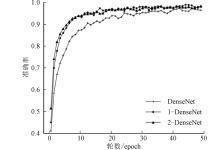
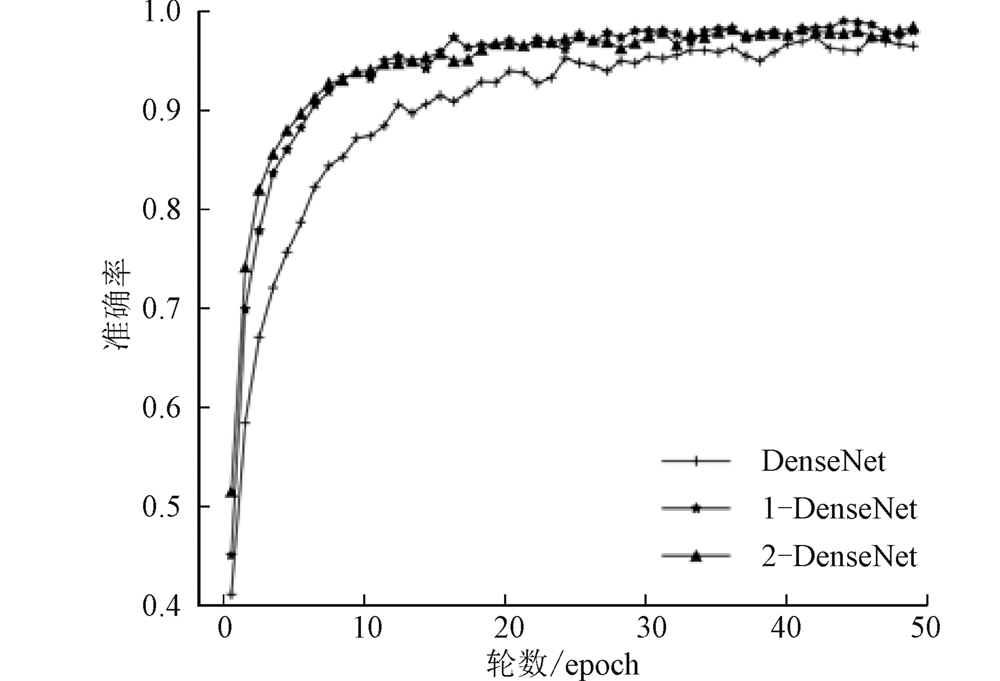
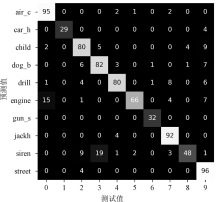
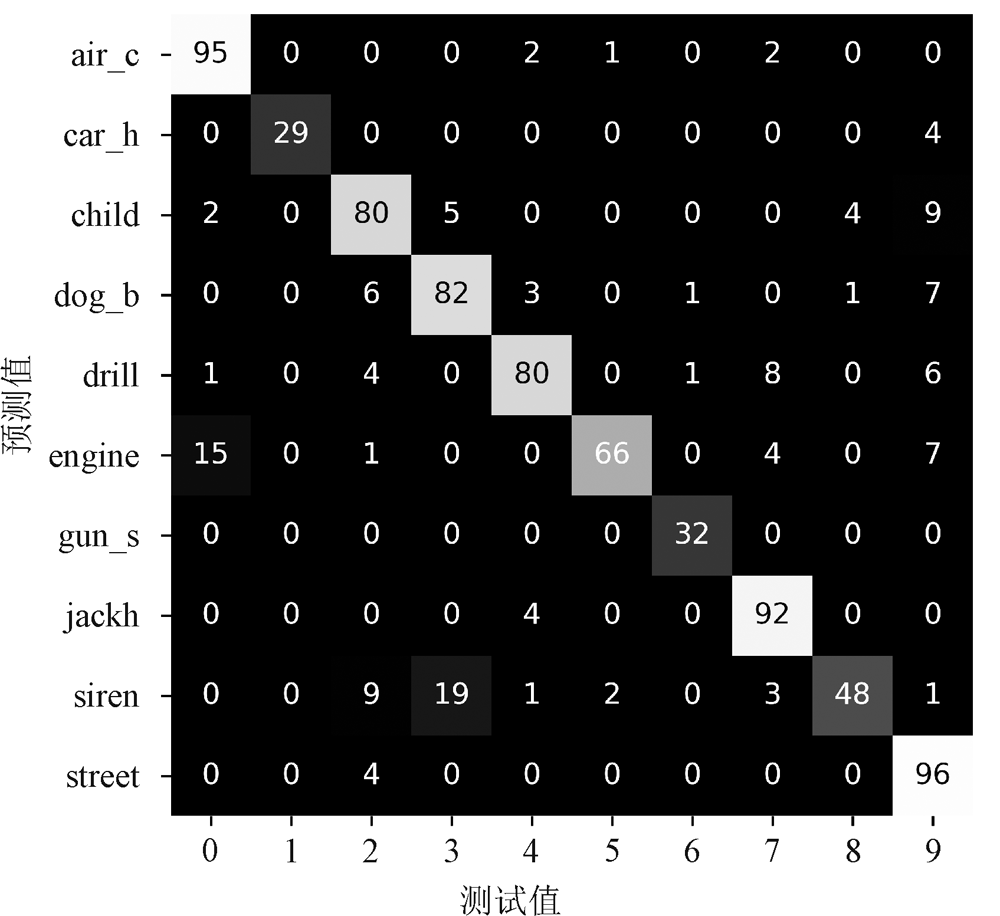
| [1] |
BOGDANOV D, WACK N, GOMEZ E , et al. An Open-source Library for Sound and Music Analysis[C]//Proceedings of the 2013 ACM Multimedia Conference. New York: ACM, 2013: 855-858.
|
| [2] |
王瑞, 王康晏, 冯玉田 , 等. 复杂场景下声频传感器网络核稀疏表示车辆识别[J]. 西安电子科技大学学报, 2015,42(4):114-120.
|
|
WANG Rui, WANG Kangyan, FENG Yutian , et al. Vehicle Recognition Using Acoustic Sensor Networks in Complex Scenes via Kernel Sparse Representation[J]. Journal of Xidian University, 2015,42(4):114-120.
|
| [3] |
DUBOIS D, GUASTAVINO C, MAFFIOLO V , et al. A Cognitive Approach to Soundscape Research[J]. Journal of the Acoustical Society of America, 2004,115(5):2495.
doi: 10.1080/00140139.2013.835873
pmid: 24073684
|
| [4] |
HUSSEIN R, SHABAN K B, EL-HAG A H . Robust Feature Extraction and Classification of Acoustic Partial Discharge Signals Corrupted with Noise[J]. IEEE Transactions on Instrumentation and Measurement, 2017,66(3):405-413.
doi: 10.1109/TIM.2016.2639678
|
| [5] |
郭晶晶, 马建峰 . 面向虚拟社区物联网的信任推荐算法[J]. 西安电子科技大学学报, 2015,42(2):52-57.
doi: 10.3969/j.issn.1001-2400.2015.02.009
|
|
GUO Jingjing, MA Jianfeng . Trust Recommendation Algorithm for the Virtual Community Based Internet of Things(IoT)[J]. Journal of Xidian University, 2015,42(2):52-57.
doi: 10.3969/j.issn.1001-2400.2015.02.009
|
| [6] |
王静远, 李超, 熊璋 , 等. 以数据为中心的智慧城市研究综述[J]. 计算机研究与发展, 2014,51(2):239-259.
|
|
WANG Jingyuan, LI Chao, XIONG Zhang , et al. Survey of Data-centric Smart City[J]. Journal of Computer Research and Development, 2014,51(2):239-259.
|
| [7] |
SALAMON J, JACOBY C, BELLO J P . A Dataset and Taxonomy for Urban Sound Research[C]//Proceedings of the 2014 ACM Conference on Multimedia. New York: ACM, 2014: 1041-1044.
|
| [8] |
YE J X, KOBAYASHI T, MURAKAWA M . Urban Sound Event Classification Based on Local & Global Features Aggregation[J]. Applied Acoustics, 2017,117:246-256.
doi: 10.1016/j.apacoust.2016.08.002
|
| [9] |
KONS Z, TOLEDO-RONEN O . Audio Event Classification Using Deep Neural Networks[C]//Proceedings of the 2013 Annual Conference of the International Speech Communication Association. Baixas: International Speech Communication Association, 2013: 1482-1486.
|
| [10] |
LIM M, LEE D, PARK H , et al. Convolutional Neural Network Based Audio Event Classification[J]. KSII Transactions on Internet and Information Systems, 2018,12(6):2748-2760.
doi: 10.1371/journal.pone.0214168
pmid: 31647815
|
| [11] |
CHEN Y, GUO Q, LIANG X Y , et al. Environmental Sound Classification with Dilated Convolutions[J]. Applied Acoustics , 2019,148:123-132.
doi: 10.1016/j.apacoust.2018.12.019
|
| [12] |
ZHANG X H, ZOU Y X, SHI W . Dilated Convolution Neural Network with Leaky ReLU for Environmental Sound Classification[C]//Proceedings of the 2017 International Conference on Digital Signal Processing. Piscataway: IEEE, 2017: 8096153.
|
| [13] |
HUANG G, LIU Z, VAN DER MAATEN L , et al. Densely Connected Convolutional Networks[C]//Proceedings of the 2017 30th IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 2261-2269.
|
| [14] |
吴仁彪, 赵婷, 屈景怡 . 基于深度SE-DenseNet的航班延误预测模型[J]. 电子与信息学报, 2019,41(6):1510-1517.
doi: 10.1021/acsnano.9b07956
pmid: 31869204
|
|
WU Renbiao, ZHAO Ting, QU Jingyi . Flight Delay Prediction Model Based on Deep SE-DenseNet[J]. Journal of Electronics & Information Technology, 2019,41(6):1510-1517.
doi: 10.1021/acsnano.9b07956
pmid: 31869204
|
| [15] |
JOAKIM M, JOAKIM W . An N-state Markov-chain Mixture Distribution Model of the Clear-sky Index[J]. Solar Energy, 2018,173(1):487-495.
doi: 10.1016/j.solener.2018.07.056
|
| [16] |
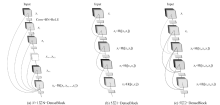
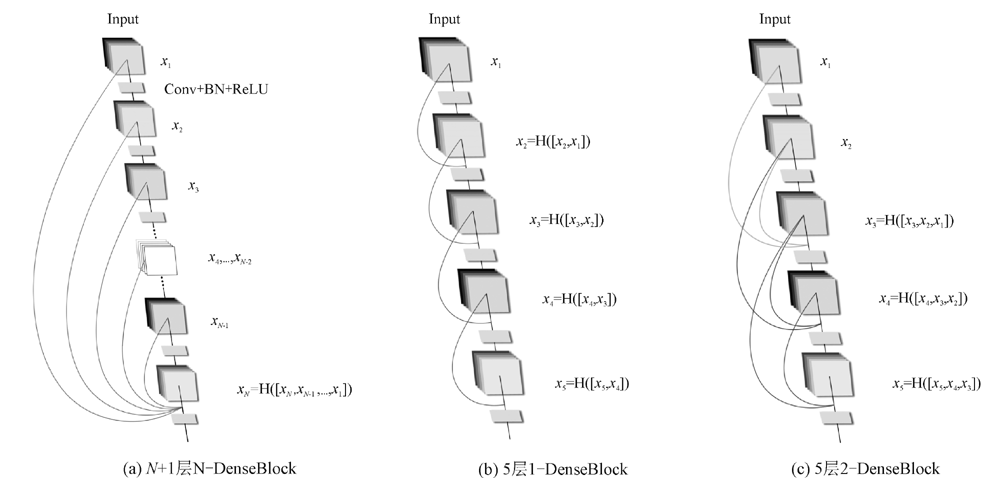
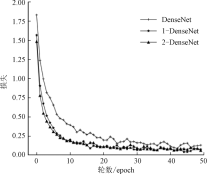
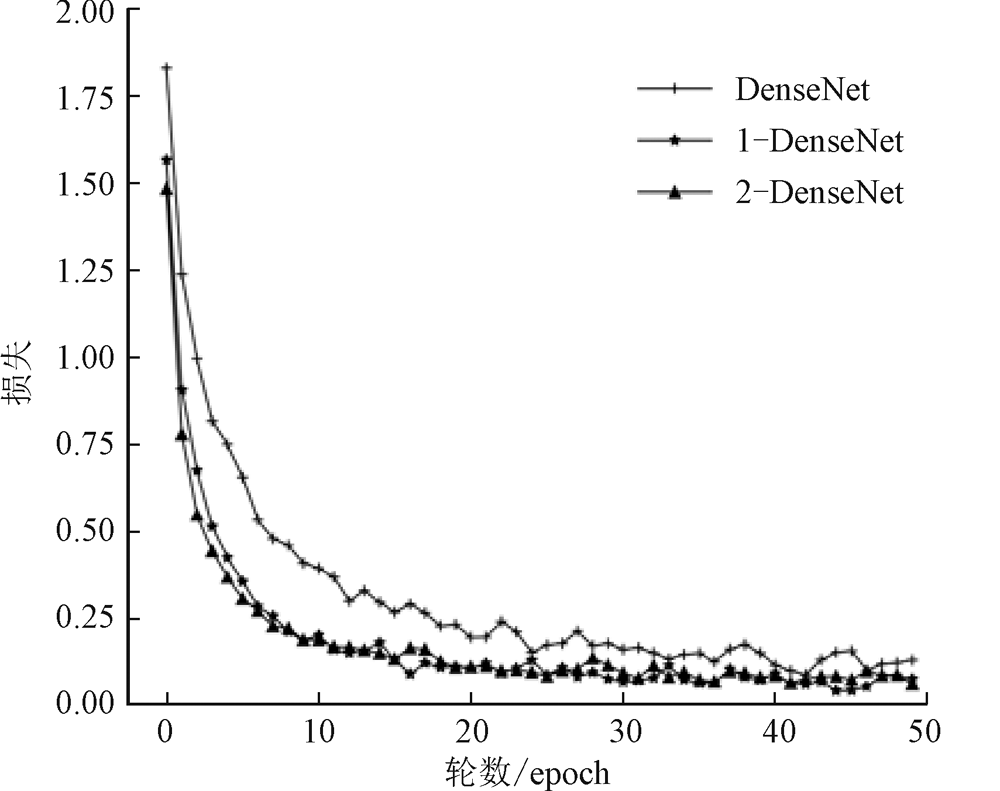
曹毅, 黄子龙, 张威 , 等. 基于N-DenseNet和高维mfcc特征的城市声音事件分类方法: CN109949824A [P]. 2019-06-28.
|
| [17] |
MESAROS A, HEITTOLA T, VIRTANEN T . TUT Database for Acoustic Scene Classification and Sound Event Detection[C]//Proceedings of the 2016 European Signal Processing Conference. Poland: European Signal Processing Conference, 2016: 1128-1132.
|
| [18] |
李东, 张雪英, 段淑斐 , 等. 结合语音融合特征和随机森林的构音障碍识别[J]. 西安电子科技大学学报, 2018,45(3):149-155.
|
|
LI Dong, ZHANG Xueying, DUAN Shufei , et al. Dysarthria Recognition Combining Speech Fusion Feature and Random Forest[J]. Journal of Xidian University, 2018,45(3):149-155.
|
| [19] |
仲伟峰, 方祥, 范存航 , 等. 深浅层特征及模型融合的说话人识别[J]. 声学学报, 2018,43(2):60-70.
|
|
ZHONG Weifeng, FANG Xiang, FAN Cunhang , et al. Fusion of Deep Shallow Feature and Models for Speaker Recognition[J]. Acta Acustica, 2018,43(2):60-70.
|