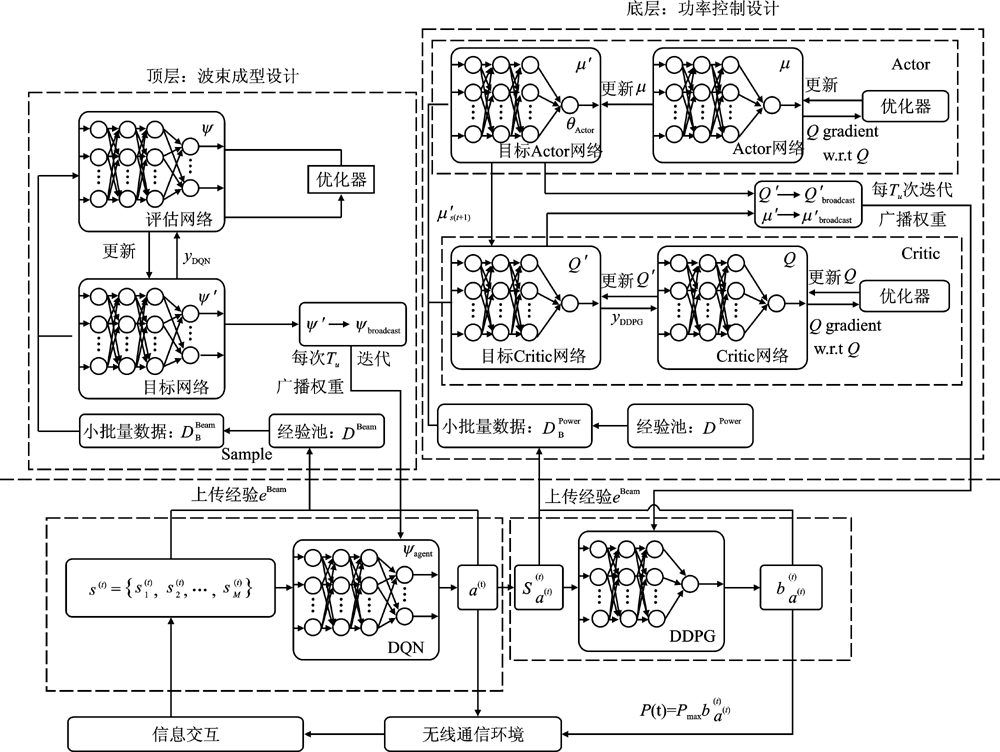
| [1] |
ZHANG N, WANG J, KANG G, et al. Uplink Nonorthogonal Multiple Access in 5G Systems[J]. I IEEE Communications Letters, 2016, 20 (3):458-461.
|
| [2] |
DING Z, FAN P, POOR H V. Random Beamforming in Millimeterwave NOMA Networks[J]. IEEE Access, 2017, 5:7667-7681.
doi: 10.1109/ACCESS.2017.2673248
|
| [3] |
HAN S, CHIH-LIN I, XIE T, et al. Achieving High Spectrum Efficiency on High Speed Train for 5G New Radio and Beyond[J]. IEEE Wireless Communications, 2019, 26(5):62-69.
|
| [4] |
谢垚, 黄默, 王长元, 等. 一种改进的宽波束线阵雷达物位测量算法[J]. 西安电子科技大学学报, 2021, 48(2):165-172.
|
|
XIE Yao, HUANG Mo, WANG Changyuan, et al. Improved Algorithm for Wide Beam Linear Array Radar Level Meter Measurement[J]. Journal of Xidian University, 2021, 48(2):165-172.
|
| [5] |
SHEN K, YU W. Fractional Programming for Communication Systems-Part I:Power Control and Beamforming[J]. IEEE Transactions on Signal Processing, 2018, 66(10):2616-2630.
doi: 10.1109/TSP.2018.2812733
|
| [6] |
SHI Q, RAZAVIYAYN M, LUO Z Q, et al. An Iteratively Weighted MMSE Approach to Distributed Sum-utility Maximization for a MIMO Interfering Broadcast Channel[J]. IEEE Transactions on Signal Processing, 2011, 59(9):4331-4340.
doi: 10.1109/TSP.2011.2147784
|
| [7] |
NASIRY S, GUO D. Multi-Agent Deep Reinforcement Learning for Dynamic Power Allocation in Wireless Networks[J]. IEEE Journal on Selected Areas in Communications, 2019, 37(10):2239-2250.
doi: 10.1109/JSAC.2019.2933973
|
| [8] |
YE H, LI G Y, JUANG B H F. Deep Reinforcement Learning Based Resource Allocation for V2V Communications[J]. IEEE Transactions on Vehicular Technology, 2019, 68(4):3163-3173.
doi: 10.1109/TVT.2019.2897134
|
| [9] |
LEE C, KIM Y H. Receive Beamforming and Resource Allocation for Wireless Powered Non-Orthogonal Multiple Access[J]. IEEE Transactions on Vehicular Technology, 2020, 69(4):4563-4568.
doi: 10.1109/TVT.2020.2976887
|
| [10] |
XIAO Z, ZHU L, CHOI J, et al. Joint Power Allocation and Beamforming for Non-Orthogonal Multiple Access (NOMA) in 5G Millimeter Wave Communications[J]. IEEE Transactions on Wireless Communications, 2018, 17(5):2961-2974.
doi: 10.1109/TWC.2018.2804953
|
| [11] |
XU J, AI B, CHEN L. Joint Beamforming and Power Allocation in Millimeter-Wave High-Speed Railway Systems[C]// Proceedings of the 2020 IEEE Global Communications Conference.Piscataway:IEEE, 2020:1-6.
|
| [12] |
LILLICRAPT P, HUNT J J, PRITZEL A, et al. Continuous Control with Deep Reinforcement Learning[J]. Computer Science, 2015, 8(6):A187.
|
| [13] |
MISMANF B, EVANS B L, ALKHATEEB A. Deep Reinforcement Learning for 5G Networks:Joint Beamforming,Power Control,and Interference Coordination[J]. IEEE Transactions on Communications, 2020, 66(3):1581-1592.
|
| [14] |
GE J, LIANG Y C, JOUNG J, et al. Deep Reinforcement Learning for Distributed Dynamic MISO Downlink-Beamforming Coordination[J]. IEEE Transactions on Communications, 2020, 68(10):6070-6085.
doi: 10.1109/TCOMM.2020.3004524
|
| [15] |
DONG M, TONG L, SADLER B M. Optimal Insertion of Pilot Symbols for Transmissions over Time-Varying Flat Fading Channels[J]. IEEE Transactions on Signal Processing, 2004, 52(5):1403-1418.
doi: 10.1109/TSP.2004.826182
|
| [16] |
ARULKUMARAN K, DEISENROTH M P, BRUNDAGE M, et al. Deep Reinforcement Learning:A Brief Survey[J]. IEEE Signal Processing Magazine, 2017, 34(6):26-38.
doi: 10.1109/MSP.2017.2743240
|
| [17] |
ZOU W, CUI Z, LI B, et al. Beamforming Codebook Design and Performance Evaluation for 60GHz Wireless Communication[C]// 2011 11th International Symposium on Communications & Information Technologies.Piscataway:ISCIT, 2011:30-35.
|
| [18] |
ZHUANG B, GUO D, HONIG M L. Energy-efficient Cell Activation,User Association,and Spectrum Allocation in Heterogeneous Networks[J]. IEEE Journal on Selected Areas in Communications, 2016, 34(4):823-831.
doi: 10.1109/JSAC.2016.2544478
|
| [19] |
CYBENKO G. Approximation by Superpositions of a Sigmoidal Function[J]. Mathematics of Control,Signals and Systems, 1989, 2(4):303-314.
doi: 10.1007/BF02551274
|
 ),GAO Wei1,2(
),GAO Wei1,2(