

Journal of Xidian University ›› 2020, Vol. 47 ›› Issue (1): 104-110.doi: 10.19665/j.issn1001-2400.2020.01.015
Previous Articles Next Articles
CHANG Xinxu,ZHANG Yang,YANG Lin,KOU Jinqiao,WANG Xin,XU Dongdong
Received:2019-09-28
Online:2020-02-20
Published:2020-03-19
CLC Number:
CHANG Xinxu,ZHANG Yang,YANG Lin,KOU Jinqiao,WANG Xin,XU Dongdong. Speech enhancement method based on the multi-head self-attention mechanism[J].Journal of Xidian University, 2020, 47(1): 104-110.
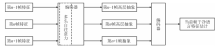
"
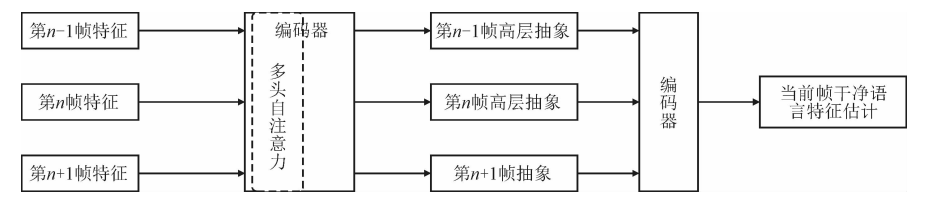

"
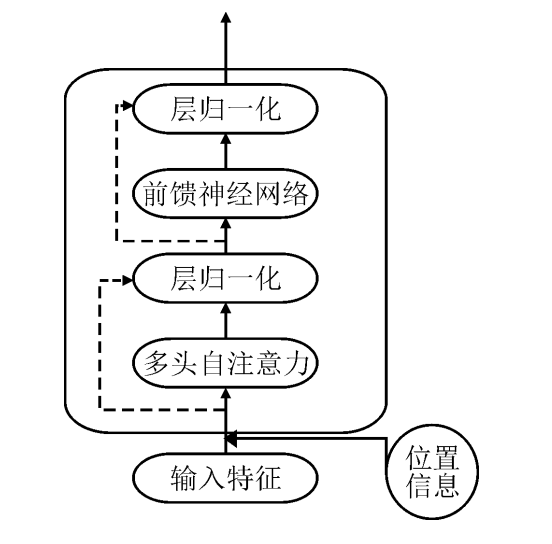
"
| 参数 | 训练集 | 测试集 |
|---|---|---|
| 信噪比/dB | -10,-5,0,5,10 | -6,0,6 |
| 噪声类型 | 100种噪声 | noisex-92 |
| 干净语音 | 700位不同说话人,每人10条 | 30位不同说话人,每人5条 |
"
| 信噪比 | 噪声类型 | DNN | GRU | self-attention-gru | time-self-attention-gru | time-self-attention | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PESQ STOI | PESQ STOI | PESQ STOI | PESQ STOI | PESQ STOI | |||||||
| -6dB | babble | 1.1002 | 0.4495 | 1.0814 | 0.4662 | 1.1737 | 0.4630 | 1.1381 | 0.4610 | 1.2276 | 0.4769 |
| lepoard | 1.7546 | 0.6710 | 1.7988 | 0.6802 | 1.9248 | 0.7038 | 1.9402 | 0.7016 | 1.9902 | 0.7027 | |
| m109 | 1.4913 | 0.6081 | 1.7218 | 0.6335 | 1.7517 | 0.6345 | 1.7564 | 0.6416 | 1.8196 | 0.6202 | |
| machinegun | 1.6661 | 0.6887 | 1.7390 | 0.6991 | 1.9180 | 0.7303 | 1.8928 | 0.7263 | 2.0003 | 0.7377 | |
| volvo | 2.2226 | 0.7734 | 2.2397 | 0.7985 | 2.4638 | 0.8209 | 2.5153 | 0.8292 | 2.5213 | 0.8170 | |
| 0dB | babble | 1.6429 | 0.6509 | 1.7266 | 0.6656 | 1.7646 | 0.6661 | 1.7911 | 0.6710 | 1.8297 | 0.6735 |
| lepoard | 2.2232 | 0.7756 | 2.3171 | 0.7853 | 2.3940 | 0.8021 | 2.4314 | 0.8014 | 2.4438 | 0.7987 | |
| m109 | 2.0653 | 0.7520 | 2.2387 | 0.7702 | 2.2766 | 0.7786 | 2.3075 | 0.7847 | 2.2701 | 0.7673 | |
| machinegun | 2.1585 | 0.7842 | 2.2540 | 0.7991 | 2.3934 | 0.8209 | 2.4098 | 0.8241 | 2.4530 | 0.8240 | |
| volvo | 2.5670 | 0.8257 | 2.6415 | 0.8535 | 2.7812 | 0.8669 | 2.8528 | 0.8746 | 2.8344 | 0.8633 | |
| 6dB | babble | 2.1529 | 0.7787 | 2.2652 | 0.7970 | 2.2929 | 0.7993 | 2.3321 | 0.8046 | 2.3273 | 0.8009 |
| lepoard | 2.5520 | 0.8341 | 2.6810 | 0.8488 | 2.7530 | 0.8607 | 2.7935 | 0.8624 | 2.7999 | 0.8570 | |
| m109 | 2.4506 | 0.8264 | 2.6088 | 0.8466 | 2.6674 | 0.8561 | 2.6884 | 0.8598 | 2.6474 | 0.8486 | |
| machinegun | 2.5253 | 0.8381 | 2.6456 | 0.8574 | 2.7358 | 0.8710 | 2.7849 | 0.8757 | 2.7913 | 0.8716 | |
| volvo | 2.7962 | 0.8505 | 2.9344 | 0.8806 | 3.0107 | 0.8899 | 3.0764 | 0.8969 | 3.0734 | 0.8881 | |
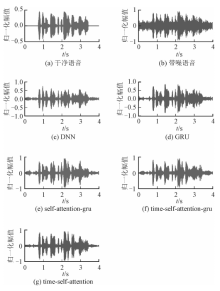
"
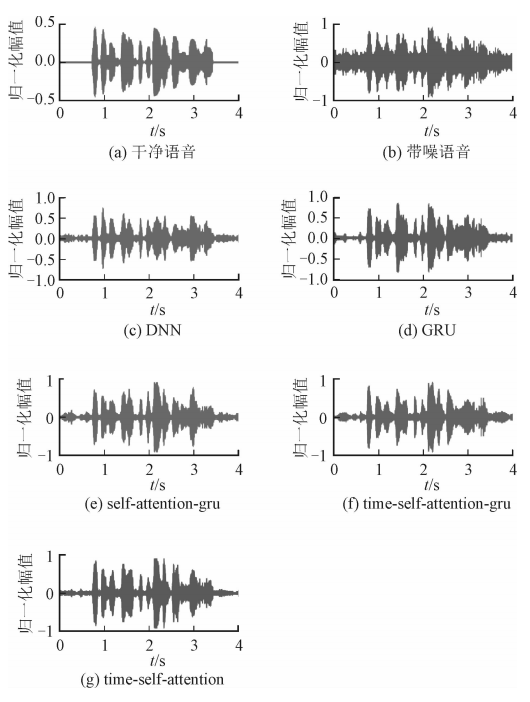
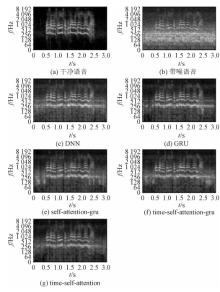
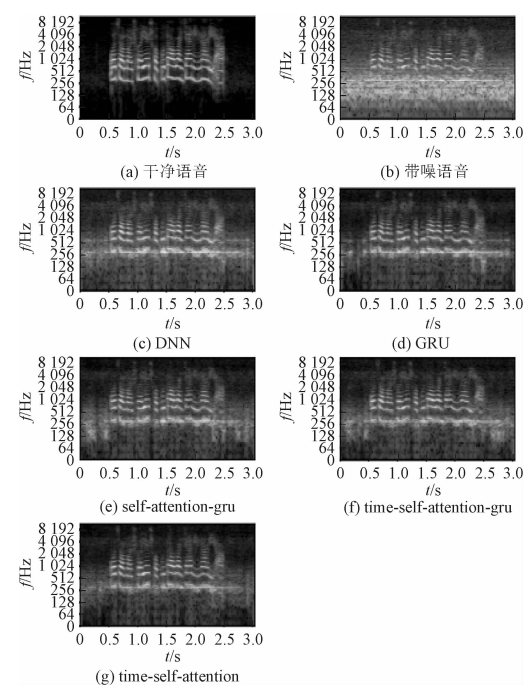
"
| [1] | LOIZOU P C . Speech Enhancement: Theory and Practice[M]. Boca Raton: CRC Press, 2013. |
| [2] | WANG D L, CHEN J . Supervised Speech Separation Based on Deep Learning: An Overview[J]. IEEE/ACM Transactions on Audio, Speech and Language Processing, 2018,26(10):1702-1726. |
| [3] | GRAIS E M, SEN M U, ERDOGAN H . Deep Neural Networks for Single Channel Source Separation[C]//Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2014: 3734-3738. |
| [4] | WANG Y, NARAYANAN A, WANG D L . On Training Targets for Supervised Speech Separation[J]. IEEE/ACM Transactions on Audio, Speech and Language Processing, 2014,22(12):1849-1858. |
| [5] | XU Y, DU J, DAI L R , et al. An Experimental Study on Speech Enhancement Based on Deep Neural Networks[J]. IEEE Signal Processing Letters, 2014,21(1):65-68. |
| [6] | XU Y, DU J, DAI L R , et al. A Regression Approach to Speech Enhancement Based on Deep Neural Networks[J]. IEEE/ACM Transactions on Audio, Speech and Language Processing, 2015,23(1):7-19. |
| [7] | CHEN J, WANG D . Long Short-term Memory for Speaker Generalization in Supervised Speech Separation[J]. Journal of the Acoustical Society of America, 2017,141(6):4705-4714. |
| [8] | SUN L, DU J, DAI L R , et al. Multiple-target Deep Learning for LSTM-RNN Based Speech Enhancement[C]//Proceedings of the 2017 Hands-free Speech Communications and Microphone Arrays. Piscataway: IEEE, 2017: 136-140. |
| [9] | LIU M, WANG Y, WANG J , et al. Speech Enhancement Method Based on LSTM Neural Network for Speech Recognition[C]//Proceedings of the 2019 International Conference on Signal Processing. Piscataway: IEEE, 2019: 245-249. |
| [10] | PANDA A . Speech Enhancement Using RNN Models and Ideal Exponential Mask[C]//Proceedings of the 2018 IEEE Applied Signal Processing Conference. Piscataway: IEEE, 2018: 178-182. |
| [11] | KOUNOVSKY T, MALEK J . Single Channel Speech Enhancement Using Convolutional Neural Network[C]//Proceedings of the 2017 IEEE International Workshop of Electronics, Control, Measurement, Signals and Their Application to Mechatronics. Piscataway: IEEE, 2017: 7945915. |
| [12] | TAN K, CHEN J, WANG D . Gated Residual Networks with Dilated Convolutions for Monaural Speech Enhancement[J]. IEEE Transactions on Audio, Speech and Language Processing, 2019,27(1):189-198. |
| [13] | OUYANG Z, YU H, ZHU W P , et al. A Fully Convolutional Neural Network for Complex Spectrogram Processing in Speech Enhancement[C]//Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2019: 5756-5760. |
| [14] | PASCUAL S, BONAFONTE A, SERRA J . SEGAN: Speech Enhancement Generative Adversarial Network[C]//Proceedings of the 2017 18th Annual Conference of the International Speech Communication Association: 2017. Baixas: International Speech Communication Association, 2017: 3642-3646. |
| [15] | YUAN J, BAO C . Joint Ideal Ratio Mask and Generative Adversarial Networks for Monaural Speech Enhancement[C]//Proceedings of the 2019 International Conference on Signal Processing. Piscataway: IEEE, 2019: 276-280. |
| [16] | XIANG Y, BAO C . Speech Enhancement via Generative Adversarial LSTM Networks[C]//Proceedings of the 2018 16th International Workshop on Acoustic Signal Enhancement. Piscataway: IEEE, 2018: 46-50. |
| [17] | HAO X, SHAN C, XU Y , et al. An Attention-based Neural Network Approach for Single Channel Speech Enhancement[C]//Proceedings of the IEEE 2019 International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2019: 6895-6899. |
| [18] | VASWANI A, SHAZEER N, PARMAR N , et al. Attention Is All You Need[C]//Advances in Neural Information Processing Systems 30: 2017. Vancouver: Neural Information Processing Systems Foundation, 2017: 5999-6009. |
| [19] | 袁文浩, 梁春燕, 娄迎曦 , 等. 一种时频平滑的深度神经网络语音增强方法[J]. 西安电子科技大学学报, 2019,46(4):130-136. |
| YUAN Wenhao, LIANG Chunyan, LOU Yingxi , et al. Speech Enhancement Method Based on the Time-frequency Smoothing Deep Neural Network[J]. Journal of Xidian University, 2019,46(4):130-136. | |
| [20] | 袁文浩, 娄迎曦, 夏斌 , 等. 基于卷积门控循环神经网络的语音增强方法[J]. 华中科技大学学报(自然科学版), 2019,47(4):13-18. |
| YUAN Wenhao, LOU Yingxi, XIA Bin , et al. Speech Enhancement Method Based on Convolutional Gated Recurrent Neural Network[J]. Journal of Huazhong University of Science and Technology:Natural Science Edition, 2019,47(4):13-18. | |
| [21] | RIX A W, BEERENDS J G, HOLLIER M P , et al. Perceptual Evaluation of Speech Quality (PESQ)-a New Method for Speech Quality Assessment of Telephone Networks and Codecs[C]//Proceedings of the 2001 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2001: 749-752. |
| [22] | TAAL C H, HENDRIKS R C, HEUSDENS R , et al. An Algorithm for Intelligibility Prediction of Time-frequency Weighted Noisy Speech[J]. IEEE Transactions on Audio, Speech and Language Processing, 2011,19(7):2125-2136. |
| [1] | ZHANG Shuwei,LI Junmin. Human body detection algorithm in complex monitoring scenes [J]. Journal of Xidian University, 2021, 48(5): 68-77. |
| [2] | CAO Yi,CAI Xiaodong. Effective learning strategy for hard samples [J]. Journal of Xidian University, 2021, 48(3): 99-105. |
| [3] | MEI Shulin,JIA Hairong,WANG Xiaogang,WU Yifeng. Combination of dynamic features with a new mask to optimize neural network speech enhancement [J]. Journal of Xidian University, 2021, 48(3): 91-98. |
| [4] | LIU Jieyi,GONG Maoguo,ZHAN Tao,LI Hao,ZHANG Mingyang. Method for discrimination of false targets in multistation radar systems based on the deep neural network [J]. Journal of Xidian University, 2021, 48(2): 133-138. |
| [5] | ZHANG Hua,GAO Haoran,YANG Xingguo,LI Wenmin,GAO Fei,WEN Qiaoyan. TargetedFool:an algorithm for achieving targeted attacks [J]. Journal of Xidian University, 2021, 48(1): 149-159. |
| [6] | ZHANG Shudong,GAO Haichang,CAO Xiwen,KANG Shuai. Adaptive fast and targeted adversarial attack for speech recognition [J]. Journal of Xidian University, 2021, 48(1): 168-175. |
| [7] | HU Mengxiao,LU Wang,XU Can,LAI Jiazhe. Satellite RCS anomaly detection using the GRU model [J]. Journal of Xidian University, 2019, 46(6): 125-130. |
| [8] | YUAN Wenhao,LIANG Chunyan,LOU Yingxi,FANG Chao,WANG Zhiqiang. Speech enhancement method based on the time-frequency smoothing deep neural network [J]. Journal of Xidian University, 2019, 46(4): 130-136. |
| [9] | JIA Hairong,WANG Weimei,WANG Yan,PEI Junhua. Speech enhancement based on discriminative joint sparse dictionary alternate optimization [J]. Journal of Xidian University, 2019, 46(3): 74-81. |
| [10] | QIAO Ruixiu,CHEN Gang,GONG Guoliang,LU Huaxiang. High performance reconfigurable accelerator for deep convolutional neural networks [J]. Journal of Xidian University, 2019, 46(3): 130-139. |
| [11] | YUAN Wenhao,LOU Yingxi,LIANG Chunyan,WANG Zhiqiang. Speech enhancement method based on the perceptual joint optimization deep neural network [J]. Journal of Xidian University, 2019, 46(2): 89-94. |
| [12] | WANG Dong;JIA Hairong. Speech enhancement using improved phase spectrum compensation [J]. Journal of Xidian University, 2017, 44(3): 83-88. |
| [13] | GUO Xin;JIA Hairong;WANG Dong. Speech enhancement using the improved K-SVD algorithm by subspace [J]. Journal of Xidian University, 2016, 43(6): 109-115. |
| [14] | LI Dawei;YANG Rijie;HAN Jianhui. Study of speech enhancement in the background of ship-radiated noise [J]. Journal of Xidian University, 2016, 43(5): 133-138. |
| [15] | ZHANG Junchang;LIU Haipeng;FAN Yangyu. Speech enhancement method using self-adaptive time-shift and threshold discrete cosine transform [J]. J4, 2014, 41(6): 155-159+194. |
|