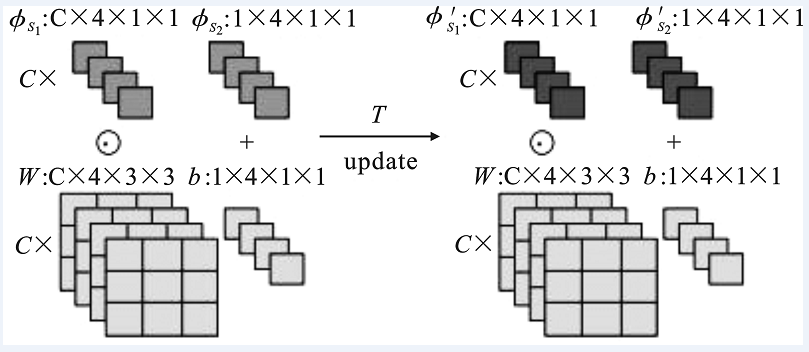
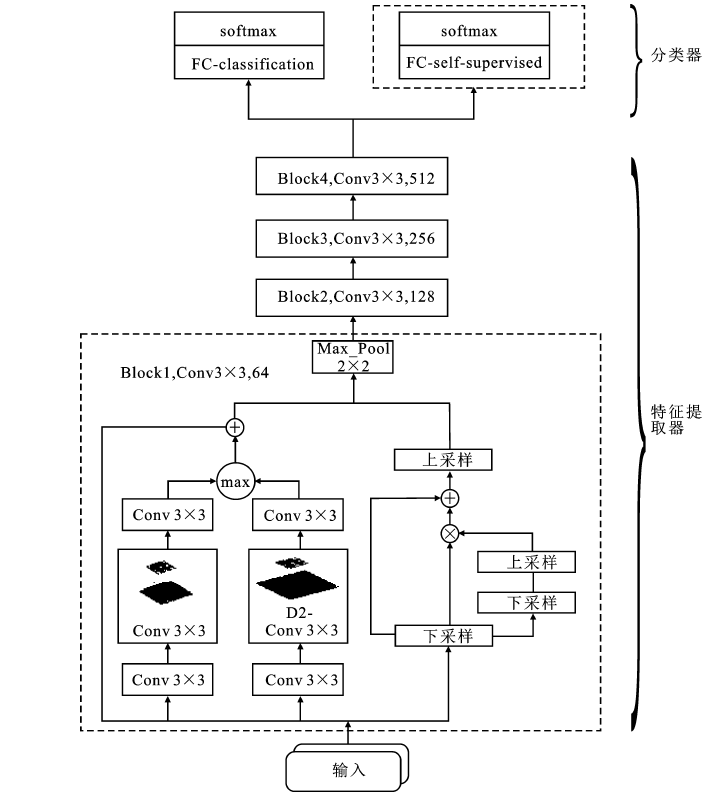
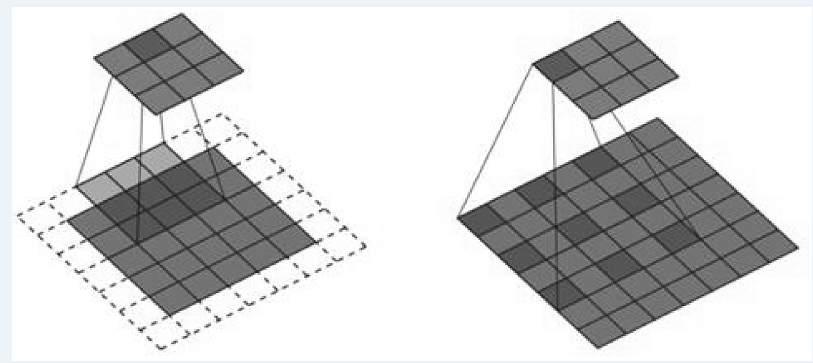
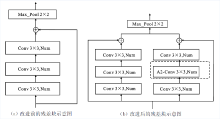
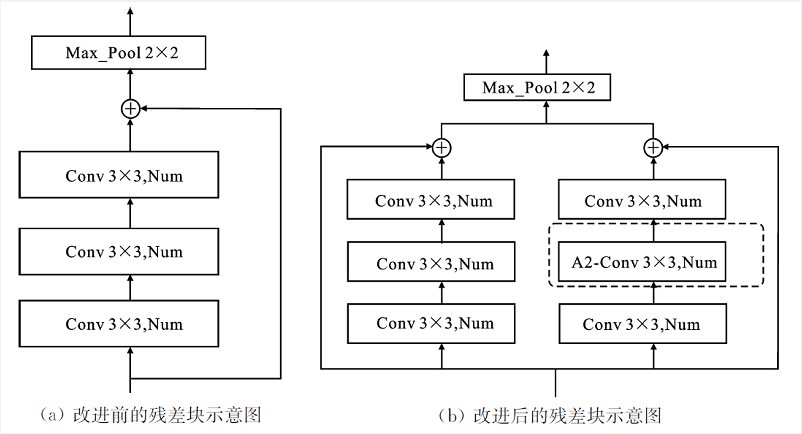
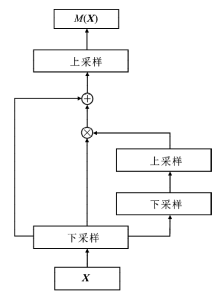
| [1] |
XIONG W, HE Y, ZHANG Y, et al. Fine-Grained Image-To-Image Transformation Towards Visual Recognition[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2020:5840-5849.
|
| [2] |
WANG D L, CHENJ.Supervised Speech Separation Based on Deep Learning:An Overview[J]. IEEE/ACM Transactions on Audio,Speech,and Language Processing, 2018, 26(10):1702-1726.
doi: 10.1109/TASLP.6570655
|
| [3] |
ZHOU M, DUAN N, LIU S, et al. Progress In Neural NLP:Modeling,Learning,And Reasoning[J]. Engineering, 2020, 6(3):275-290.
doi: 10.1016/j.eng.2019.12.014
|
| [4] |
晏媛, 孙俊, 孙晶明, 等. 雷达小样本目标识别方法及应用分析[J]. 系统工程与电子技术, 2021, 43(3):684-692.
|
|
Yan Yuan, Sun Jun, SunJingming,et al.Radar few-shot target recognition method and application analysis[J]. System engineering and electronic technology, 2021, 43(3):684-692.
|
| [5] |
LITJENS G, KOOI T, BEJNORDI B E, et al. A survey on deep learning in medical image analysis[J]. Medical image analysis, 2017, 42:60-88.
doi: 10.1016/j.media.2017.07.005
|
| [6] |
HUANG X, KWIATKOWSKA M, WANG S, et al. Safety Verification Of Deep Neural Networks[C]// International conference on computer aided verification.Heidelberg:Springer, 2017:3-29.
|
| [7] |
FEI-FEI L, FERGUS R, PERONA P. One-Shot Learning Of Object Categories[J]. IEEE transactions on pattern analysis and machine intelligence, 2006, 28(4):594-611.
doi: 10.1109/TPAMI.2006.79
|
| [8] |
ELSKEN T, STAFFLER B, METZEN J H, et al. Meta-Learning Of Neural Architectures For Few-Shot Learning[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2020:12365-12375.
|
| [9] |
CUBUK E D, ZOPH B, MANE D, et al. Autoaugment:Learning augmentation policies from data[EB/OL]. [2018-8-13]https://arxiv.org/pdf/1805.09501.pdf .
|
| [10] |
SNELL J, SWERSKY K, ZEMEL R S. Prototypical networks for few-shot learning[J]. Advances in Neural Information Processing[EB/OL]. [2017-12-4]https//proceedings.newrips.cc/paper/.2010/file/cb8dab7674611f2812ae4290eac70bc42-paper.pbf .
|
| [11] |
SUNG F, YANG Y, ZHANG L, et al. Learning to Compare:Relation Network for Few-Shot Learning[C]// Proceedings of the IEEE conference on computer vision and pattern recognition.Piscataway:IEEE, 2018:1199-1208.
|
| [12] |
FINN C, ABBEEL P, LEVINE S. Model-Agnostic Meta-Learning For Fast Adaptation Of Deep Networks[C]// International Conference on Machine Learning.Sydney:PMLR, 2017:1126-1135.
|
| [13] |
ANTONIOU A, EDWARDS H, STORKEY A. How to train your MAML[EB/OL]. [2019-7-25]https://openreview.net/pdf?id=HJGven05Y7 .
|
| [14] |
ORESHKIN B N, RODRIGUEZ P, LACOSTE A. TADAM:Task dependent adaptive metric for improved few-shot learning[EB/OL].[2018-12-03]https://proceedings.neurips.cc/paper/2018/hash/66808e327dc79d135ba18e051673d906-Abstract.html.
|
| [15] |
KESHARI R, VATSA M, SINGH R, et al. Learning structure and strength of CNN filters for small sample size training[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2018:9349-9358.
|
| [16] |
HUANG J, RATHOD V, SUN C, et al. Speed/Accuracy Trade-Offs For Modern Convolutional Object Detectors[C]// Proceedings of the IEEE conference on computer vision and pattern recognition.Piscataway:IEEE, 2017:7310-7311.
|
| [17] |
ZHU R, ZHANG S, WANG X, et al. ScratchDet:Training Single-Shot Object Detectors From Scratch[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2019:2268-2277.
|
| [18] |
SUN Q, MA L, OH S J, et al. Natural and effective obfuscation by headinpainting[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2018:5050-5059.
|
| [19] |
LIU X, DENG Z, YANG Y. Recent progress in semantic image segmentation[J]. Artificial Intelligence Review, 2019, 52(2):1089-1106.
doi: 10.1007/s10462-018-9641-3
|
| [20] |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab:Semantic Image Segmentation with Deep Convolutional Nets,Atrous Convolution,and Fully Connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4):834-848.
doi: 10.1109/TPAMI.2017.2699184
|
| [21] |
SUN Q, LIU Y, CHUA T S, et al. Meta-Transfer Learning For Few-Shot Learning[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2019:403-412.
|
| [22] |
YU Z, CHEN L, CHENG Z, et al. Transmatch:A Transfer-Learning Scheme For Semi-Supervised Few-Shot Learning[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2020:12856-12864.
|
| [23] |
LIAN D, ZHENG Y, XU Y, et al. Towards Fast Adaptation of Neural Architectures With Meta Learning[EB/OL]. [2020-04-26]https://openreview.net/forum?id=r1eowANFvr .
|
| [24] |
MITCHELL TM. Machine learning,International Edition[EB/OL]. [1997-07-29]https://www.worldcat.org/oclc/61321007 .
|
| [25] |
WANG Y, YAO Q, KWOK J T, et al. Generalizing From A Few Examples:A Survey On Few-Shot Learning[J]. ACM Computing Surveys, 2020, 53(3):1-34.
|
| [26] |
HE K, ZHANG X, REN S, et al. Deep Residual Learning For Image Recognition[C]// Proceedings of the IEEE conference on computer vision and pattern recognition.Piscataway:IEEE, 2016:770-778.
|
| [27] |
PATACCHIOLA M, TURNER K, CROWLEY E J, et al. Bayesian Meta-Learning for the Few-Shot Setting via Deep Kernels[EB/OL]. [2020-12-06]https://proceedings.neurips.cc//paper/2020/file/b9cfe8b6042cf759dc4c0cccb27a6737-Paper.pdf .
|
 ),HAO Xiaohui(
),HAO Xiaohui(