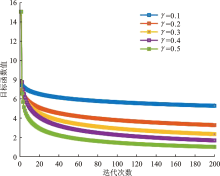
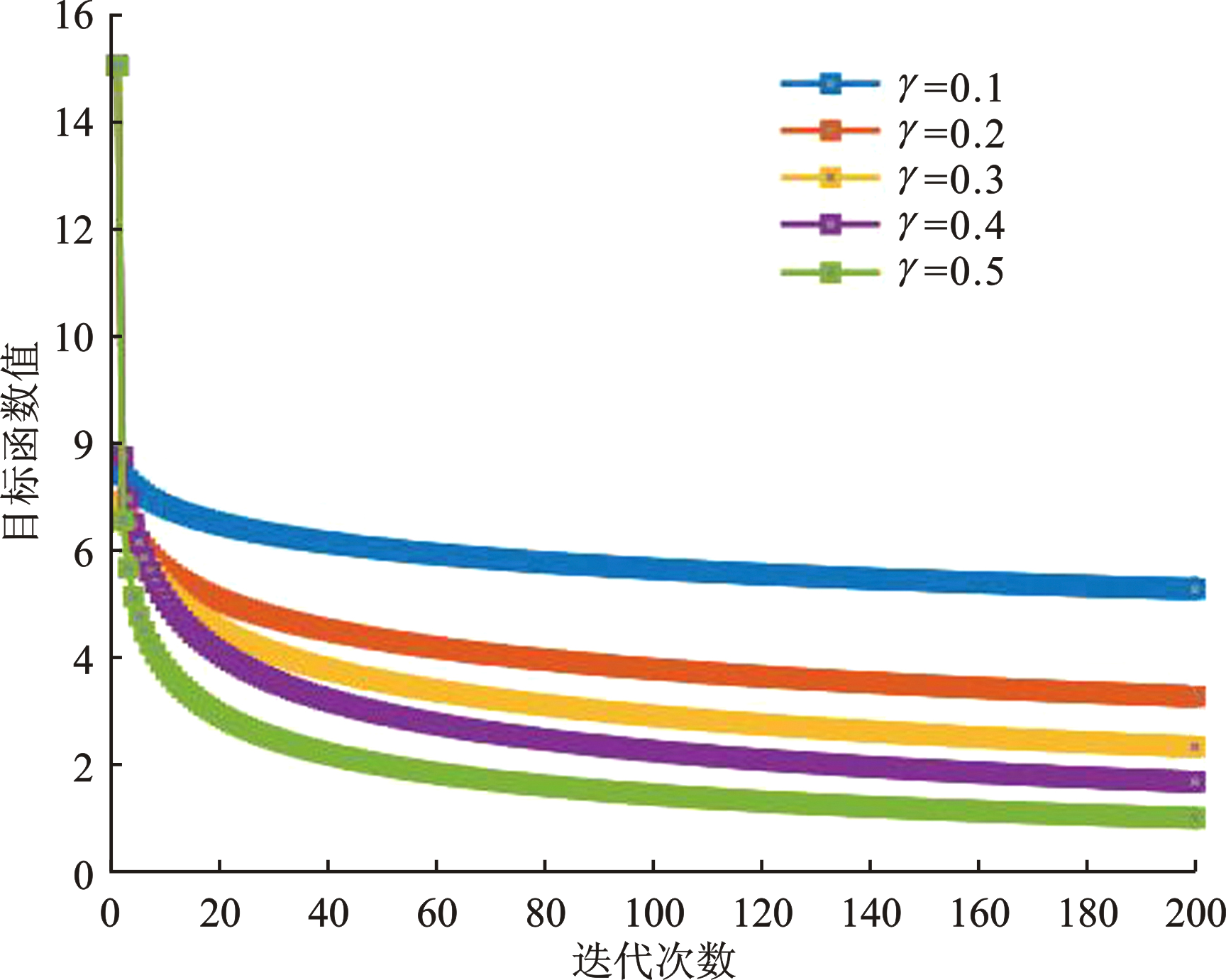
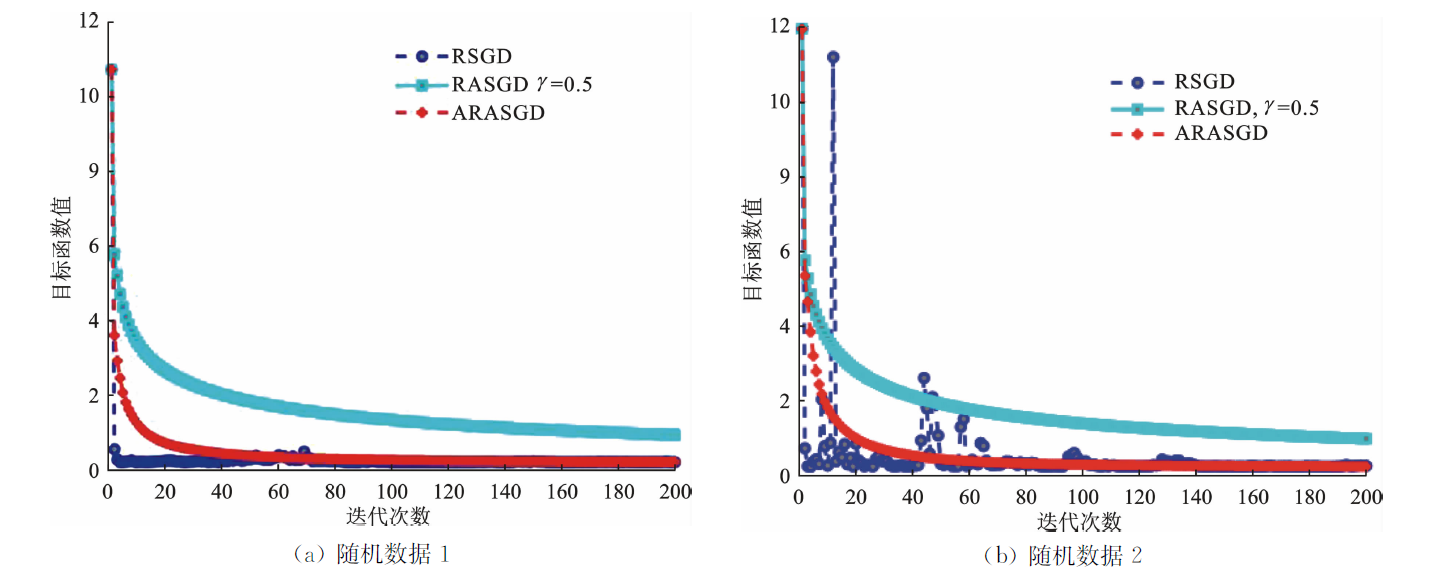
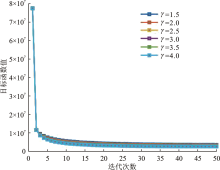
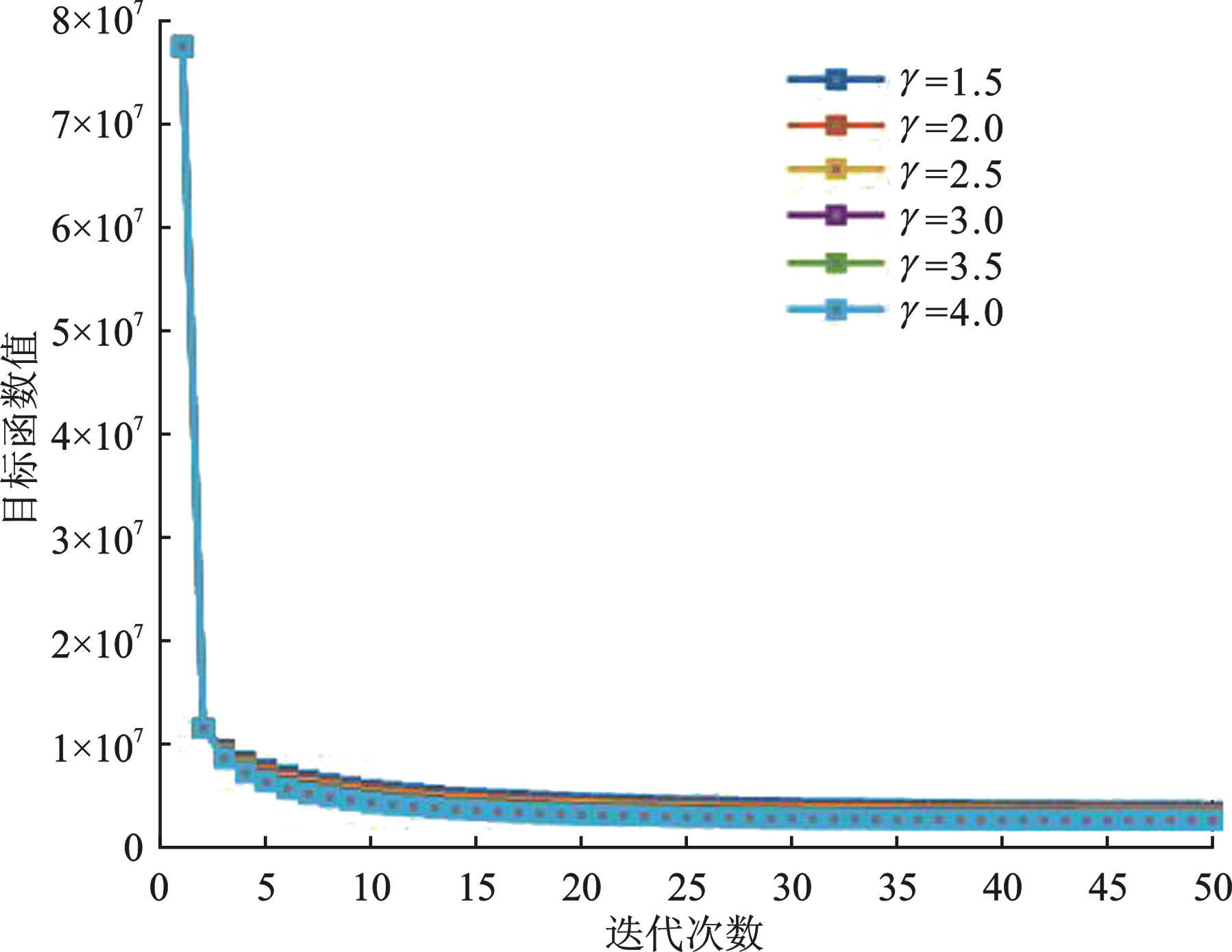
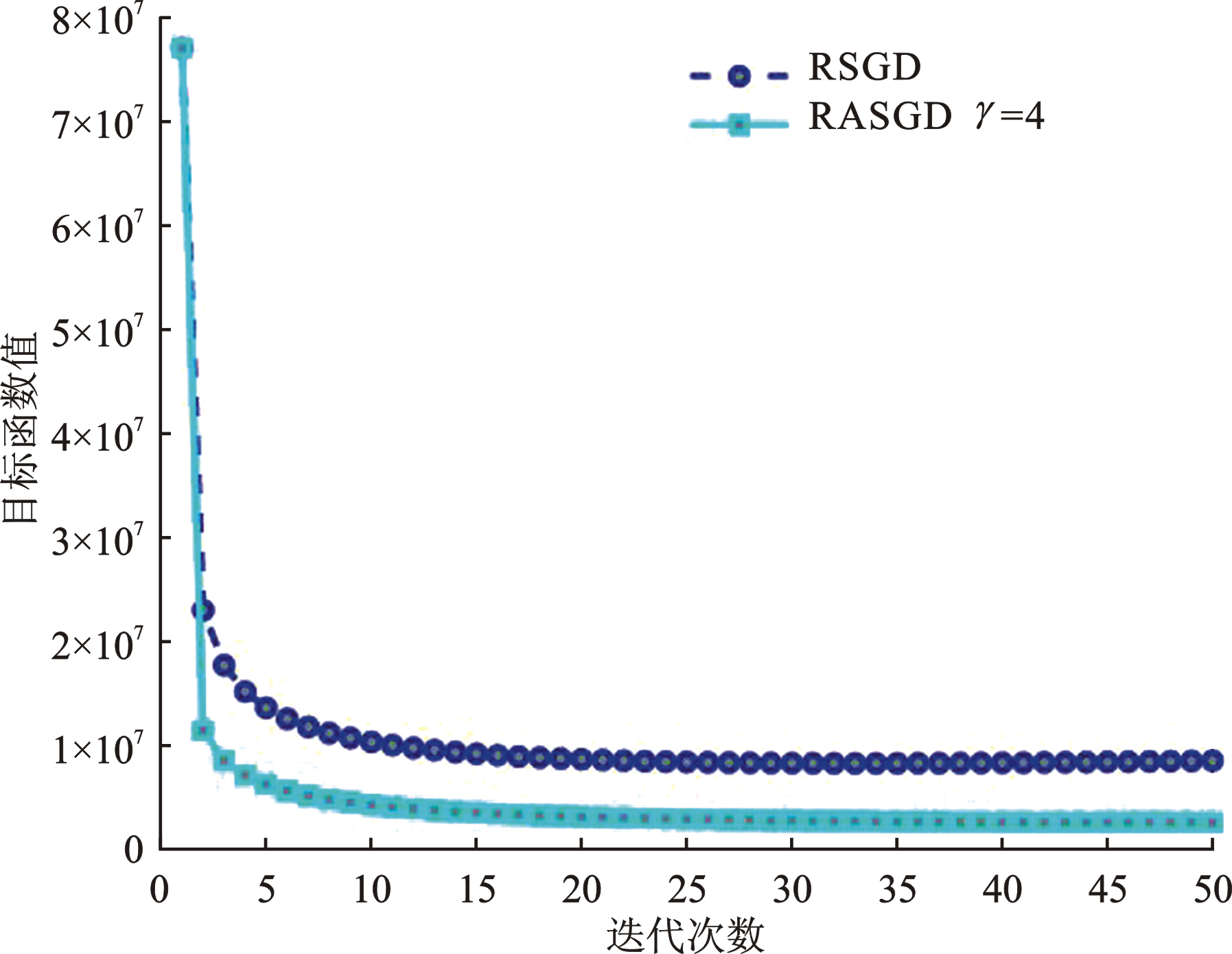
| [1] |
王勇, 王喜媛, 任泽洋. 毫米波MIMO的DNN混合预编码梯度优化方法[J]. 西安电子科技大学学报, 2022, 49(1):202-207.
|
|
WANG Yong, WANG Xiyuan, REN Zeyang. Algorithm for Gradient Optimization of Hybrid Precoding Based on DNN in the Millimeter Wave MIMO System[J]. Journal of Xidian University, 2022, 49(1):202-207.
|
| [2] |
LI J, XIAO M, FENG C, et al. Training Neural Networks by Lifted Proximal Operator Machines[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(6):3334-3348.
|
| [3] |
POLYAK B T. Introduction to Optimization[M]. New York: Optimization Software,1987.
|
| [4] |
NESTEROV Y. Introductory Lectures on Convex Optimization:a Basic Course[M]. Boston: Kluwer Academic Publishers, 2004.
|
| [5] |
BIRNBAUM B, DEVANUR N R D, XIAO L. Distributed Algorithms via Gradient Descent for Fisher Markets[C]//Proceedings of the 12th ACM Conference on Electronic Commerce. New York: ACM, 2011:127-136.
|
| [6] |
BAUSCHKE H H, BOLTE J, TEBOULLE M. A Descent Lemma Beyond Lipschitz Gradient Continuity:First-Order Methods Revisited and Applications[J]. Mathematics of Operations Research, 2017, 42(2):330-348.
|
| [7] |
LU H, FREUD R M, NESTEROV Y. Relatively-Smooth Convex Optimization by First Order Methods,and Applications[J]. SIAM Journal on Optimization, 2018, 28(1):333-354.
|
| [8] |
HANZELY F, RICHTARIK P, XIAO L. Accelerated Bregman Proximal Gradient Methods for Relatively Smooth Convex Optimization(2020)[R/OL].[2020-01-01].http://10.48550/arXiv.1808.03045.
|
| [9] |
NESTEROV Y. Implementable Tensor Methods in Unconstrained Convex Optimization[J]. Mathematical Programming, 2021, 186:157-183.
|
| [10] |
ZHOU Y, LIANG Y, SHEN L. A Simple Convergence Analysis of Bregman Proximal Gradient Algorithm[J]. Computational Optimization and Applications, 2019, 93:903-912.
|
| [11] |
LI H, LIN Z, FANG Y. Variance Reduced EXTRA and DIGing and Their Optimal Acceleration for Strongly Convex Decentralized Optimization[J]. Journal of Machine Learning Research, 2022, 23(1):10057-10097.
|
| [12] |
ZHOU P, YUAN X, LIN Z,et.al. A Hybrid Stochastic-Deterministic Minibatch Proximal Gradient Method for Efficient Optimization and Generalization[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(10):5933-5946.
|
| [13] |
SCHMIDT M, ROUX L N, BACH F. Minimizing Finite Sums with the Stochastic Average Gradient[J]. Mathematical Programming, 2017, 162(1-2):83-112.
|
| [14] |
JOHNSON R, ZHANG T. Accelerating Stochastic Gradient Descent Using Predictive Variance Reduction[C]//Advances in Neural Information Processing Systems. San Diego: NEURIPS, 2013,315-323.
|
| [15] |
HANZELY F, RICHTARIKP. Fastest Rates for Stochastic Mirror Descent Methods(2018)[R/OL].[2018-01-01].https://doi.org/10.48550/arXiv.1803.07374v1.
|
| [16] |
XIE X, ZHOU P, LI H,et.al. Adan:Adaptive Nesterov Momentum Algorithm for Faster Optimizing DeepModels(2023)[R/OL].[2023-01-01].https://doi.org/10.48550/arXiv.2208.06677.
|
| [17] |
ZHUANG Z, LIU M, CUTKOSKY A,et.al. Understanding Adamw through Proximal Methods and Scale-Freeness(2022)[R/OL].[2022-08-09].https://doi.org/10.48550/arXiv.2202.00089.
|
| [18] |
LI H, LIN Z. Restarted Nonconvex Accelerated Gradient Descent:No More Polylogarithmic Factor in the O(ε-7/4) Complexity(2022)[R/OL].[2022-01-01].https://doi.org/10.48550/arXiv.2201.11411.
|
| [19] |
POLYAK B T. Some Methods of Speeding up the Convergence of Iteration Methods[J]. Ussr Computational Mathematics and Mathematical Physics, 1964, 4(5):1-17.
|
| [20] |
NESTEROV Y. On an Approach to the Construction of Optimal Methods of Minimization of Smooth Convex Functions[J]. Ekonomika I Mateaticheskie Metody, 1988, 24(3):509-517.
|
| [21] |
ALLEN ZZ. Katyusha:the First Truly Accelerated Stochastic Gradient Method[C]//Proceedings of the 49th Annual ACM SIGACT Symposium on Theory of Computing. New York: ACM, 2017:1200-1206.
|
 ), FENG Xiangchu(
), FENG Xiangchu(