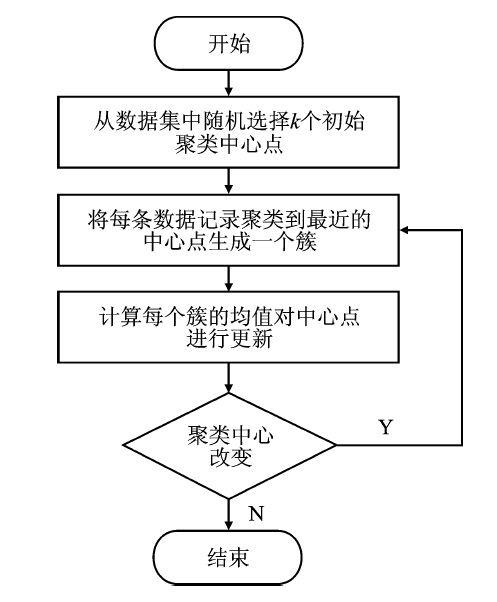
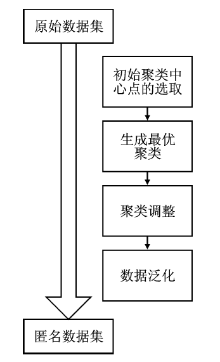
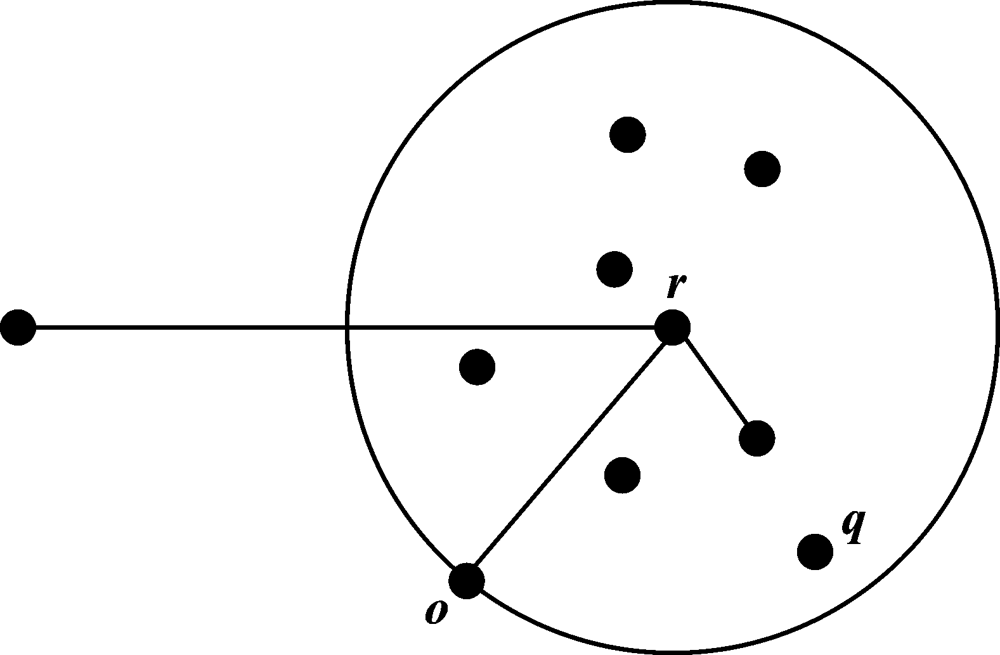
| [1] |
徐波. 面向数据发布的差分隐私保护技术研究[D]. 长沙: 湖南大学, 2018.
|
|
Xu Bo. Research on differential privacy protection technology for data publication[D]. Changsha: Hunan University, 2018.
|
| [2] |
蓝机满. 基于云计算的数据挖掘系统设计[J]. 电子科技, 2019, 32(8):70-74.
|
|
Lan Jiman. Design of data mining system based on cloud computing[J]. Electronic Science and Technology, 2019, 32(8):70-74.
|
| [3] |
孙志冉, 苏航, 梁毅. 一种改进的K-Prototypes聚类算法[J]. 计算机工程与应用, 2020, 56(21):54-59.
doi: 10.3778/j.issn.1002-8331.1912-0106
|
|
Sun Zhiran, Su Hang, Liang Yi. Improved K-Prototypes clustering algorithm[J]. Computer Engineering and Applications, 2020, 56(21):54-59.
doi: 10.3778/j.issn.1002-8331.1912-0106
|
| [4] |
才宇. 基于聚类的隐私保护技术研究[D]. 哈尔滨: 哈尔滨工程大学, 2018.
|
|
Cai Yu. Research on privacy preservation technology based on clustering[D]. Harbin: Harbin Engineering University, 2018.
|
| [5] |
Sweeney L. K-anonymity: A model for protecting privacy[J]. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 2002, 10(5):557-570.
doi: 10.1142/S0218488502001648
|
| [6] |
Machanavajjhala A, Gehrke J, Kifer D, et al. L-diversity: Privacy beyond k-anonymity[C]. Atlanta: The Twenty-second International Conference on Data Engineering, 2006.
|
| [7] |
Li N, Li T, Venkatasubramanian S. T-closeness: Privacy beyond k-anonymity and l-diversity[C]. Istanbul: Proceedings of the IEEE Twenty-third International Conference on Data Engineering, 2007.
|
| [8] |
姜火文, 曾国荪, 马海英. 面向表数据发布隐私保护的贪心聚类匿名方法[J]. 软件学报, 2017, 28(2):341-351.
|
|
Jiang Huowen, Zeng Guosun, Ma Haiying. Greedy clustering-anonymity method for privacy preservation of table data-publishing[J]. Journal of Software, 2017, 28(2):341-351.
|
| [9] |
陈虹云, 王杰华, 胡兆鹏, 等. 面向医疗数据发布的动态更新隐私保护算法[J]. 计算机科学, 2019, 46(1):206-211.
doi: 10.11896/j.issn.1002-137X.2019.01.032
|
|
Chen Hongyun, Wang Jiehua, Hu Zhaopeng, et al. Privacy preserving algorithm based on dynamic update in medical data publishing[J]. Computer Science, 2019, 46(1):206-211.
doi: 10.11896/j.issn.1002-137X.2019.01.032
|
| [10] |
张王策, 范菁, 王渤茹, 等. 面向缺损数据的(α,k)-匿名模型[J]. 计算机科学, 2020, 47(S1):395-399.
|
|
Zhang Wangce, Fan Jing, Wang Boru, et al. (α,k)-anonymized model for missing data[J]. Computer Science, 2020, 47(S1):395-399.
|
| [11] |
屈晶晶, 蔡英, 范艳芳, 等. 基于k-prototype聚类的差分隐私混合数据发布算法[J]. 计算机科学与探索, 2021, 15(1):109-118.
doi: 10.3778/j.issn.1673-9418.2003048
|
|
Qu Jingjing, Cai Ying, Fan Yanfang, et al. Differential privacy hybrid data publishing algorithm based on k-prototype clustering[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(1):109-118.
doi: 10.3778/j.issn.1673-9418.2003048
|
| [12] |
Hussain S F, Haris M. A k-means based co-clustering (kCC) algorithm for sparse, high dimensional data[J]. Expert Systems with Applications, 2019, 18(5):20-34.
|
| [13] |
Xing K, Hu C Q, Yu J G, et al. Mutual privacy preserving k-means clustering in social participatory sensing[J]. IEEE Transactions on Industrial Informatics, 2017, 13(4):2066-2076.
doi: 10.1109/TII.2017.2695487
|
| [14] |
Zheng W T, Wang Z Y, Lü T T, et al. K-anonymity algorithm based on improved clustering[C]. Guangzhou: Proceedings of the International Conference on Algorithms and Architectures for Parallel Processing, 2018.
|
| [15] |
Sangam R S, Om H. An equi-biased k-prototypes algorithm for clustering mixed-type data[J]. Sādhanā, 2018, 43(3):1-12.
doi: 10.1007/s12046-017-0766-x
|
| [16] |
邹云峰, 张昕, 宋世渊, 等. 基于局部密度的快速离群点检测算法[J]. 计算机应用, 2017, 37(10):2932-2937.
doi: 10.11772/j.issn.1001-9081.2017.10.2932
|
|
Zou Yunfeng, Zhang Xin, Song Shiyuan, et al. Fast outlier detection algorithm based on local density[J]. Journal of Computer Applications, 2017, 37(10):2932-2937.
doi: 10.11772/j.issn.1001-9081.2017.10.2932
|
| [17] |
Li T, Li N, Zhang J, et al. Slicing: A new approach for privacy preserving data publishing[J]. IEEE Transactions on Knowledge and Data Engineering, 2010, 24(3):561-574.
doi: 10.1109/TKDE.2010.236
|
| [18] |
Aggarwal G, Panigrahy R, Feder T, et al. Achieving anonymity via clustering[J]. ACM Transactions on Algorithms, 2010, 6(3):1-19.
|
| [19] |
Yuan Z, Zhang X Y, Feng S. Hybrid data-driven outlier detection based on neighborhood information entropy and its developmental measures[J]. Expert Systems with Applications, 2018, 17(5):243-257.
doi: 10.1016/S0957-4174(99)00038-X
|