

Journal of Xidian University ›› 2022, Vol. 49 ›› Issue (3): 183-190.doi: 10.19665/j.issn1001-2400.2022.03.020
• Computer Science and Technology & Artificial Intelligence • Previous Articles Next Articles
SHI Yunlong( ),YUAN Wenhao(),HU Shaodong(),LOU Yingxi()
),YUAN Wenhao(),HU Shaodong(),LOU Yingxi()
Received:2021-05-25
Revised:2021-12-08
Online:2022-06-20
Published:2022-07-04
Contact:
Wenhao YUAN
E-mail:syljoy@163.com;why_sdut@126.com;hsd_sdut@163.com;lyx_joy@163.com
CLC Number:
SHI Yunlong,YUAN Wenhao,HU Shaodong,LOU Yingxi. Convolutional quasi-recurrent network for real-time speech enhancement[J].Journal of Xidian University, 2022, 49(3): 183-190.
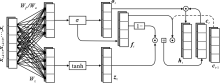
"
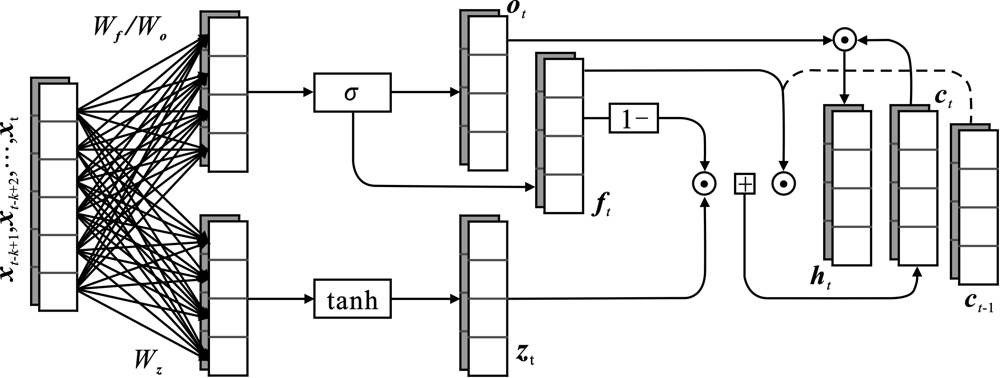
"
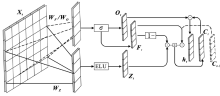
"
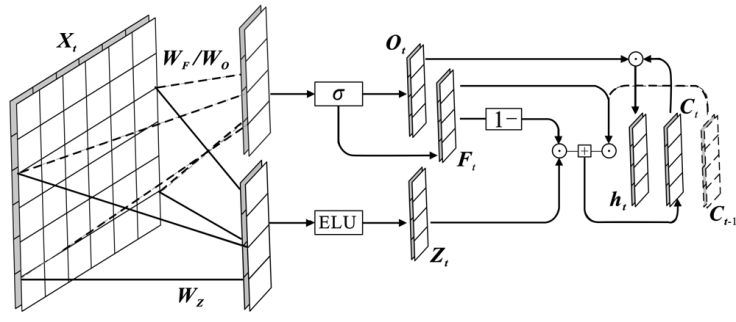
"
| 网络类型 | QRNN | CQRN | ||||
|---|---|---|---|---|---|---|
| k | 1 | 2 | 3 | 1 | 2 | 3 |
| 参数量/×106 | 5.26 | 10.37 | 15.48 | 4.89 | 5.56 | 6.22 |
"
| 方法 | 因果性 | CSIG | CBAK | COVL | PESQ |
|---|---|---|---|---|---|
| Wiener[ | 是 | 3.23 | 2.68 | 2.67 | 2.22 |
| SEGAN[ | 否 | 3.48 | 2.94 | 2.80 | 2.16 |
| Wavenet[ | 否 | 3.62 | 2.94 | 2.98 | |
| MMSE-GAN[ | 否 | 3.80 | 3.12 | 3.14 | 2.53 |
| Deep Feature Loss[ | 是 | 3.86 | 3.33 | 3.22 | |
| SE-FFTNET[ | 否 | 3.60 | 3.20 | 2.98 | 2.37 |
| HLGAN[ | 否 | 3.65 | 3.19 | 3.05 | 2.48 |
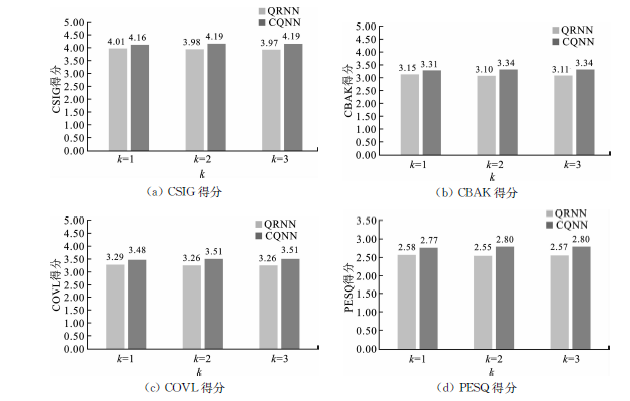
| CQRN | 是 | 4.19 | 3.34 | 3.51 | 2.80 |
"
| 帧移 | CSIG | CBAK | COVL | PESQ |
|---|---|---|---|---|
| 256点 | 4.19 | 3.34 | 3.51 | 2.80 |
| 128点 | 4.24 | 3.40 | 3.57 | 2.86 |
| [1] | LIU D, SMARAGDIS P, KIM M. Experiments on Deep Learning for Speech Denoising[C]// Fifteenth Annual Conference of the International Speech Communication Association.Baixas:ISCA, 2014:2685-2689. |
| [2] | 常新旭, 张杨, 杨林, 等. 融合多头自注意力机制的语音增强方法[J]. 西安电子科技大学学报, 2020, 47(1):104-110. |
| CHANG Xinxu, ZHANG Yang, YANG Lin, et al. Speech Enhancement Method Based on the Multi-Head Self-Attention Mechanism[J]. Journal of Xidian University, 2020, 47(1):104-110. | |
| [3] |
BOLL S. Suppression of Acoustic Noise in Speech Using Spectral Subtraction[J]. IEEE Transactions on Acoustics,Speech,and Signal Processing, 1979, 27(2):113-120.
doi: 10.1109/TASSP.1979.1163209 |
| [4] |
CHEN J, BENESTY J, HUANG Y, et al. New Insights into The Noise Reduction Wiener Filter[J]. IEEE Transactions on Audio,Speech,and Language Processing, 2006, 14(4):1218-1234.
doi: 10.1109/TSA.2005.860851 |
| [5] |
DENDRINOS M, BAKAMIDIS S, CARAYANNIS G. Speech Enhancement from Noise:A Regenerative Approach[J]. Speech Communication, 1991, 10(1):45-57.
doi: 10.1016/0167-6393(91)90027-Q |
| [6] | 时文华, 张雄伟, 邹霞, 等. 联合深度编解码网络和时频掩蔽估计的单通道语音增强[J]. 声学学报, 2020, 45(3):299-307. |
| SHI Wenhua, ZHANG Xiongwei, ZOU Xia, et al. Time Frequency Masking Based Speech Enhancement Using Deep Encoder-Decoder Neural Network[J]. Acta Acustica, 2020, 45(3):299-307. | |
| [7] | 贾海蓉, 王卫梅, 吉慧芳. 信噪比信息与时频特征修正相位的语音增强[J]. 西安电子科技大学学报, 2019, 46(5):162-170. |
| JIA Hairong, WANG Weimei, JI Huifang. Speech Enhancement Based on The Modified Phase Using Sgnal-to-Noise Ratio Information and Time-Frequency Characteristics[J]. Journal of Xidian University, 2019, 46(5):162-170. | |
| [8] |
XU Y, DU J, DAI L R, et al. An Experimental Study on Speech Enhancement Based on Deep Neural Networks[J]. IEEE Signal Processing Letters, 2013, 21(1):65-68.
doi: 10.1109/LSP.2013.2291240 |
| [9] | KANG T G, KWON K, SHIN J W, et al. NMF-Based Speech Enhancement Incorporating Deep Neural Network[C]// Fifteenth Annual Conference of the International Speech Communication Association.Baixas:ISCA, 2014:2843-2846. |
| [10] | KOUNOVSKY T, MALEK J. Single Channel Speech Enhancement Using Convolutional Neural Network[C]// 2017 IEEE International Workshop of Electronics,Control,Measurement,Signals and their Application to Mechatronics (ECMSM).Piscataway:IEEE, 2017:1-5. |
| [11] | PARK S R, LEE J W. A Fully Convolutional Neural Network for Speech Enhancement (2016)[J/OL]. [2016-09-22]. http://export.arxiv.org/pdf/1609.07132. |
| [12] | GERMAIN F, CHEN Q, KOLTUN V. Speech Denoising with Deep Feature Losses[C]// Proceedings of the Annual Conference of the International Speech Communication Association.Baixas:ISCA, 2019:2723-2727. |
| [13] |
HUANG P S, KIM M, HASEGAWA-JOHNSON M, et al. Joint Optimization of Masks and Deep Recurrent Neural Networks for Monaural Source Separation[J]. IEEE/ACM Transactions on Audio,Speech,and Language Processing, 2015, 23(12):2136-2147.
doi: 10.1109/TASLP.2015.2468583 |
| [14] | SUN L, DU J, DAI L R, et al. Multiple-Target Deep Learning for LSTM-RNN Based Speech Enhancement[C]// 2017 Hands-free Speech Communications and Microphone Arrays (HSCMA).Piscataway:IEEE, 2017:136-140. |
| [15] | GAO T, DU J, DAI L R, et al. Densely Connected Progressive Learning for LSTM-Based Speech Enhancement[C]// 2018 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP).Piscataway:IEEE, 2018:5054-5058. |
| [16] | BRADBURY J, MERITY S, XIONG C, et al. Quasi-Recurrent Neural Networks (2016)[J/OL]. [2016-11-05]. https://arxiv.org/abs/1611.01576. |
| [17] | ARIK S Ö, CHRZANOWSKI M, COATES A, et al. Deep Voice:Real-time Neural Text-to-Speech[C]// International Conference on Machine Learning. New York: ACM, 2017:195-204. |
| [18] | VALENTINI-BOTINHAO C, WANG X, TAKAKI S, et al. Speech Enhancement for a Noise-Robust Text-to-Speech Synthesis System Using Deep Recurrent Neural Networks[C]// Proceedings of International Speech Communication Association.Baixas:ISCA, 2016:352-356. |
| [19] | TJIEMANN J, ITO N, VINCENT E. The Diverse Environments Multi-Channel Acoustic Noise Database (DEMAND):A Database of Multichannel Environmental Noise Recordings[J]. Journal of the Acoustical Society of America, 2013, 19(1):035081. |
| [20] | WEN S X, DU J, LEE C H. On Generating Mixing Noise Signals with Basis Functions for Simulating Noisy Speech and Learning DNN-Based Speech Enhancement Models[C]// 2017 IEEE 27th International Workshop on Machine Learning for Signal Processing (MLSP).Piscataway:IEEE, 2017:1-6. |
| [21] | DONG Y, EVERSOLE A, SELTZER M, et al. An Introduction to Computational Networks and the Computational Network Toolkit:MSR-TR-2014-112[R]. Redmond: Microsoft Technical Report, 2014. |
| [22] |
HU Y, LOIZOU P C. Evaluation of Objective Quality Measures for Speech Enhancement[J]. IEEE Transactions on Audio,Speech,and Language Processing, 2007, 16(1):229-238.
doi: 10.1109/TASL.2007.911054 |
| [23] | SCALART P, FILHO J V. Speech Enhancement Based on A Priori Signal to Noise Estimation[C]// IEEE International Conference on Acoustics,Speech,and Signal Processing Conference Proceedings.Piscataway:IEEE, 1996:629-632. |
| [24] | PASCUAL S, BONAFONTE A, SERRA J. SEGAN:Speech Enhancement Generative Adversarial Network (2017)[J/OL]. [2017-03-28]. https://arxiv.org/abs/1703.09452v1. |
| [25] | RETHAGE D, PONS J, SERRA X. A Wavenet for Speech Denoising[C]// 2018 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP).Piscataway:IEEE, 2018:5069-5073. |
| [26] | SONI M H, SHAH N, PATIL H A. Time-Frequency Masking-Based Speech Enhancement Using Generative Adversarial Network[C]// 2018 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP).Piscataway:IEEE, 2018:5039-5043. |
| [27] | SHIFAS M P V, ADIGA N, TSIARAS V, et al. A Non-Causal FFTNet Architecture for Speech Enhancement (2020)[J/OL]. [2020-06-08]. https://arxiv.org/abs/2006.04469v1. |
| [28] |
YANG F, WANG Z, LI J, et al. Improving Generative Adversarial Networks for Speech Enhancement through Regularization of Latent Representations[J]. Speech Communication, 2020, 118:1-9.
doi: 10.1016/j.specom.2020.02.001 |
| [29] |
PANDEY A, WANG D L. On Cross-Corpus Generalization of Deep Learning Based Speech Enhancement[J]. IEEE/ACM Transactions on Audio,Speech,and Language Processing, 2020, 28:2489-2499.
doi: 10.1109/TASLP.2020.3016487 |
| [1] | ZHANG Min,JIA Hairong,ZHANG Gangmin,WANG Suying. Speech enhancement combining the self-adaptive soft mask and mixed features [J]. Journal of Xidian University, 2022, 49(2): 108-115. |
| [2] | ZHOU Peng,YANG Jun. Index edge geometric convolution neural network for point cloud classification [J]. Journal of Xidian University, 2022, 49(2): 207-217. |
| [3] | YU Haoyang,YIN Liang,LI Shufang,LV Shun. Recognition algorithm for the little sample radar modulation signal based on the generative adversarial network [J]. Journal of Xidian University, 2021, 48(6): 96-104. |
| [4] | SUN Yanjing,WEI Li,ZHANG Nianlong,YUN Xiao,DONG Kaiwen,GE Min,CHENG Xiaozhou,HOU Xiaofeng. Person re-identification method combining the DD-GAN and Global feature in a coal mine [J]. Journal of Xidian University, 2021, 48(5): 201-211. |
| [5] | ZHOU Peng,YANG Jun. Semantic segmentation of remote sensing images based on neural architecture search [J]. Journal of Xidian University, 2021, 48(5): 47-57. |
| [6] | YANG Yunhang,MIN Lianquan. Multi-scalefusion sketch recognition model by dilated convolution [J]. Journal of Xidian University, 2021, 48(5): 92-99. |
| [7] | ZHANG Yuhao,CHENG Peitao,ZHANG Shuhao,WANG Xiumei. Lightweight image super-resolution with the adaptive weight learning network [J]. Journal of Xidian University, 2021, 48(5): 15-22. |
| [8] | CHEN Changchuan,WANG Haining,HUANG Lian,HUANG Tao,LI Lianjie,HUANG Xiangkang,DAI Shaosheng. Facial expression recognition based on local representation [J]. Journal of Xidian University, 2021, 48(5): 100-109. |
| [9] | SONG Jianfeng,MIAO Qiguang,WANG Chongxiao,XU Hao,YANG Jin. Multi-scale single object tracking based on the attention mechanism [J]. Journal of Xidian University, 2021, 48(5): 110-116. |
| [10] | HUI Haisheng,ZHANG Xueying,WU Zelin,LI Fenglian. Method for stroke lesion segmentation using the primary-auxiliary path attention compensation network [J]. Journal of Xidian University, 2021, 48(4): 200-208. |
| [11] | WANG Ping,JIANG Yuze,ZHAO Guanghui. Object detection based on the multiscale location Enhancement network [J]. Journal of Xidian University, 2021, 48(3): 85-90. |
| [12] | MEI Shulin,JIA Hairong,WANG Xiaogang,WU Yifeng. Combination of dynamic features with a new mask to optimize neural network speech enhancement [J]. Journal of Xidian University, 2021, 48(3): 91-98. |
| [13] | GUO Zekun,TIAN Long,HAN Ning,WANG Penghui,LIU Hongwei,CHEN Bo. Radar HRRP based few-shot target recognition with CNN-SSD [J]. Journal of Xidian University, 2021, 48(2): 7-14. |
| [14] | CHENG Lei,WANG Yue,TIAN Chunna. Residual attention mechanism for visual tracking [J]. Journal of Xidian University, 2020, 47(6): 148-157. |
| [15] | KONG Xin,CHEN Gang,GONG Guoliang,LU Huaxiang,Mao Wenyu. High performance multiply-accumulator for the convolutional neural networks accelerator [J]. Journal of Xidian University, 2020, 47(4): 55-63. |
|