

Journal of Xidian University ›› 2019, Vol. 46 ›› Issue (3): 74-81.doi: 10.19665/j.issn1001-2400.2019.03.012
Previous Articles Next Articles
JIA Hairong,WANG Weimei,WANG Yan,PEI Junhua
Received:2018-12-04
Online:2019-06-20
Published:2019-06-19
CLC Number:
JIA Hairong,WANG Weimei,WANG Yan,PEI Junhua. Speech enhancement based on discriminative joint sparse dictionary alternate optimization[J].Journal of Xidian University, 2019, 46(3): 74-81.
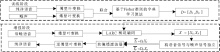
"


"
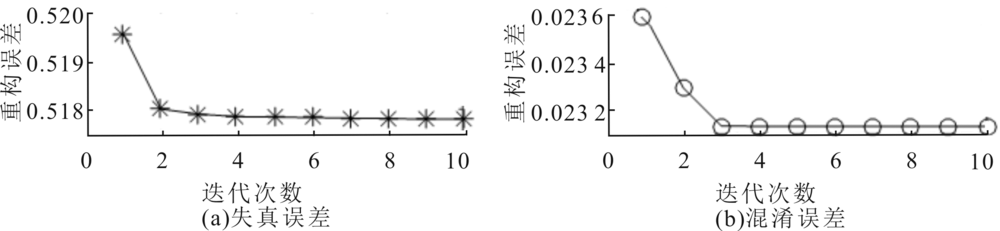
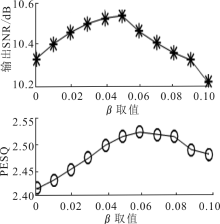
"
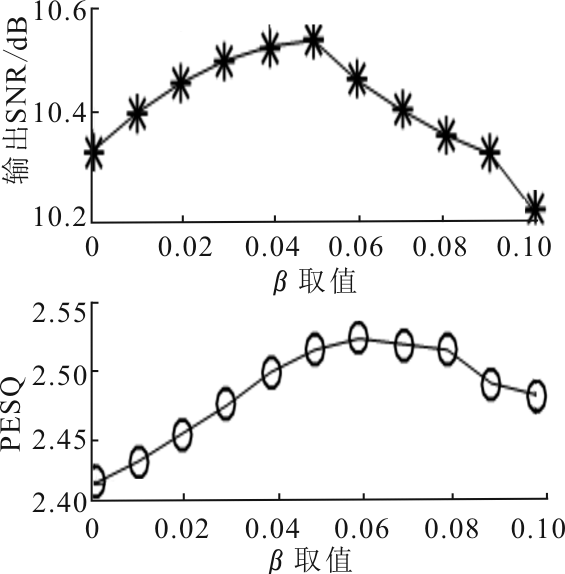
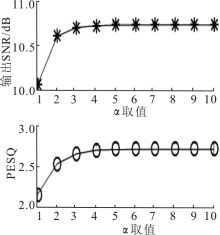
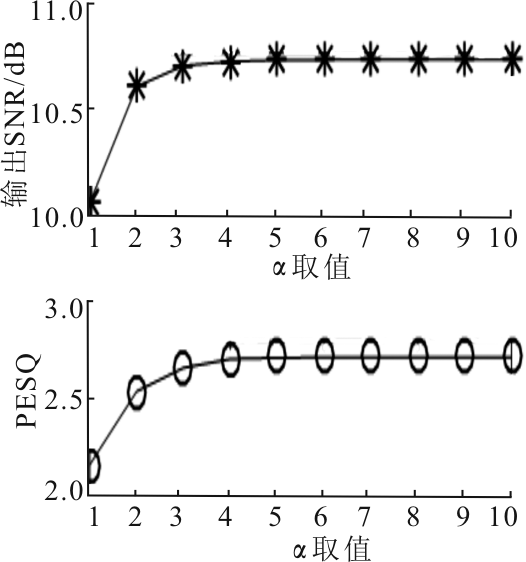
"
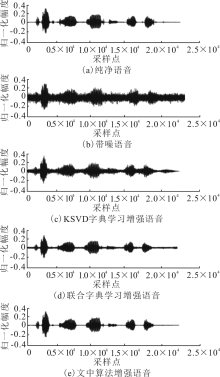
"
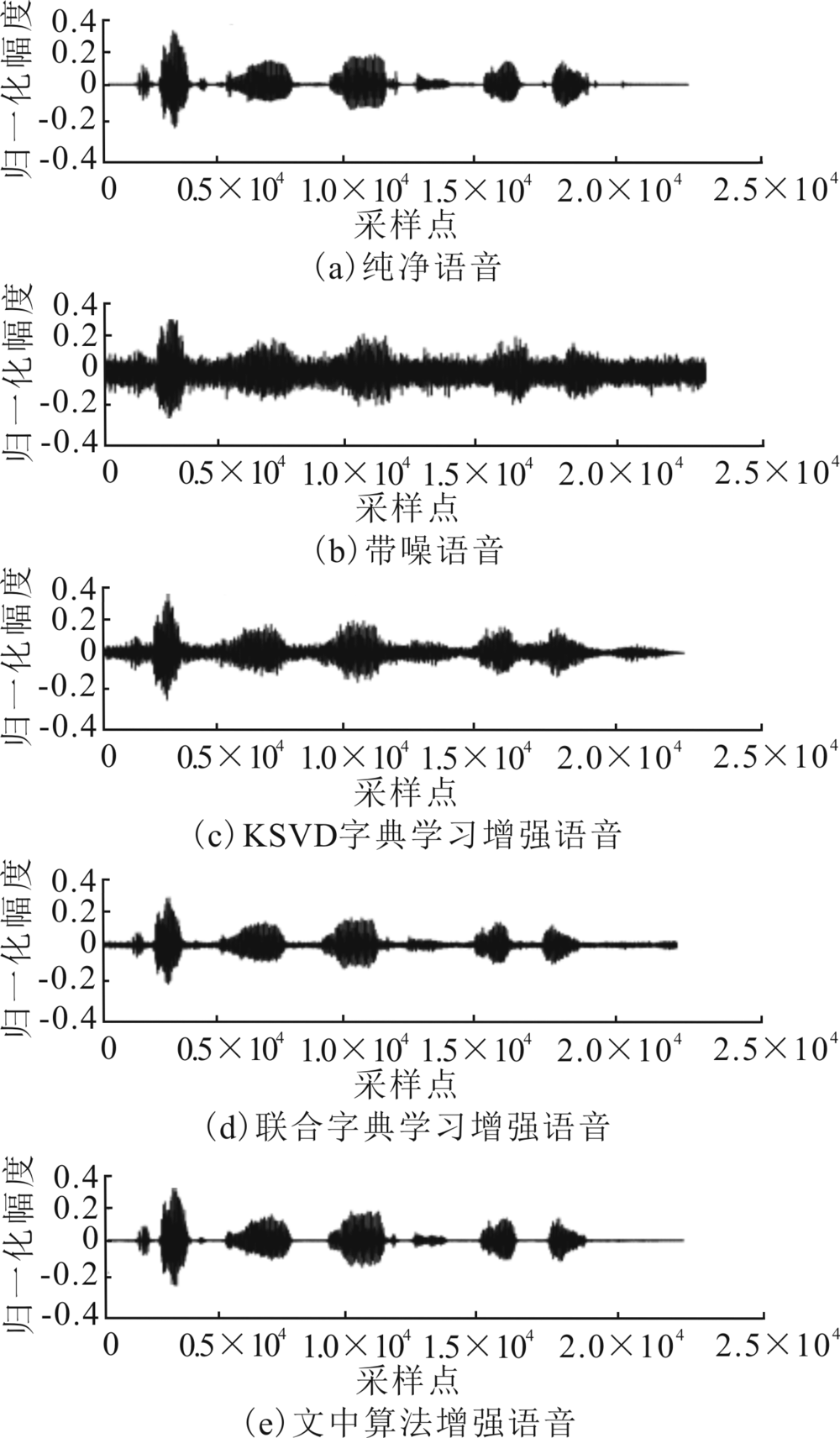
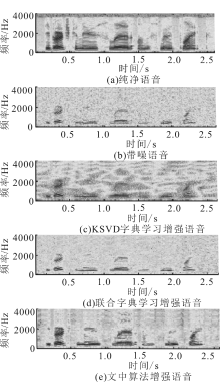
"
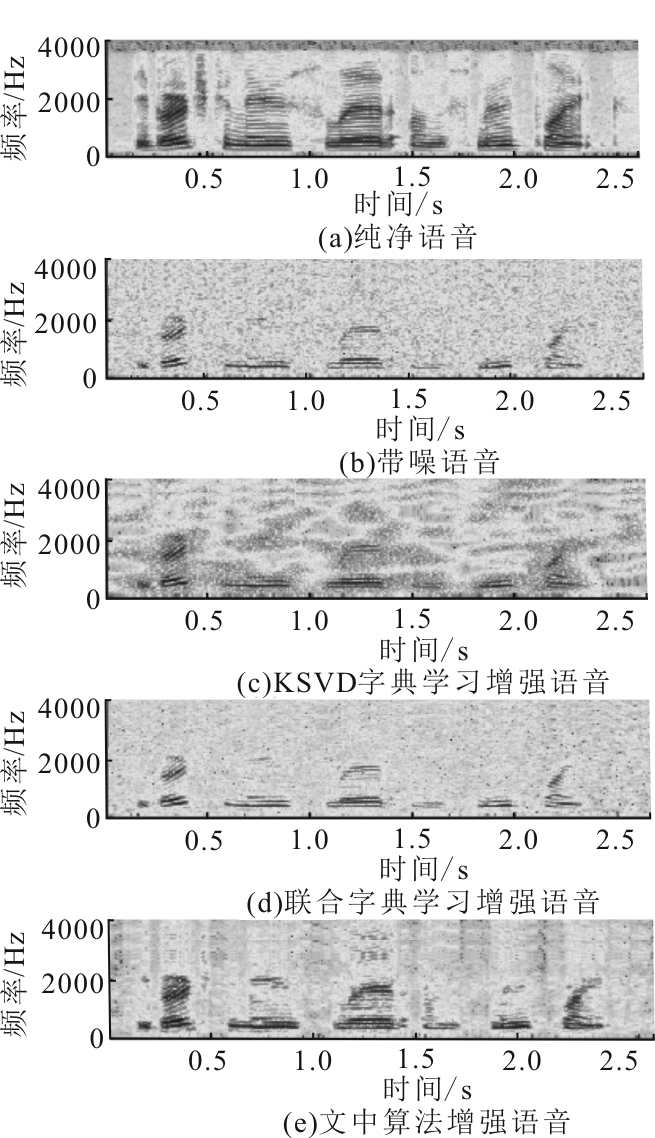
"
| 噪声 类型 | 输入 SNR | KSVD输出SNR | 联合字典输出SNR | 文中算法输出SNR | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sp01 | Sp02 | Sp03 | Sp04 | Sp05 | Sp06 | Sp01 | Sp02 | Sp03 | Sp04 | Sp05 | Sp06 | Sp01 | Sp02 | Sp03 | Sp04 | Sp05 | Sp06 | |||
| White | 5 | -3.48 | -3.60 | -3.52 | -3.50 | -3.59 | -3.64 | 3.59 | 3.90 | 3.64 | 4.08 | 3.96 | 4.48 | 8.77 | 7.74 | 7.26 | 8.63 | 7.78 | 7.63 | |
| 0 | 4.30 | 3.43 | 4.05 | 3.88 | 3.81 | 3.43 | 8.57 | 7.90 | 7.23 | 7.78 | 7.90 | 7.57 | 11.75 | 10.81 | 10.17 | 11.04 | 10.48 | 10.33 | ||
| 5 | 10.07 | 9.94 | 10.57 | 10.63 | 9.31 | 10.61 | 13.60 | 12.09 | 12.31 | 12.58 | 12.84 | 12.70 | 14.99 | 13.94 | 13.43 | 13.19 | 12.91 | 12.92 | ||
| Pink | -5 | -3.99 | -3.11 | -3.95 | -3.97 | -4.07 | -4.00 | 3.13 | 3.94 | 3.65 | 3.75 | 3.70 | 3.85 | 6.88 | 6.94 | 6.22 | 7.88 | 7.14 | 6.62 | |
| 0 | 3.96 | 3.86 | 4.48 | 4.48 | 4.53 | 4.14 | 7.79 | 7.71 | 8.04 | 8.07 | 8.07 | 7.78 | 10.45 | 10.19 | 9.65 | 10.89 | 10.28 | 10.10 | ||
| 5 | 10.03 | 9.50 | 9.84 | 9.64 | 9.29 | 9.58 | 12.60 | 12.21 | 12.59 | 12.83 | 12.15 | 12.22 | 13.96 | 13.39 | 13.20 | 14.24 | 13.82 | 14.03 | ||
| F16 | -5 | -3.68 | -3.91 | -3.81 | -3.99 | -3.71 | -3.93 | 4.67 | 3.21 | 4.67 | 4.26 | 4.28 | 4.13 | 8.07 | 8.07 | 7.76 | 9.45 | 8.45 | 8.09 | |
| 0 | 4.16 | 3.44 | 3.79 | 3.91 | 3.99 | 3.55 | 7.09 | 8.54 | 8.92 | 7.65 | 7.85 | 8.79 | 11.56 | 11.07 | 10.64 | 12.28 | 11.47 | 11.03 | ||
| 5 | 9.82 | 9.04 | 9.50 | 9.40 | 9.08 | 9.18 | 12.92 | 12.57 | 13.50 | 13.38 | 13.31 | 12.60 | 15.01 | 14.07 | 13.95 | 15.34 | 14.79 | 14.37 | ||
"
| 噪声 类型 | 输入 SNR/dB | KSVD输出PESQ | 联合字典输出PESQ | 文中算法输出PESQ | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sp01 | Sp02 | Sp03 | Sp04 | Sp05 | Sp06 | Sp01 | Sp02 | Sp03 | Sp04 | Sp05 | Sp06 | Sp01 | Sp02 | Sp03 | Sp04 | Sp05 | Sp06 | |||
| White | -5 | 1.25 | 1.54 | 1.43 | 1.24 | 1.23 | 1.43 | 1.44 | 1.61 | 1.48 | 1.46 | 1.50 | 1.47 | 2.34 | 2.39 | 2.31 | 2.25 | 2.29 | 2.65 | |
| 0 | 1.65 | 1.72 | 1.68 | 1.50 | 1.47 | 1.69 | 1.84 | 1.85 | 1.95 | 1.81 | 1.84 | 2.03 | 2.69 | 2.76 | 2.68 | 2.57 | 2.65 | 2.99 | ||
| 5 | 1.98 | 2.24 | 2.34 | 1.89 | 1.75 | 2.01 | 2.45 | 2.43 | 2.43 | 2.38 | 2.48 | 2.48 | 2.94 | 3.04 | 2.96 | 2.87 | 3.00 | 3.18 | ||
| Pink | -5 | 1.64 | 1.60 | 1.59 | 1.22 | 1.25 | 1.43 | 1.88 | 1.75 | 1.79 | 1.64 | 1.69 | 1.75 | 1.82 | 1.77 | 2.00 | 1.73 | 1.68 | 2.34 | |
| 0 | 1.89 | 1.89 | 1.89 | 1.70 | 1.54 | 1.81 | 1.99 | 1.94 | 2.02 | 1.98 | 2.02 | 2.05 | 2.28 | 2.15 | 2.41 | 2.18 | 2.18 | 2.68 | ||
| 5 | 1.90 | 2.05 | 2.05 | 1.86 | 1.75 | 2.02 | 2.41 | 2.34 | 2.34 | 2.39 | 2.45 | 2.43 | 2.63 | 2.61 | 2.72 | 2.60 | 2.66 | 3.02 | ||
| F16 | -5 | 1.63 | 1.64 | 1.38 | 1.30 | 1.26 | 1.45 | 1.64 | 1.78 | 1.55 | 1.44 | 1.42 | 1.61 | 2.54 | 2.62 | 2.70 | 2.48 | 2.52 | 2.87 | |
| 0 | 1.81 | 1.86 | 1.82 | 1.68 | 1.58 | 1.82 | 1.98 | 2.09 | 1.89 | 1.79 | 1.76 | 2.00 | 2.86 | 2.97 | 2.95 | 2.72 | 2.80 | 3.04 | ||
| 5 | 1.90 | 2.04 | 1.94 | 1.85 | 1.71 | 1.96 | 2.32 | 2.16 | 2.26 | 2.14 | 2.16 | 2.36 | 3.07 | 3.22 | 3.19 | 3.02 | 3.02 | 3.22 | ||
"
| 输入SNR/dB | KSVD | 联合字典 | 文中算法 | |||
|---|---|---|---|---|---|---|
| 输出SNR/dB | 输出PESQ | 输出SNR/dB | 输出PESQ | 输出SNR/dB | 输出PESQ | |
| -5 | -3.74 | 1.42 | 3.94 | 1.61 | 7.74 | 2.29 |
| 0 | 3.96 | 1.72 | 7.96 | 1.94 | 10.78 | 2.64 |
| 5 | 9.72 | 1.96 | 12.72 | 2.36 | 13.97 | 2.94 |
| [1] |
MAVADDATY S, AHADI S M, SEYEDIN S . Speech Enhancement Using Sparse Dictionary Learning in Wavelet Packet Transform Domain[J]. Computer Speech and Language, 2017,44:22-47.
doi: 10.1016/j.csl.2017.01.009 |
| [2] |
CROZIER P M, CHEETHAM B M G, HOLT C , et al. Speech Enhancement Employing Spectral Subtraction and Linear Predictive Analysis[J]. Electronics Letters, 1993,29(12):1094-1095.
doi: 10.1049/el:19930730 |
| [3] |
EPHRAIM Y . Statistical-model-based Speech Enhancement Systems[J]. Proceedings of the IEEE, 1992,80(10):1526-1555.
doi: 10.1109/5.168664 |
| [4] | EPHRAIM Y, VAN TREES H L . A Signal Subspace Approach for Speech Enhancement[CP/OL].[2018-11-16]. https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=319311 |
| [5] |
LI H, HE X, TAO D , et al. Joint Medical Image Fusion, Denoising and Enhancement via Discriminative Low-rank Sparse Dictionaries Learning[J]. Pattern Recognition, 2018,79:130-146.
doi: 10.1016/j.patcog.2018.02.005 |
| [6] |
YANG J, HE Q, LI Y , et al. Dictionary Learning Based on M-PCA-N for Audio Signal Sparse Representation[J]. IET Signal Processing, 2018,12(2):198-206.
doi: 10.1049/iet-spr.2015.0277 |
| [7] |
ZHANG L, BAO G, ZHANG J , et al. Supervised Single-channel Speech Enhancement Using Ratio Mask with Joint Dictionary Learning[J]. Speech Communication, 2016,82:38-52.
doi: 10.1016/j.specom.2016.06.001 |
| [8] | 郭欣, 贾海蓉, 王栋 . 利用子空间改进的K-SVD语音增强算法[J]. 西安电子科技大学学报, 2016,43(6):109-115. |
| GUO Xin, JIA Hairong, WANG Dong . Speech Enhancement Using the Improved K-SVD Algorithm by Subspace[J]. Journal of Xidian University, 2016,43(6):109-115. | |
| [9] |
SIGG C D, DIKK T, BUHMANN J M . Speech Enhancement Using Generative Dictionary Learning[J]. IEEE Transactions on Audio, Speech and Language Processing, 2012,20(6):1698-1712.
doi: 10.1109/TASL.2012.2187194 |
| [10] | ZHANG L, XU X, CHEN H , et al. Supervised Single-channel Speech Dereverberation and Denoising Using a Two-stage Model Based Sparse Representation[J]. Speech Communication, 2017,97:1-8. |
| [11] | 罗友 . 基于联合字典学习和稀疏表示的语音降噪算法研究[D]. 合肥: 中国科学技术大学, 2016. |
| [12] | 桑成伟, 孙洪 . 基于可区分性字典学习模型的极化SAR图像分类[J]. 信号处理, 2017,33(11):1405-1415. |
| SANG Chengwei, SUN Hong . Discriminative Dictionary Learning for Polarimetric SAR Image Classification[J]. Journal of Signal Processing, 2017,33(11):1405-1415. | |
| [13] | YANG M, ZHANG L, FENG X , et al. Fisher Discrimination Dictionary Learning for Sparse Representation [C]//Proceedings of the 2011 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2011: 543-550. |
| [14] |
WANG R, GUO S, LI Y , et al. Fisher Discriminative Dictionary Learning for Vehicle Classification in Acoustic Sensor Networks[J]. Journal of Signal Processing Systems, 2017,86(1):99-107.
doi: 10.1007/s11265-016-1105-x |
| [15] | 裴俊华 . 基于小字典学习的语音增强算法研究[D]. 太原: 太原理工大学, 2018. |
| [16] |
WANG M, ZHANG E, TANG Z . Speech Enhancement Based on NMF under Electric Vehicle Noise Condition[J]. IEEE Access, 2018,6:9147-9159.
doi: 10.1109/ACCESS.2018.2797165 |
| [17] |
RUBINSTEIN R, PELEG T, ELAD M . Analysis K-SVD: A Dictionary-learning Algorithm for the Analysis Sparse Model[J]. IEEE Transactions on Signal Processing, 2013,61(3):661-677.
doi: 10.1109/TSP.2012.2226445 |
| [18] |
AHARON M, ELAD M, BRUCKSTEIN A . K-SVD: An Algorithm for Designing Overcomplete Dictionaries for Sparse Representation[J]. IEEE Transactions on Signal Processing, 2006,54(11):4311-4322.
doi: 10.1109/TSP.2006.881199 |
| [19] | MADHU N, SPRIET A, JANSEN S , et al. The Potential for Speech Intelligibility Improvement Using the Ideal Binary Mask and the Ideal Wiener Filter in Single Channel Noise Reduction Systems: Application to Auditory Prostheses[J]. IEEE Transactions on Audio, Speech and Language Processing, 2013,21(1):61-70. |
| [20] | 王栋, 贾海蓉 . 改进相位谱补偿的语音增强算法[J]. 西安电子科技大学学报, 2017,44(3):83-88. |
| WANG Dong, JIA Hairong . Speech Enhancement Using Improved Phase Spectrum Compensation[J]. Journal of Xidian University, 2017,44(3):83-88. |
| [1] | MEI Shulin,JIA Hairong,WANG Xiaogang,WU Yifeng. Combination of dynamic features with a new mask to optimize neural network speech enhancement [J]. Journal of Xidian University, 2021, 48(3): 91-98. |
| [2] | LU Yan,LIAO Guisheng,HUANG Qingxiang. Cross-camera moving target tracking algorithm based on sparse representation [J]. Journal of Xidian University, 2021, 48(2): 197-204. |
| [3] | CHANG Xinxu,ZHANG Yang,YANG Lin,KOU Jinqiao,WANG Xin,XU Dongdong. Speech enhancement method based on the multi-head self-attention mechanism [J]. Journal of Xidian University, 2020, 47(1): 104-110. |
| [4] | HE Wangpeng,HU Jie,CHEN Binqiang,LI Cheng,GUO Baolong. Sparsity-induced resonance demodulation method for blade crack detection [J]. Journal of Xidian University, 2019, 46(6): 75-80. |
| [5] | ZHAO Hui,ZHANG Le,LIU Yingli,ZHANG Jing,ZHANG Tianqi. Optimization of the low coherence and high robustness observation matrix [J]. Journal of Xidian University, 2019, 46(6): 171-178. |
| [6] | YANG Lei,YUE Yunze,LI Pucheng,ZHANG Tao,YANG Huan. Sparse representation of large dynamic range SAR imaging for multiple ground moving targets [J]. Journal of Xidian University, 2019, 46(5): 31-40. |
| [7] | YUAN Wenhao,LIANG Chunyan,LOU Yingxi,FANG Chao,WANG Zhiqiang. Speech enhancement method based on the time-frequency smoothing deep neural network [J]. Journal of Xidian University, 2019, 46(4): 130-136. |
| [8] | WANG Hongyan,QIU Helei,PEI Tengda. Visual tracking method using discriminant dictionary learning [J]. Journal of Xidian University, 2019, 46(4): 150-158. |
| [9] | YUAN Wenhao,LOU Yingxi,LIANG Chunyan,WANG Zhiqiang. Speech enhancement method based on the perceptual joint optimization deep neural network [J]. Journal of Xidian University, 2019, 46(2): 89-94. |
| [10] | YU Lihong,ZHAO Jiaxiang. Design of sparse MIMO equalizers using least angle regression [J]. Journal of Xidian University, 2019, 46(1): 73-78. |
| [11] | WANG Chuanchuan,ZENG Yonghu,FU Weihong,WANG Liandong. Estimation algorithm for an underdetermined mixing matrix based on maximum density point searching [J]. Journal of Xidian University, 2019, 46(1): 106-111. |
| [12] | LI Long;LIU Zheng. Noise-robust multi-feature joint learning HRRP recognition method [J]. Journal of Xidian University, 2018, 45(4): 57-62. |
| [13] | WANG Dong;JIA Hairong. Speech enhancement using improved phase spectrum compensation [J]. Journal of Xidian University, 2017, 44(3): 83-88. |
| [14] | GUO Xin;JIA Hairong;WANG Dong. Speech enhancement using the improved K-SVD algorithm by subspace [J]. Journal of Xidian University, 2016, 43(6): 109-115. |
| [15] | KONG Fanqiang;BIAN Chending;LI Yunsong;GUO Wenjun. Hyperspectral unmixing method based on the non-convex sparse and low-rank constraints [J]. Journal of Xidian University, 2016, 43(6): 116-121. |
|