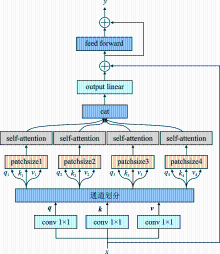
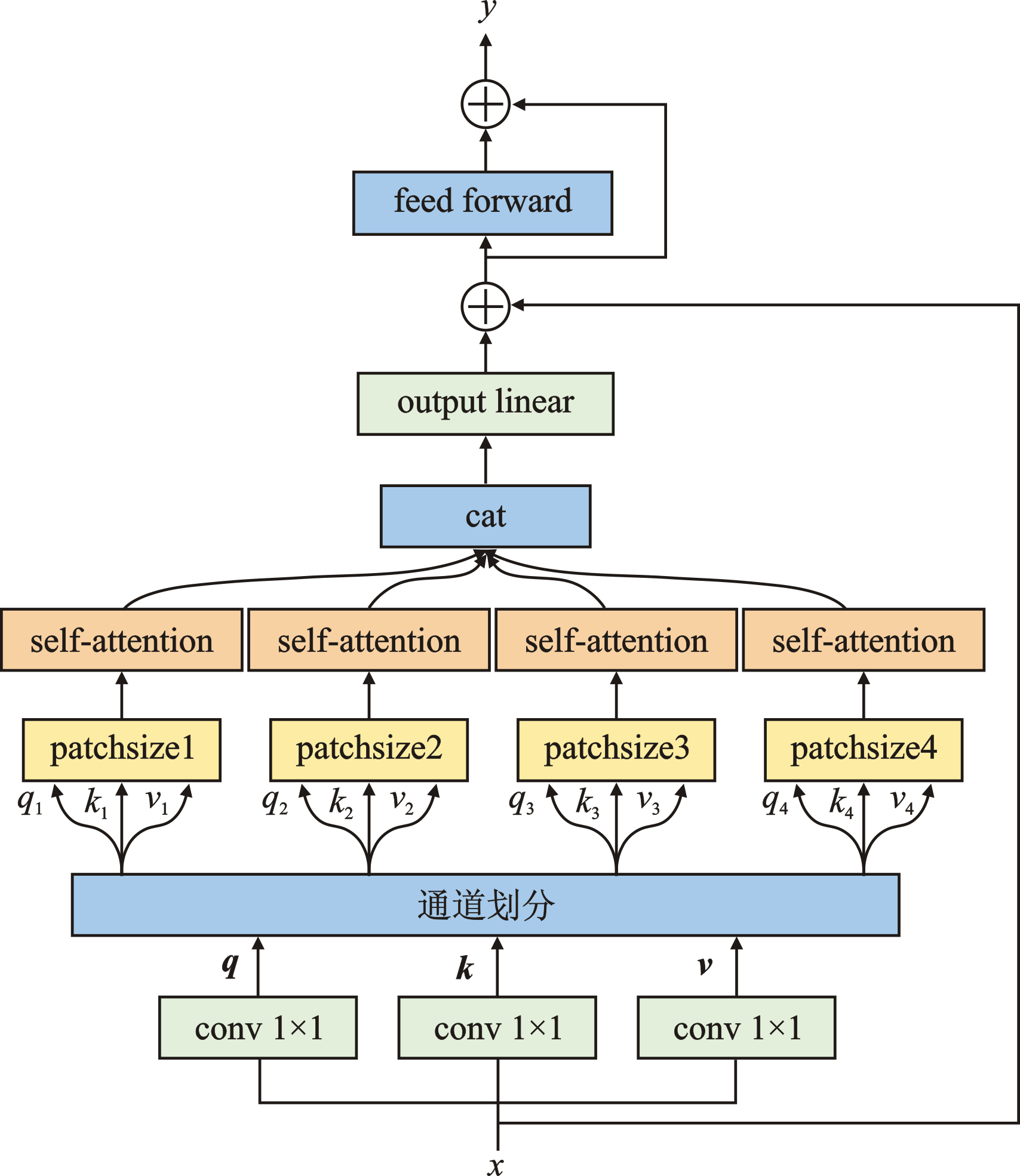
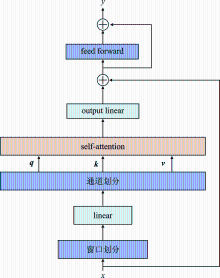
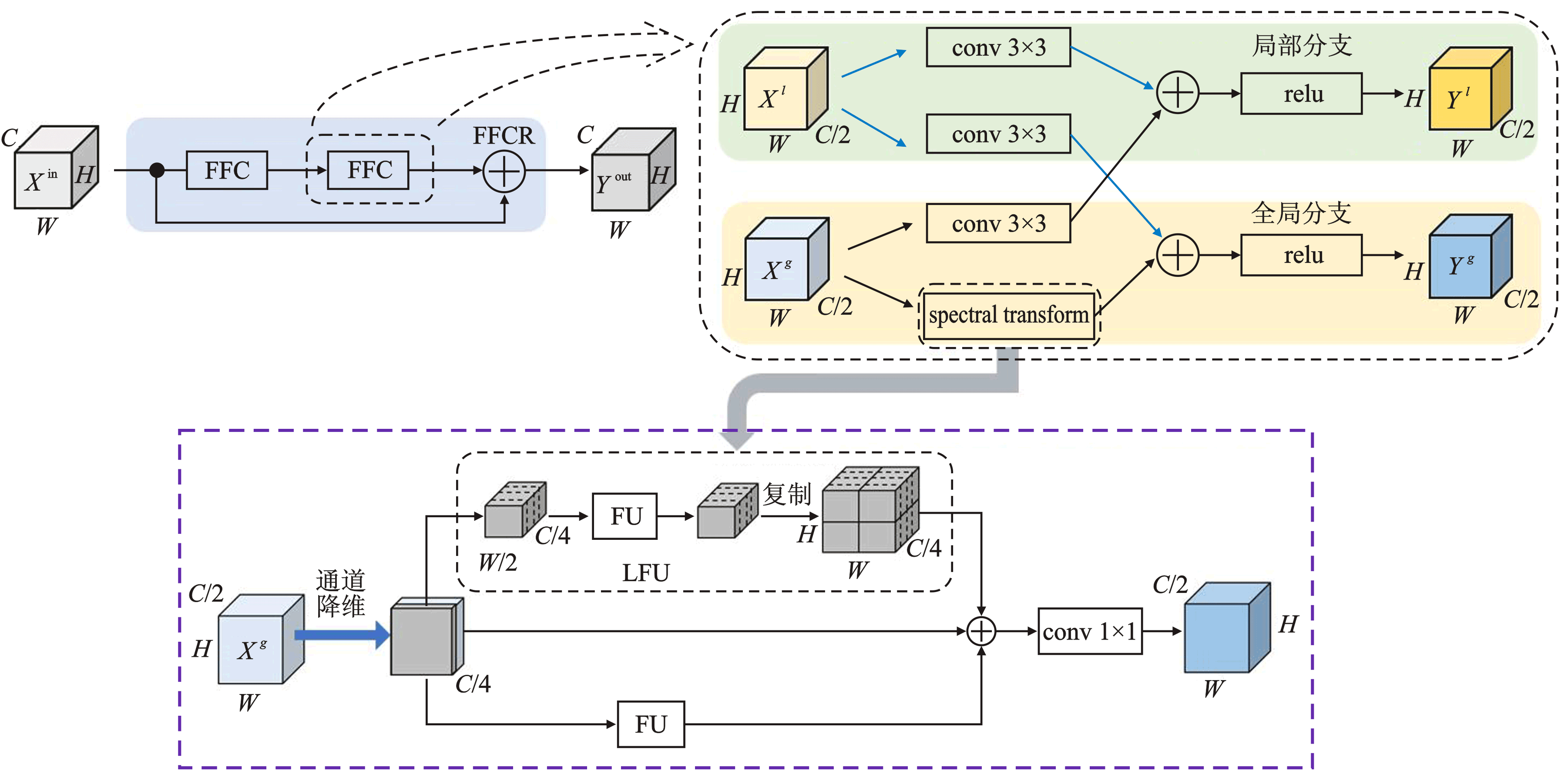
| [1] |
CHAVAN S A, CHOUDHARI N M. Various Approaches for Video Inpainting:A Survey[C]//2019 5th International Conference on Computing,Communication,Control and Automation.Piscataway:IEEE, 2019:1-5.
|
| [2] |
潘浩. 数字视频的修复方法研究[D]. 合肥: 中国科学技术大学, 2010.
|
| [3] |
ZHANG X, LI H, QI Y, et al. Rain Removal in Video by Combining Temporal and Chromatic Properties[C]//IEEE International Conference on Multimedia and Expo. Piscataway:IEEE, 2006:461-464.
|
| [4] |
HUANG Y, ZHENG F, WANG D, et al. Super-Resolution and Inpainting with Degraded and Upgraded Generative Adversarial Networks[C]//Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence. New York: ACM, 2021:645-651.
|
| [5] |
韦哲, 李从利, 沈延安, 等. 基于两阶段模型的无人机图像厚云区域内容生成[J]. 计算机学报, 2021, 44(11):2233-2247.
|
|
WEI Zhe, LI Congli, SHENG Yan’an, et al. Thick Cloud Region Content Generation of UAV Image Based on Two-Stage Model[J]. Chinese Journal of Computers, 2021, 44(11):2233-2247.
|
| [6] |
TRAN D, BOURDEV L, FERGUS R, et al. Learning Spatiotemporal Features with 3D Convolutional Networks[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway:IEEE, 2015:4489-4497.
|
| [7] |
CHANG Y L, LIU Z Y, LEE K Y, et al. Free-form Video Inpainting with 3D Gated Convolution and Temporal PatchGAN[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway:IEEE, 2019:9066-9075.
|
| [8] |
KIM D, WOO S, LEE J Y, et al. Deep Video Inpainting[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE, 2019:5792-5801.
|
| [9] |
HU Y T, WANG H, BALLAS N, et al. Proposal-Based Video Completion[C]//Proceedings of the European Conference on Computer Vision. Piscataway:IEEE, 2020:38-54.
|
| [10] |
XU R, LI X, ZHOU B, et al. Deep Flow-Guided Video Inpainting[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE, 2019:3723-3732.
|
| [11] |
GAO C, SARAF A, HUANG J B, et al. Flow-Edge Guided Video Completion[C]//Proceedings of the European Conference on Computer Vision. Piscataway:IEEE, 2020:713-729.
|
| [12] |
LEE S, OH S W, WON D Y, et al. Copy-and-Paste Networks for Deep Video Inpainting[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway:IEEE, 2019:4413-4421.
|
| [13] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is All You Need[J]. Advances in Neural Information Processing Systems, 2017, 30:5998-6008.
|
| [14] |
ZENG Y, FU J, CHAO H. Learning Joint Spatial-Temporal Transformations for Video Inpainting[C]//Proceedings of the European Conference on Computer Vision. Piscataway:IEEE, 2020:528-543.
|
| [15] |
LIU R, DENG H, HUANG Y, et al. FuseFormer:Fusing Fine-Grained Information in Transformers for Video Inpainting[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway:IEEE, 2021:14040-14049.
|
| [16] |
TANCIK M, SRINIVASAN P, MILDENHALL B, et al. Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains[J]. Advances in Neural Information Processing Systems, 2020, 33:7537-7547.
|
| [17] |
ZHANG R, ISOLA P, EFROS A A, et al. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE, 2018:586-595.
|
| [18] |
SIMONYAN K, ZISSERMAN A. Very Deep Convolutional Networks for Large-Scale Image Recognition(2014)[J/OL].[2014-09-04].https://arxiv.org/pdf/1409.1556.pdf.
|
| [19] |
SUVOROV R, LOGACHEVA E, MASHIKHIN A, et al. Resolution-Robust Large Mask Inpainting with Fourier Convolutions[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway:IEEE, 2022:2149-2159.
|
| [20] |
GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative Adversarial Nets[J]. Advances in Neural Information Processing Systems, 2014, 27:2672-2680.
|
| [21] |
WANG C, HUANG H, HAN X, et al. Video Inpainting by Jointly Learning Temporal Structure and Spatial Details[C]//Proceedings of the AAAI Conference on Artificial Intellingence. Menlo Park: AAAI, 2019, 33(1):5232-5239.
|
| [22] |
KINGMA D P, BA J. Adam:A Method for Stochastic Optimization[C]//Proceedings of the 3rd International Conference on Learning Representations. Piscataway: San Digeo, 2015,1-13.
|
| [23] |
XU N, YANG L, FAN Y, et al. Youtube-Vos:A Large-Scale Video Object Segmentation Benchmark(2018)[J/OL].[2018-09-06].https://arxiv.org/pdf/1809.03327.pdf.
|
| [24] |
CAELLES S, MONTES A, MANINIS K K, et al. The 2018 Davis Challenge on Video Object Segmentation(2018)[J/OL].[2018-03-01].https://arxiv.org/pdf/1803.00557.pdf.
|
| [25] |
杨静雅, 齐彦丽, 周一青, 等. CNN-Transformer轻量级智能调制识别算法[J]. 西安电子科技大学学报, 2023, 50(3):40-49.
|
|
YANG Jingya, QI Yanli, ZHOU Yiqing, et al. Algorithm for Recognition of Lightweight Intelligent Modulation Based on the CNN-Transformer Networks[J]. Journal of Xidian University, 2023, 50(3):40-49.
|
 ), WANG Xiumei1(
), WANG Xiumei1(