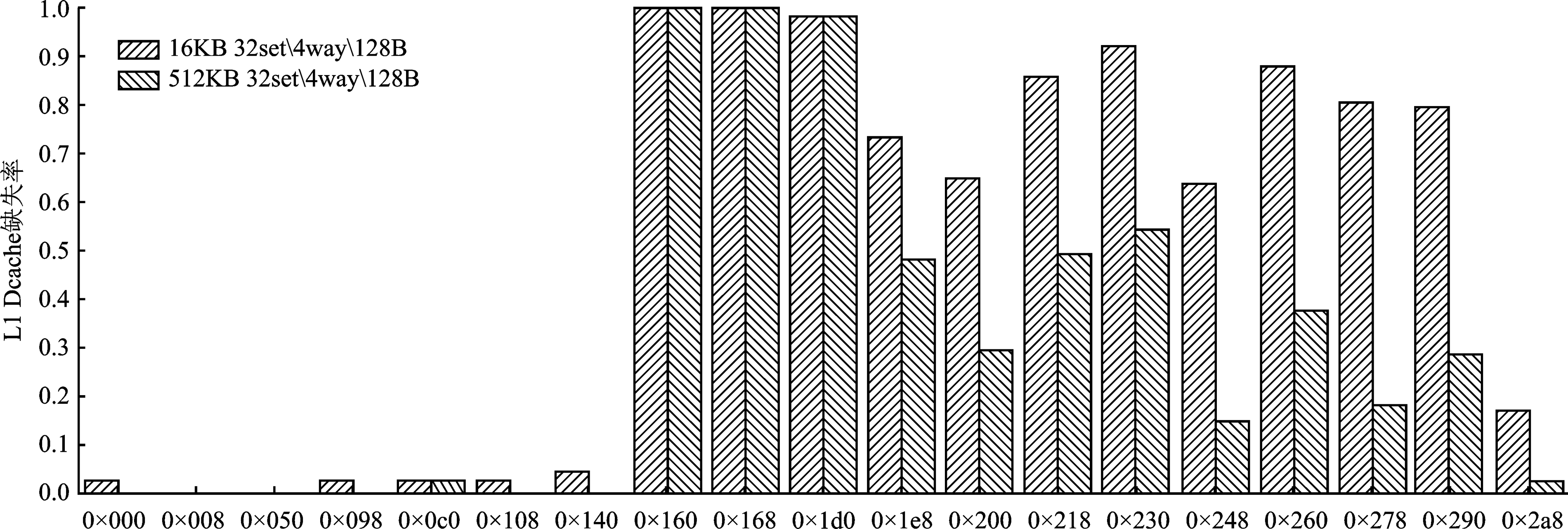
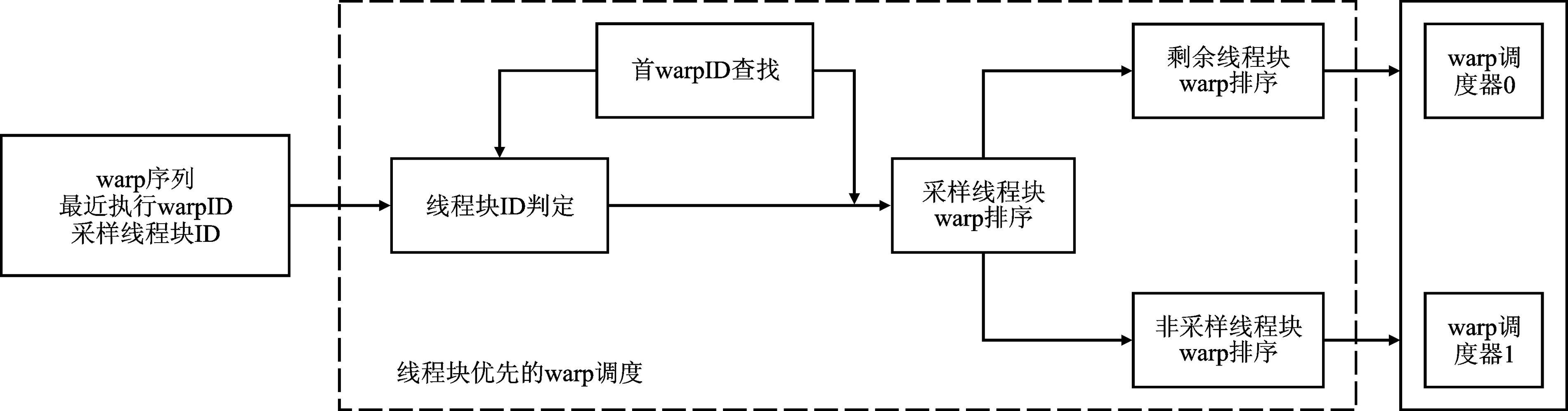
| [1] |
KRIZHEVSKY A, SUTSKEVER I, HINTON G. ImageNet Classification with Deep Convolutional Neural Networks[J]. Advances in neural information processing systems, 2012, 25(2):1106-1114.
|
| [2] |
CHATTERJEE S, ZIELINSKI P. On the Generalization Mystery in Deep Learning (2022)[J/OL].[2022-6-3]. https://doi.org/10.48550/arXiv.2203.10036.
|
| [3] |
韩永赛, 马时平, 何林远, 等. 改进YOLOv3的快速遥感机场区域目标检测[J]. 西安电子科技大学学报, 2021, 48(5):156-166.
|
|
HAN Yongsai, MA Shiping, HE Linyuan, et al. Detection of the Object in the Fast Remote Sensing Airport Area on the Improved YOLOv3[J]. Journal of Xidian University, 2021, 48(5):156-166.
|
| [4] |
ZOU Z, SHI Z, GUO Y, et al. Object Detection in 20 Years:A Survey (2019)[J/OL].[2019-5-16]. https://doi.org/10.48550/arXiv.1905.05055.
|
| [5] |
DU H, SHI H, ZENG D, et al. The Elements of End-to-End Deep Face Recognition:A Survey of Recent Advances (2021)[J/OL].[2021-12-27]. https://doi.org/10.48550/arXiv.2009.13290.
|
| [6] |
REDMON J, FARHADI A. YOLO9000:Better,Faster,Stronger[C]//IEEE Conference on Computer Vision & Pattern Recognition. Piscataway:IEEE, 2017:6517-6525.
|
| [7] |
RUSSAKOVSKY O, DENG J, SU H, et al. ImageNet Large Scale Visual Recognition Challenge[J]. International Journal of Computer Vision, 2015, 115(3):211-252.
doi: 10.1007/s11263-015-0816-y
|
| [8] |
HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]//Proceedings of the IEEE international conference on computer vision. Piscataway:IEEE, 2017:2961-2969.
|
| [9] |
LIU W, ANGUELOV D, ERHAN D, et al. SSD:Single Shot Multibox Detector[C]//European Conference on Computer Vision (ECCV), Heidelberg:Springer, 2016.21-37.
|
| [10] |
CHEN X, MA H, WAN J, et al. Multi-View 3D Object Detection Network for Autonomous Driving[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE, 2017.6526-6534.
|
| [11] |
HOWARD A G, ZHU M, CHEN B, et al. MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Applications (2017)[J/OL].[2017-04-17]. https://arxiv.org/abs/1704.04861.
|
| [12] |
LIANG Y, LU L, XIAO Q, et al. Evaluating Fast Algorithms for Convolutional Neural Networks on FPGAs[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2020, 39(4):857-870
doi: 10.1109/TCAD.43
|
| [13] |
ZHANG S, DU Z, LEI Z, et al. Cambricon-X:An Accelerator for Sparse Neural Networks[C]∥49th Annual IEEE/ACM International Symposium on Microarchitecture. New York: IEEE, 2016:1-12
|
| [14] |
GUO K, SUI L, QIU J, et al. Angel-Eye:A Complete Design Flow for Mapping CNN onto Embedded FPGA[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2017, 37(1):35-47
doi: 10.1109/TCAD.2017.2705069
|
| [15] |
CHEN Y H, KRISHNA T, EMER J S, et al. Eyeriss:An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks[J]. IEEE Journal of Solid-State Circuits, 2017, 52(1):127-138
doi: 10.1109/JSSC.2016.2616357
|
| [16] |
LUEBKE D, HUMPHREYS G. How GPUs Work[J]. IEEE Computer, 2007, 40:96-100.
|
| [17] |
NVIDIA Corporation. NVIDIA TESLA V100 GPU ARCHITECTURE (2017)[DB/OL].[2017-5-8]. https://www.nvidia.cn/content/dam/en-zz/zh_cn/Solutions/Data-Center/volta-gpu-architecture/Volta-Architecture-Whitepaper-v1.1-CN.compressed.pdf.
|
| [18] |
NVIDIA Corporation. NVIDIA TURING GPGPU ARCHITECTURE (2018)[DB/OL].[2018-8-14]. https://images.nvidia.cn/aem-dam/en-zz/Solutions/design-visualization/technologies/turing-architecture/NVIDIA-Turing-Architecture-Whitepaper.pdf.
|
| [19] |
NVIDIA Corporation. NVIDIA A100 Tensor Core GPU ARCHITECTURE (2020)[DB/OL].[2020-5-5]. https://images.nvidia.cn/aem-dam/en-zz/Solutions/data-center/nvidia-ampere-architecture-whitepaper.pdf#cid=_pa-srch-baid_zh-cn.
|
| [20] |
NVIDIA Corporation. NVIDIAH100 Tensor Core GPU ARCHITECTURE (2022)[DB/OL].[2022-9-19]. https://nvdam.widen.net/s/9bz6dw7dqr/gtc22-whitepaper-hopper.pdf.
|
 ),ZHANG Yuming1(
),ZHANG Yuming1(