,XU Yan,ZHANG Wei. Phased smoke detection algorithm using dual network fusion [J]. Journal of Xidian University, 2020, 47(4): 141-148. |
| [7] | ZHANG Zhiyuan,DIAO Yinghua. Pedestrian trajectory prediction model with social features and attention [J]. Journal of Xidian University, 2020, 47(1): 10-17. |
| [8] | WANG Ziyi,SU Yuting,LIU Yanyan,ZHANG Wei. Algorithm for segmentation of smoke using the improved DeeplabV3 network [J]. Journal of Xidian University, 2019, 46(6): 52-59. |
| [9] | CAO Weidong,LI Jiaqi,WANG Huaichao. Analysis of targeted sentiment by the attention gated convolutional network model [J]. Journal of Xidian University, 2019, 46(6): 30-36. |
| [10] | WANG Lulu,ZHANG Wei,SUN Qilong. Indoor human detection algorithm based on the improved retinaNet [J]. Journal of Xidian University, 2019, 46(5): 69-74. |
| [11] | CHEN Xiaofan,SHEN Haijie,BIAN Qian,WANG Zhenduo,TIAN Xinzhi. Face image super-resolution with an attention mechanism [J]. Journal of Xidian University, 2019, 46(3): 148-153. |
| [12] | MA Shulei,ZHANG Guobin,JIAO Yang,SHI Guangming. Improved method for image caption with global attention mechanism [J]. Journal of Xidian University, 2019, 46(2): 17-22. |
| [13] | CHEN Bing;ZHAO Yigong;LI Xin. Wide baseline image matching based on a new local descriptor [J]. J4, 2011, 38(2): 116-123. |
|