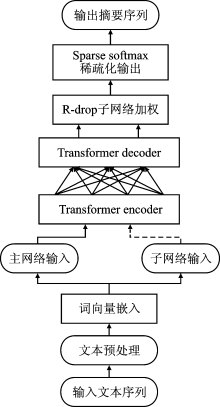
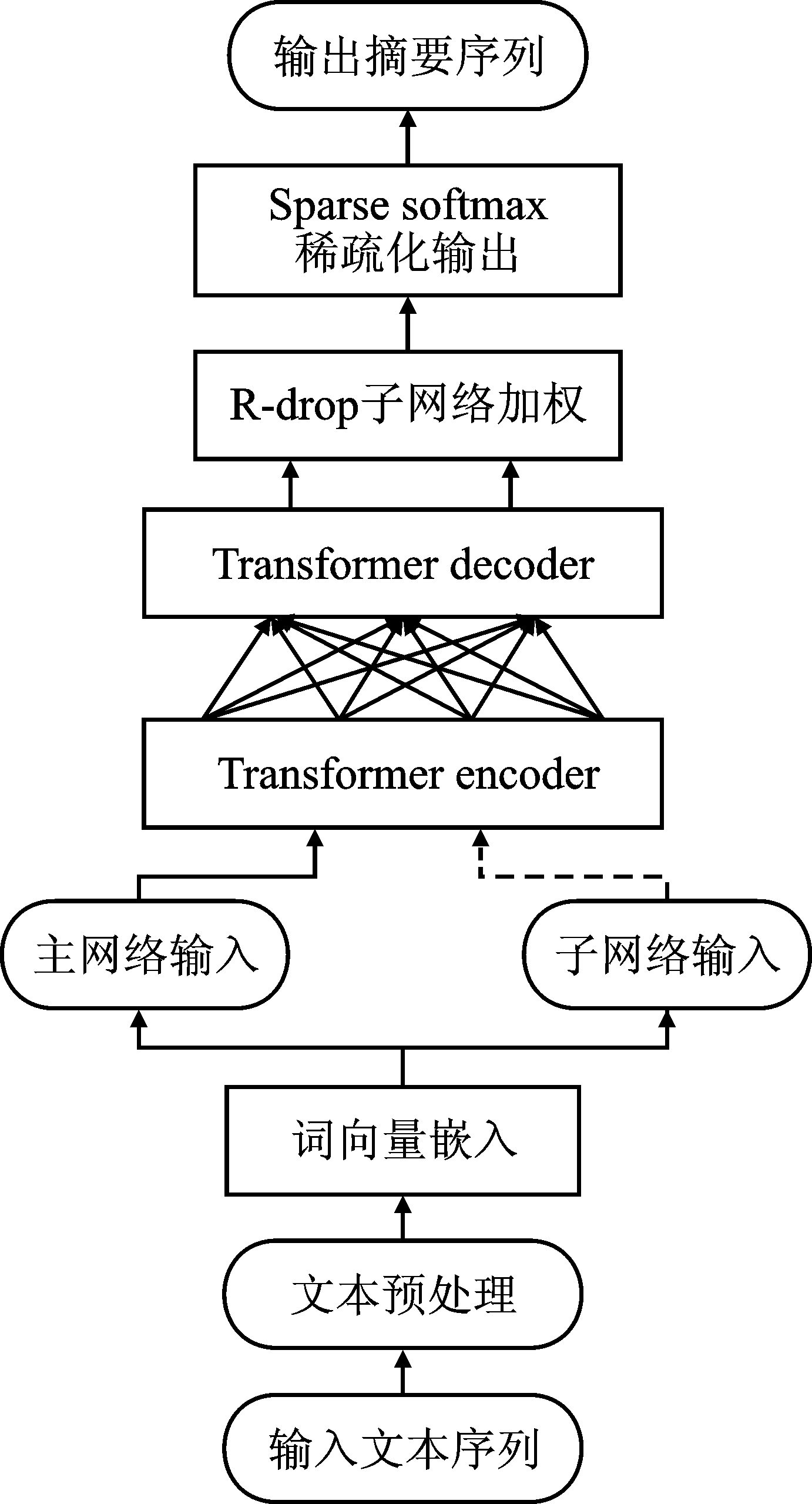
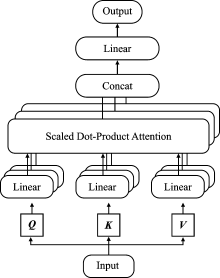
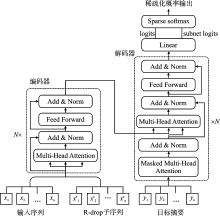
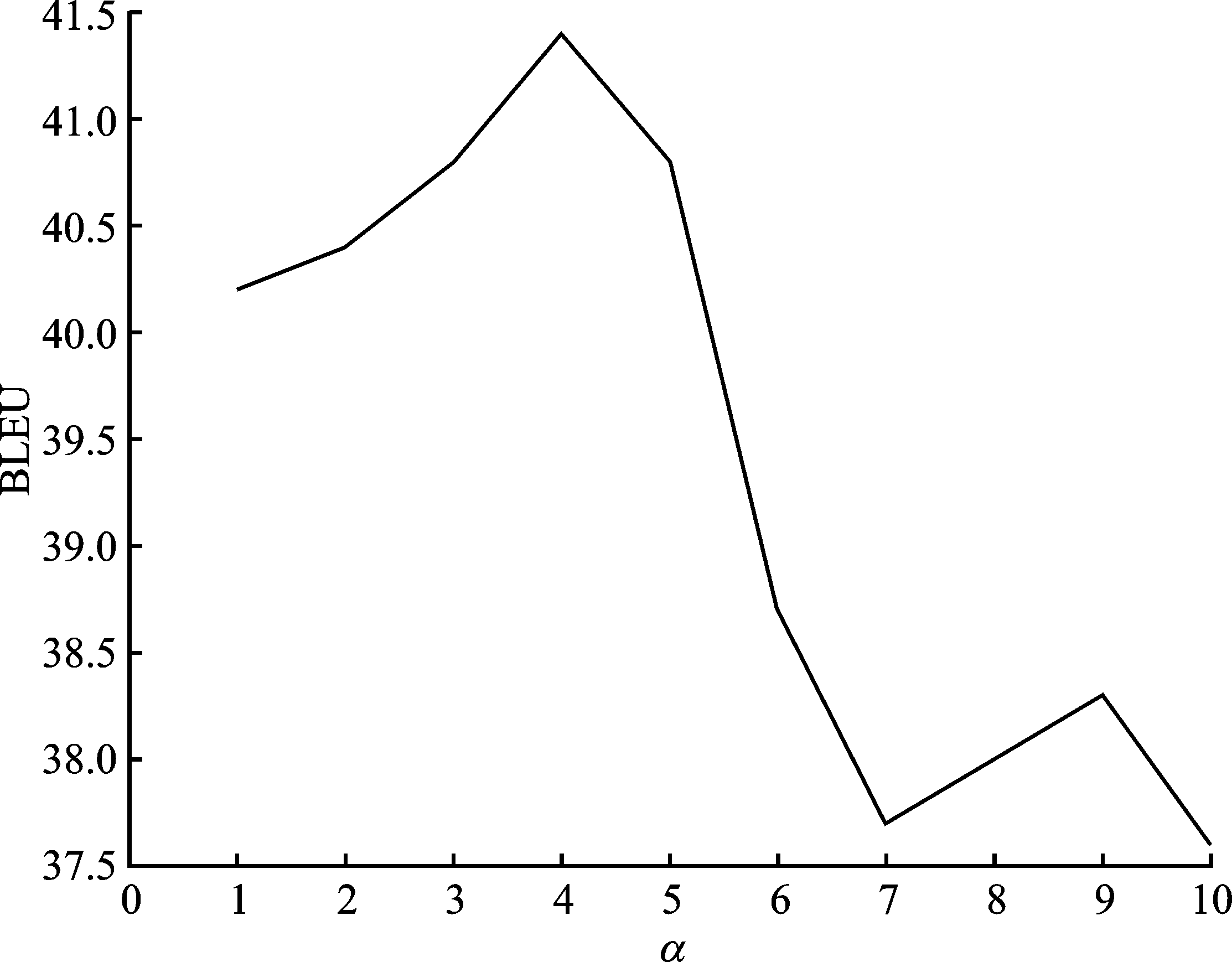
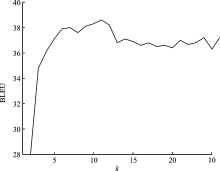
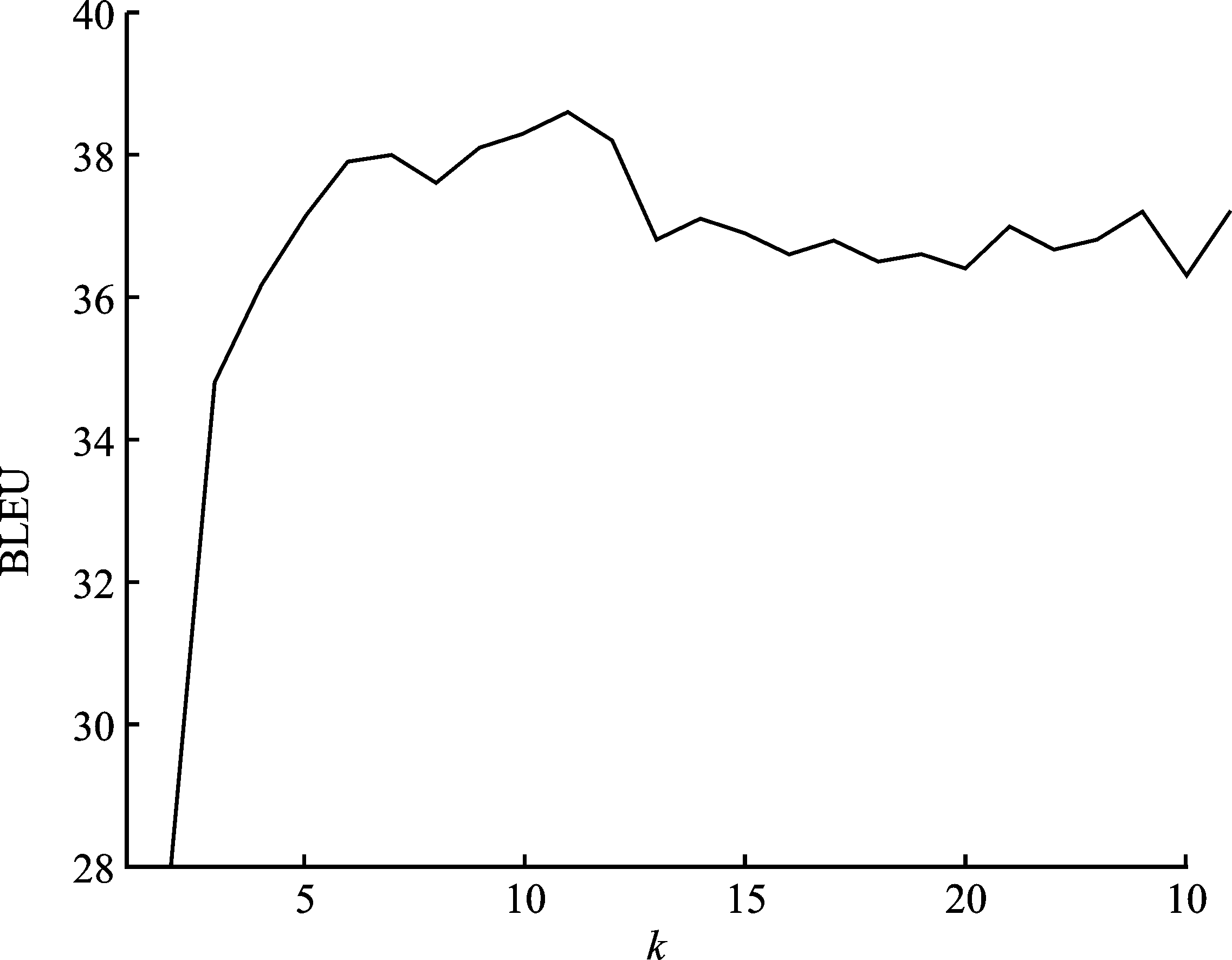
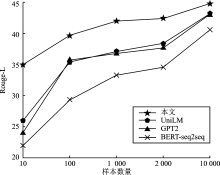
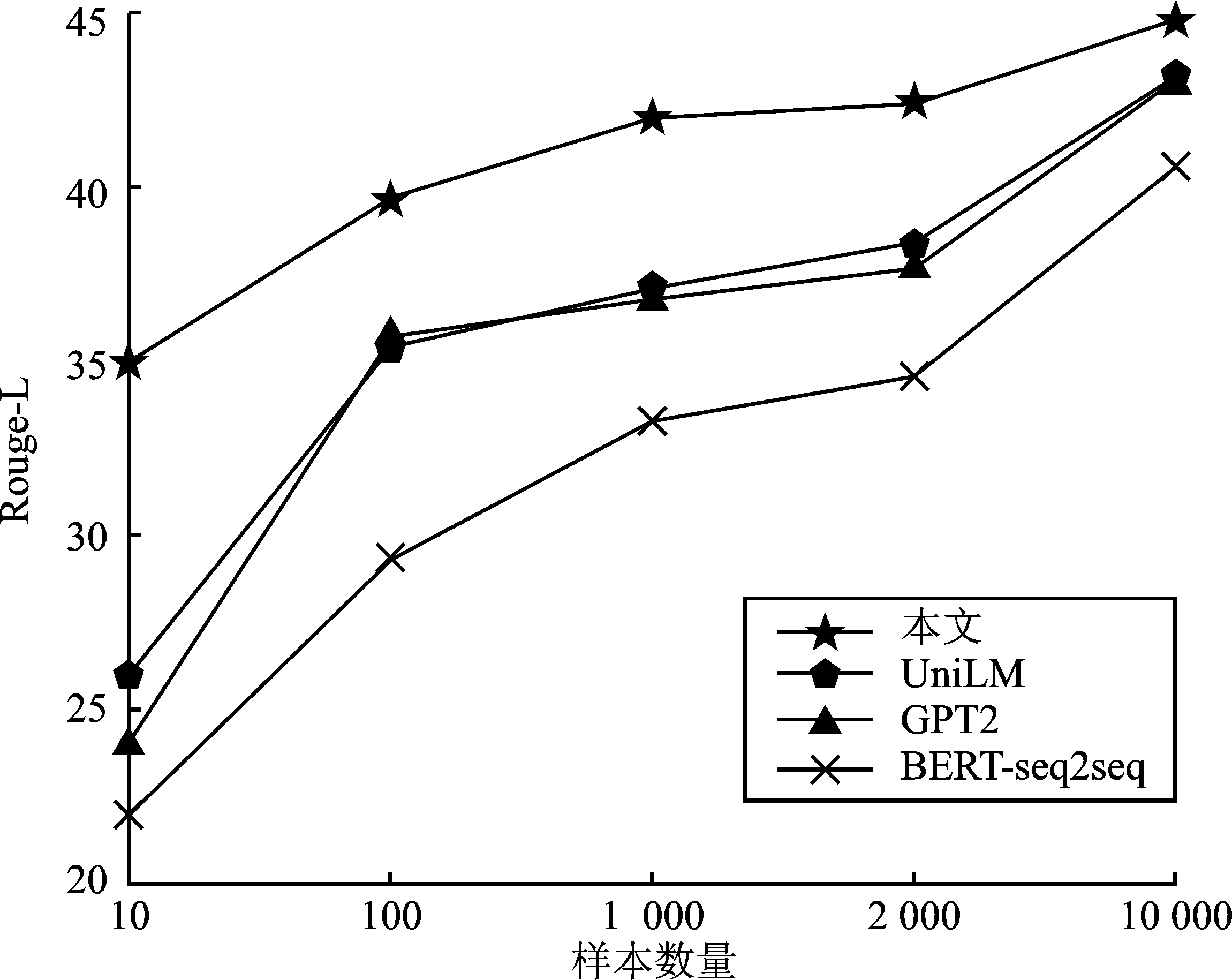
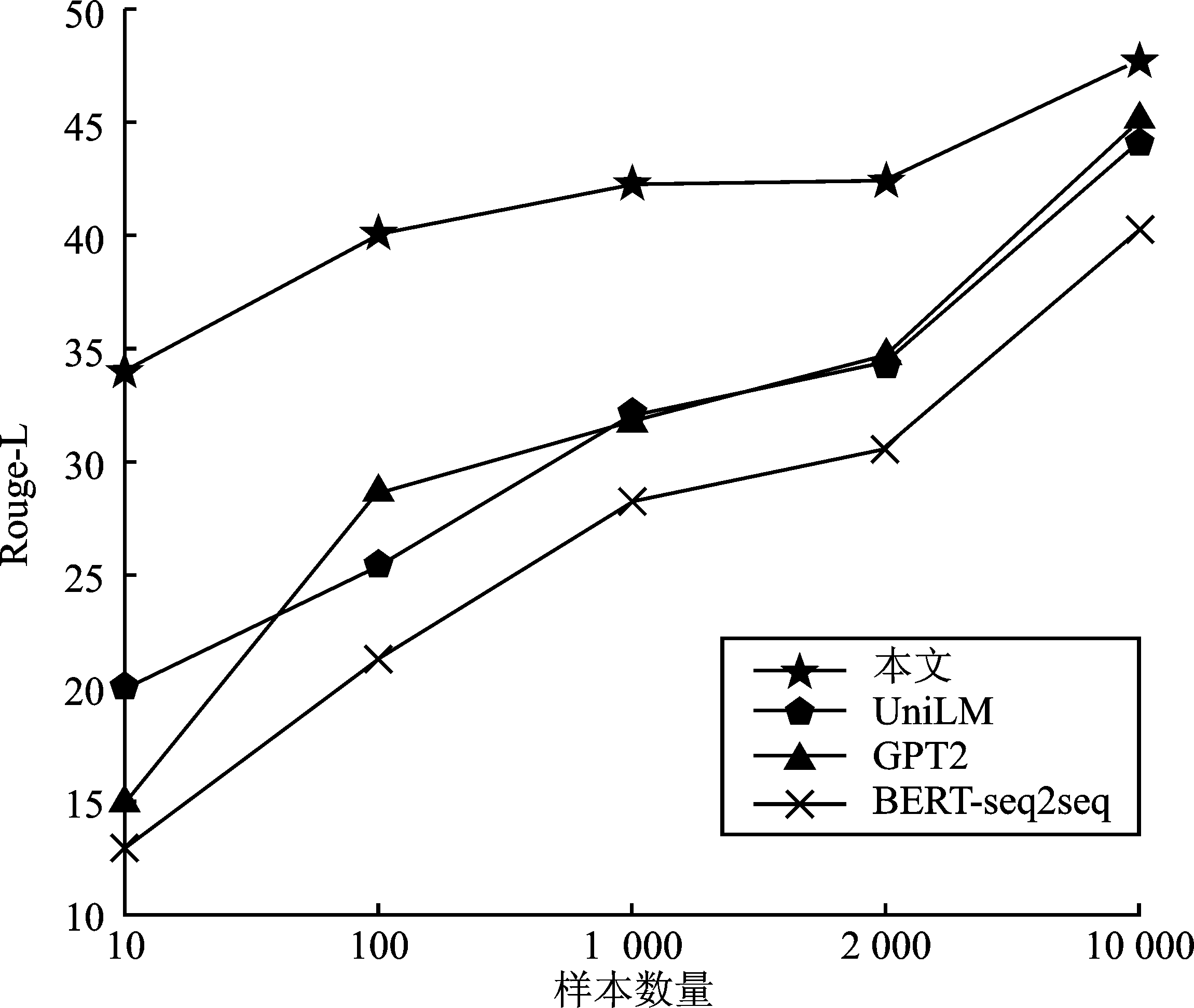
| [1] |
朱永清, 赵鹏, 赵菲菲, 等. 基于深度学习的生成式文本摘要技术综述[J]. 计算机工程, 2021, 47(11):11-21,28.
doi: 10.19678/j.issn.1000-3428.0061174
|
|
Zhu Yongqing, Zhao Peng, Zhao Feifei, et al. Survey on abstractive text summarization technologies based on deep learning[J]. Computer Engineering, 2021, 47(11):11-21,28.
doi: 10.19678/j.issn.1000-3428.0061174
|
| [2] |
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]. Long Beach: The Tthirty-first Conferenceon Neural Information Processing Systems, 2017:6000-6010.
|
| [3] |
Zhang J, Zhao Y, Saleh M, et al. Pegasus:Pretraining with extracted gapsentences for abstractive summarization[C]. Vienna: International Conference on Machine Learning, 2020:11328-11339.
|
| [4] |
Raffel C, Shazeer N, Roberts A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer[J]. Journal of Machine Learning Research, 2020, 21(140):1-67.
|
| [5] |
张紫芸, 王文发, 马乐荣, 等. 预训练文本摘要研究综述[J]. 延安大学学报(自然科学版), 2022, 41(1):98-104.
|
|
Zhang Ziyun, Wang Wenfa, Ma Lerong, et al. A review of pretraining text summarization studies[J]. Journal of Yanan University(Natural Science Edition), 2022, 41(1):98-104.
|
| [6] |
Xue L T, Noah C, Adam R, et al. mT5:A massively multilingual pretrained text-to-text transformer[C]. Mexico City:Association for Computational Linguistics:Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2021:483-498.
|
| [7] |
Wu L, Li J, Wang Y, et al. R-drop:Regularized dropout for neural networks[J]. Advances in Neural Information Processing Systems, 2021, 34(5):10890-10905.
|
| [8] |
Martins A F T, Astudillo R F. From softmax to sparsemax:A sparse model of attention and multilabel classification[C]. New York: Proceedings of the Thirty-third International Conference on International Conference on Machine Learning Volume, 2016:1614-1623.
|
| [9] |
Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[C]. Bangkok: Proceedings of the Twenty-seventh International Conference on Neural Information Processing Systems, 2014:3104-3112.
|
| [10] |
Rush A M, Chopra S, Weston J. A neural attention model for abstractive sentence summarization[C]. Lisbon: Proceedings of the Conference on Empirical Methodsin Natural Language Processing, 2015:379-389.
|
| [11] |
Chopra S, Auli M, Rush A M. Abstractive sentence summarization with attentive recurrent neural networks[C]. San Diego:The Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2016:93-98.
|
| [12] |
李大舟, 于沛. 基于编解码器结构的中文文本摘要[J]. 计算机工程与设计, 2021, 42(3):696-702.
|
|
Li Dazhou, Yu Pei. Abstractive Chinese text summarization based on encoder-decoder model[J]. Computer Engineering and Design, 2021, 42(3):696-702.
|
| [13] |
高巍, 马辉, 李大舟, 等. 基于双编码器的中文文本摘要技术的研究与实现[J]. 计算机工程与设计, 2021, 42(9):2687-2695.
|
|
Gao Wei, Ma Hui, Li Dazhou, et al. Research and implementation of Chinese text abstract technology based on double encoder[J]. Computer Engineering and Design, 2021, 42(9):2687-2695.
|
| [14] |
张仕森, 孙宪坤, 尹玲, 等. 基于神经网络的文本标题生成原型系统设计[J]. 电子科技, 2021, 34(5):35-41.
|
|
Zhang Shisen, Sun Xiankun, Yin Ling, et al. Design of text title generation prototype system based on neural network[J]. Electronic Science and Technology, 2021, 34(5):35-41.
|
| [15] |
卢佳伟, 陈玮, 尹钟. 融合TextRank算法的中文短文本相似度计算[J]. 电子科技, 2020, 33(10):51-56.
|
|
Lu Jiawei, Chen Wei, Yin Zhong. Chinese short text similarity calculation based on TextRank algorithm[J]. Electronic Science and Technology, 2020, 33(10):51-56.
|
| [16] |
Brown T, Mann B, Ryder N, et al. Language models are fewshot learners[J]. Advances in Neural Information Processing Systems, 2020, 33(6):1877-1901.
|
| [17] |
姜梦函, 李邵梅, 郑洪浩, 等. 基于改进位置编码的谣言检测模型[J]. 计算机科学, 2022, 49(8):330-335.
doi: 10.11896/jsjkx.210600046
|
|
Jiang Menghan, Li Shaomei, Zheng Honghao, et al. Rumor detection model based on improved position embedding[J]. Computer Science, 2022, 49(8):330-335.
doi: 10.11896/jsjkx.210600046
|
| [18] |
Dauphin Y N, Fan A, Auli M, et al. Language modeling with gated convolutional networks[C]. Sydney: International Conference on Machine Learning, 2017:933-941.
|
| [19] |
Peters B, Niculae V, Martins A F T. Sparse sequence-to-sequence models[C]. Florence: Proceedings of the Fifty-seventh Annual Meeting of the Association for Computational Linguistics, 2019:1504-1519.
|
| [20] |
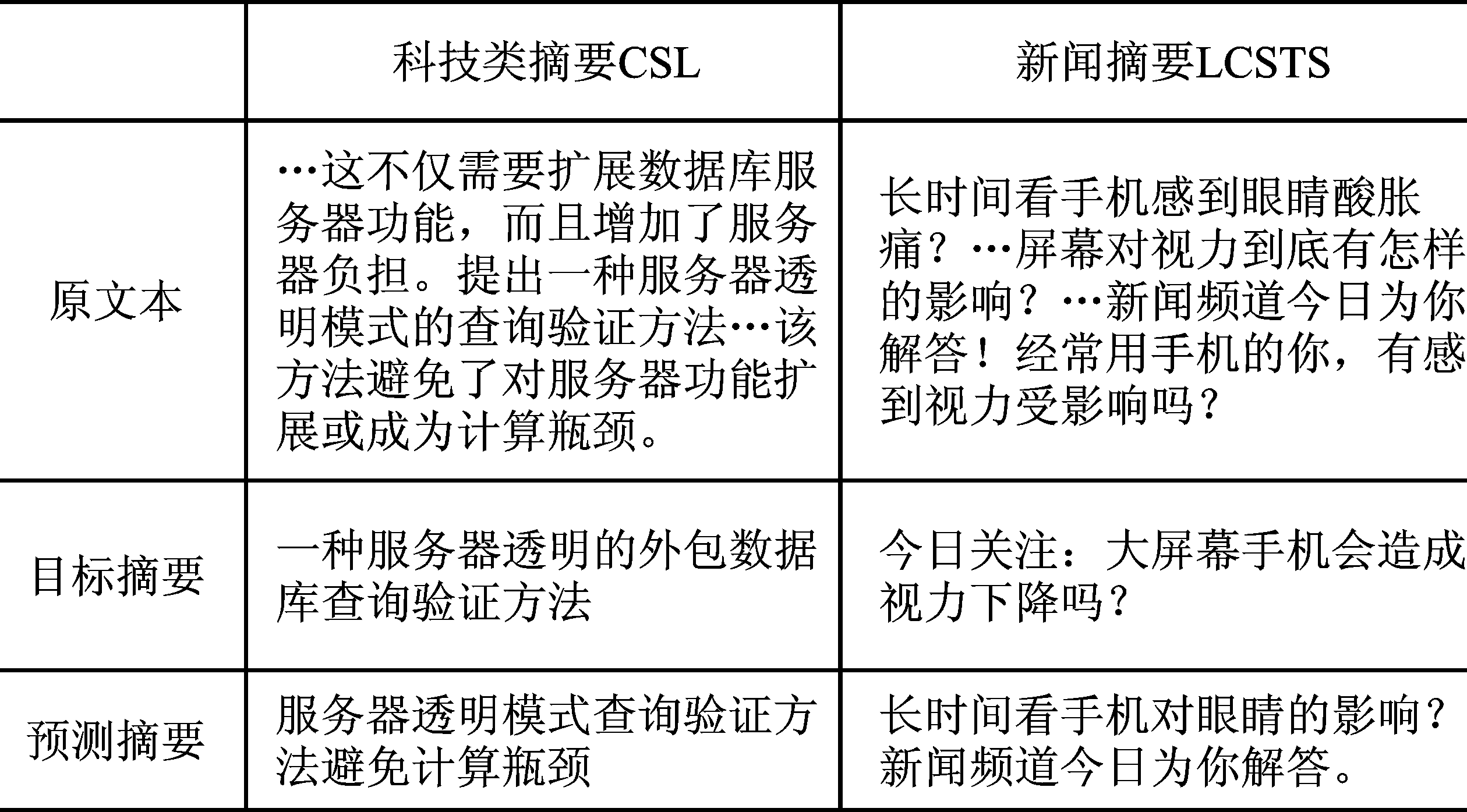
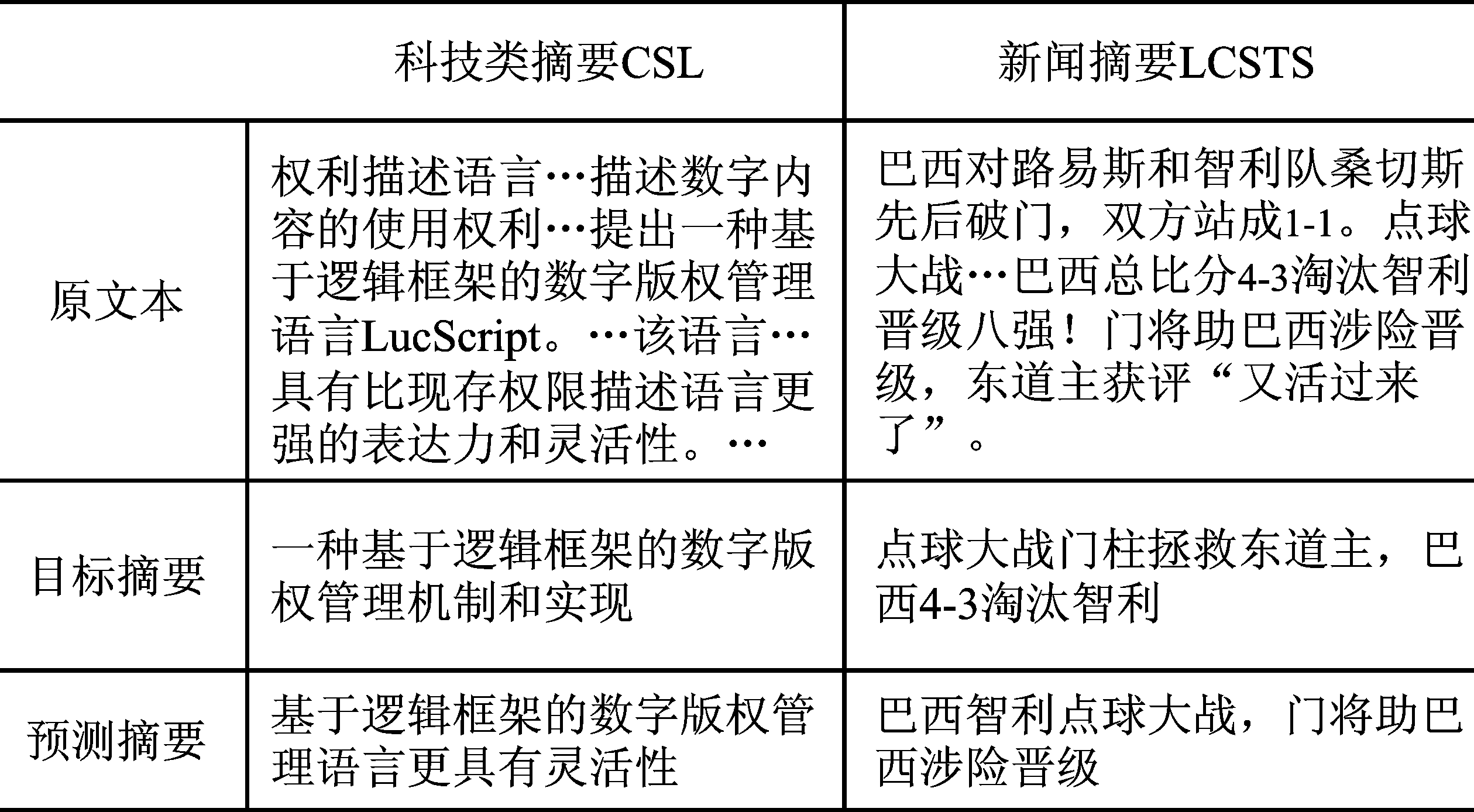
Hu B T, Chen Q C, Zhu F Z. LCSTS:A large scale Chinese short text summarization dataset[C]. Lisbon: Proceedings of the Conference on Empirical Methods in Neural Language Processing, 2015:1967-1972.
|
| [21] |
Li Y D, Zhang Y Q, Zhao Z, et al. CSL:A large-scale Chinese scientific literature dataset[C]. Gyeongju: Proceedings of the Twenty-ninth International Conferenceon Computational Linguistics, 2022:3917-3923.
|
| [22] |
Papineni K, Roukos S, Ward T, et al. BLEU:A method forautomatic evaluation of machine translation[C]. Philadelphia: Proceedings of the Fortieth Annual Meeting ofthe Association for Computational Linguistics, 2002:311-318.
|
| [23] |
Lin C Y. Rouge:A package for automatic evaluation of summaries[C]. Barcelona: The Workshop on Text Summarization Branches Out, 2004:74-81.
|
| [24] |
Sun C, Qiu X, Xu Y, et al. How to fine-tune bert for text classification?[C]. Kunming:Chinese Computational Linguistics: The Eighteenth China National Conference, 2019:194-206.
|
| [25] |
Shazeer N, Stern M. Adafactor:Adaptive learning rates with sublinear memory cost[EB/OL].(2018-04-11) [2023-01-14] https://arxiv.org/pdf/1804.04235v1.pdf.
|
| [26] |
Kingma D P, Diederik P, Jimmy B. Adam:A method for stochastic optimization[EB/OL].(2017-01-30) [2023-01-16] https://arxiv.org/pdf/1412.6980.pdf.
|
| [27] |
Liu Y, Lapata M. Text summarization with pretrainedencoders[C]. Hong Kong: Proceedings of the Conference on Empirical Methods in Natural Language Processing and the Ninth International Joint Conference on Natural Language Processing, 2019:3730-3740.
|
| [28] |
Zhu Q, Li L, Bai L, et al. Chinese text summarization based on fine-tuned GPT2[C]. Xiamen: The Third International Conference on Electronics and Communication Network and Computer Technology, 2022:12671-12675.
|
| [29] |
孙宝山, 谭浩. 基于ALBERT-UniLM模型的文本自动摘要技术研究[J]. 计算机工程与应用, 2022, 58(15):184-190.
doi: 10.3778/j.issn.1002-8331.2104-0382
|
|
Sun Baoshan, Tan Hao. Automatic text summarization technology based on ALBERT-UniLM model[J]. Computer Engineering and Applications, 2022, 58(15):184-190.
doi: 10.3778/j.issn.1002-8331.2104-0382
|