

Journal of Xidian University ›› 2024, Vol. 51 ›› Issue (4): 128-138.doi: 10.19665/j.issn1001-2400.20240302
• Computer Science and Technology & Cyberspace Security • Previous Articles Next Articles
GAO Dihui1,2( ), SHENG Lijie1,2(), XU Xiaodong1,2(), MIAO Qiguang1,2()
), SHENG Lijie1,2(), XU Xiaodong1,2(), MIAO Qiguang1,2()
Received:2023-07-10
Online:2024-08-20
Published:2024-03-13
Contact:
SHENG Lijie
E-mail:dhgao@stu.xidian.edu.cn;ljsheng@xidian.edu.cn;xuxiaodong@stu.xidian.edu.cn;qgmiao@xidian.edu.cn
CLC Number:
GAO Dihui, SHENG Lijie, XU Xiaodong, MIAO Qiguang. Joint feature approach for image-text cross-modal retrieval[J].Journal of Xidian University, 2024, 51(4): 128-138.
"
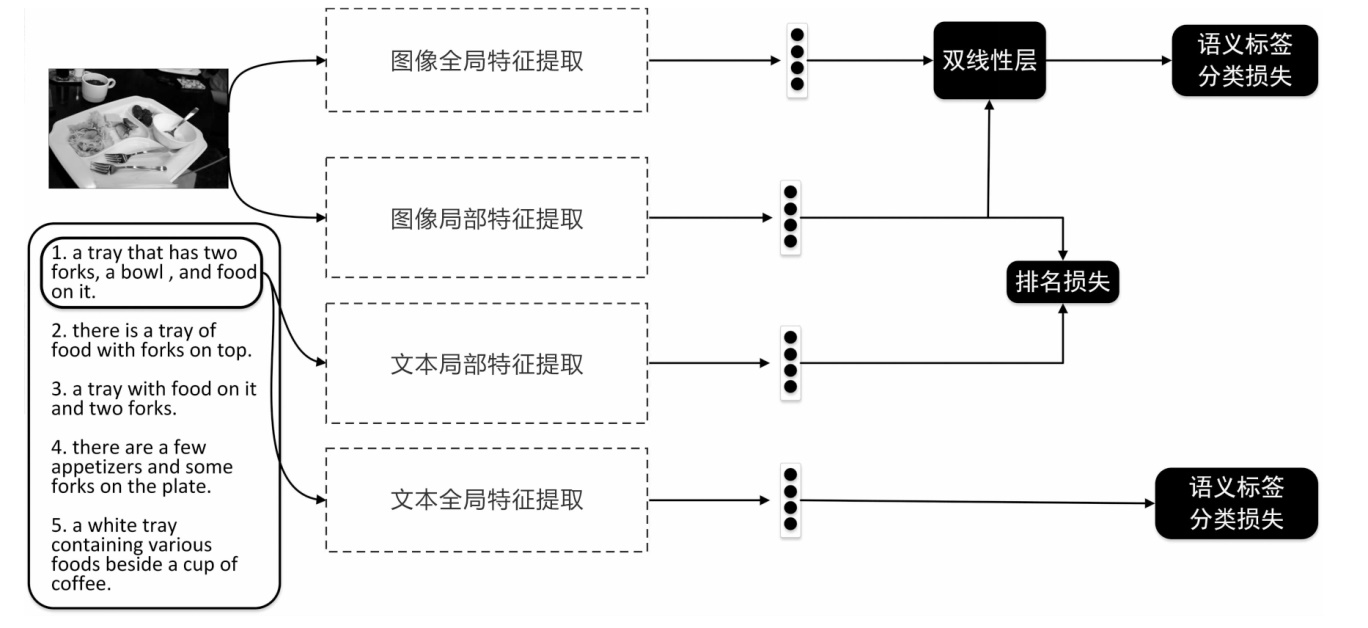
"
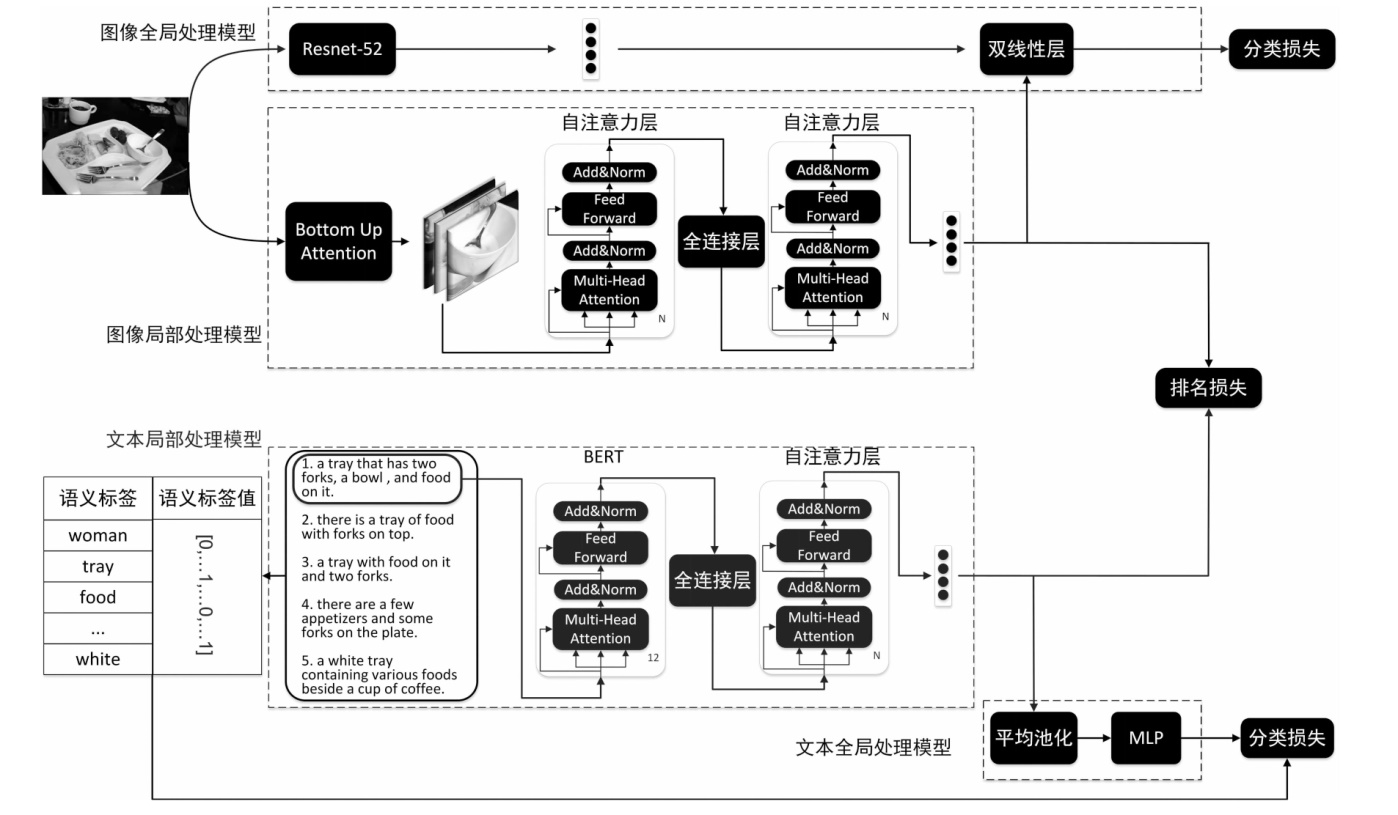
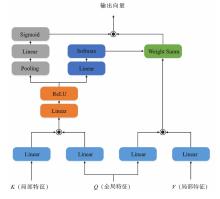
"
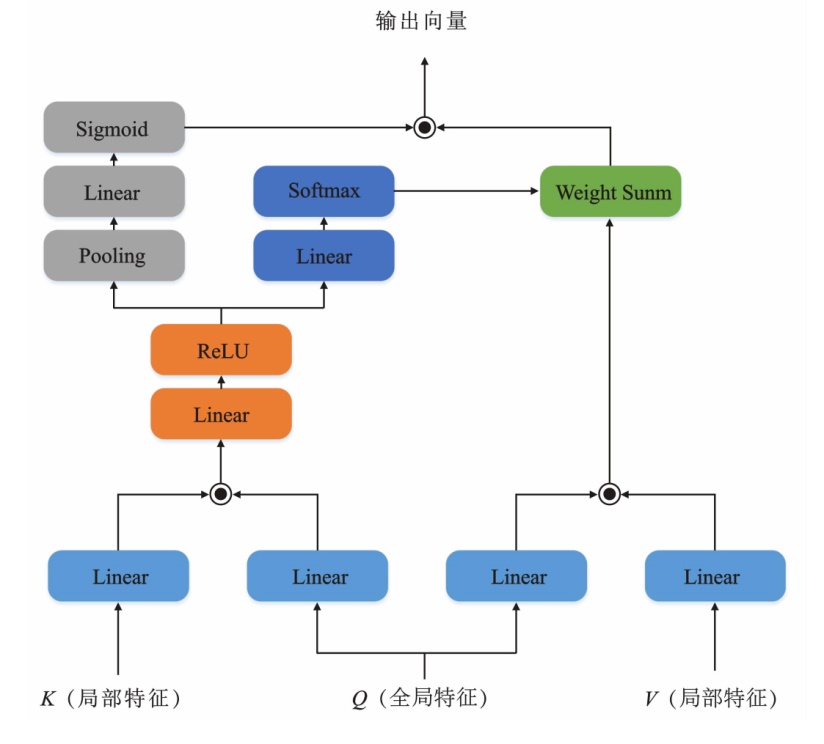
"
| 方法名称 | 文本检索 | 图像检索 | ||||
|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| SCAN(t-i)[ | 61.8 | 87.5 | 93.7 | 45.8 | 74.4 | 83.0 |
| SCAN(优化) | 64.2 | 88.0 | 93.7 | 46.0 | 74.4 | 83.0 |
| BFAN(prob)[ | 65.5 | 89.4 | 47.9 | 77.6 | ||
| BFAN(优化) | 69.0 | 91.1 | 95.7 | 51.8 | 78.4 | 85.5 |
| TERAN[ | 79.2 | 94.4 | 96.8 | 63.1 | 87.3 | 92.6 |
| TERAN(优化) | 83.4 | 96.6 | 98.5 | 65.1 | 88.5 | 93.3 |
"
| 方法名称 | 文本检索 | 图像检索 | ||||
|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| 1 K | ||||||
| VSE++[ | 64.6 | 90.0 | 95.7 | 52.0 | 84.3 | 92.0 |
| SCAN[ | 72.7 | 94.8 | 98.4 | 58.8 | 88.4 | 94.8 |
| IMRAM[ | 76.7 | 95.6 | 98.5 | 61.7 | 89.1 | 95.0 |
| CAMERA[ | 77.5 | 96.3 | 98.8 | 63.4 | 90.9 | 95.8 |
| TERAN[ | 80.2 | 96.6 | 99.0 | 67.0 | 92.2 | 96.9 |
| 文中算法 | 81.4 | 97.0 | 99.0 | 67.2 | 92.4 | 97.0 |
| 5 K | ||||||
| VSE++[ | 41.3 | 71.1 | 81.2 | 30.3 | 59.4 | 72.4 |
| SCAN[ | 50.4 | 82.2 | 90.0 | 38.6 | 69.3 | 80.0 |
| IMRAM[ | 53.7 | 83.2 | 91.0 | 39.7 | 69.1 | 79.8 |
| CAMERA[ | 55.1 | 82.9 | 91.2 | 40.5 | 71.7 | 82.5 |
| TERAN[ | 59.3 | 85.8 | 92.4 | 45.1 | 74.6 | 84.4 |
| 文中算法 | 61.7 | 86.7 | 93.1 | 45.0 | 74.7 | 84.6 |
"
| 方法名称 | 文本检索 | 图像检索 | ||||
|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| VSE++[ | 52.9 | 80.5 | 87.2 | 39.6 | 70.1 | 79.5 |
| SCAN[ | 67.4 | 90.3 | 95.8 | 48.6 | 77.7 | 85.2 |
| IMRAM[ | 74.1 | 93.0 | 96.6 | 53.9 | 79.4 | 87.2 |
| CAMERA[ | 78.0 | 95.1 | 97.9 | 60.3 | 85.9 | 91.7 |
| TERAN[ | 79.2 | 94.4 | 96.8 | 63.1 | 87.3 | 92.6 |
| 文中算法 | 84.3 | 96.1 | 98.4 | 65.9 | 88.8 | 93.3 |
"
| 方法名称 | 文本检索 | 图像检索 | ||||
|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| 基础模型 | 83.4 | 95.8 | 98.0 | 64.3 | 88.0 | 92.9 |
| 无双线性层网络 | 82.4 | 96.1 | 97.8 | 64.3 | 87.0 | 92.4 |
| 图像端+双线性层网络 | 84.3 | 96.1 | 98.4 | 65.9 | 88.8 | 93.3 |
| 文本端+双线性层网络 | 82.0 | 96.1 | 97.8 | 63.9 | 86.8 | 92.6 |
| 图像端+文本端+双线性层网络 | 84.0 | 95.8 | 98.0 | 64.9 | 88.2 | 92.7 |
"
| 方法名称 | 文本检索 | 图像检索 | ||||
|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| 局部排名损失+全局排名损失 | 81.0 | 95.2 | 97.6 | 64.2 | 87.8 | 92.7 |
| 局部排名损失+全局分类损失 | 84.3 | 96.1 | 98.4 | 65.9 | 88.8 | 93.3 |
| [1] | WANG L, LI Y, LAZEBNIK S. Learning Deep Structure-Preserving Image-Text Embeddings[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE, 2016:5005-5013. |
| [2] | KARPATHY A, LI F. Deep Visual-Semantic Alignments for Generating Image Descriptions[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE, 2015:3128-3137. |
| [3] | LEE K H, CHEN X, HUA G, et al. Stacked Cross Attention for Image-Text Matching[C]//Proceedings of European Conference on Computer Vision. Heidelberg:Springer, 2018:201-216. |
| [4] | KIROS R, SALAKHUTDINOV R, ZEMEL R S. Unifying Visual-Semantic Embeddings with Multimodal Neural Language Models(2014)[J/OL].[2014-11-10]. https://arxiv.org/abs/1411.2539. |
| [5] | FAGHRI F, FLEET D J, KIROS J R, et al. VSE++:Improving Visual-Semantic Embeddings with Hard Negatives(2017)[J/OL].[2017-07-18]. https://arxiv.org/abs/1707.05612. |
| [6] | QU L, LIU M, CAO D, et al. Context-Aware Multi-View Summarization Network for Image-Text Matching[C]//Proceedings of the 28th ACM International Conference on Multimedia. New York: ACM, 2020:1047-1055. |
| [7] | MESSINA N, AMATO G, ESULI A, et al. Fine-Grained Visual Textual Alignment for Cross-Modal Retrieval Using Transformer Encoders[J]. ACM Transactions on Multimedia Computing,Communications and Applications, 2021, 17(4):1-23. |
| [8] | ZHANG K, MAO Z, WANG Q, et al. Negative-Aware Attention Framework for Image-Text Matching[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE, 2022:15661-15670. |
| [9] | PAN Z, WU F, ZHANG B. Fine-Grained Image-Text Matching by Cross-Modal Hard Aligning Network[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE, 2023:19275-19284. |
| [10] | FU Z, MAO Z, SONG Y, et al. Learning Semantic Relationship Among Instances for Image-Text Matching[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE, 2023:15159-15168. |
| [11] | JIANG D, YE M. Cross-Modal Implicit Relation Reasoning and Aligning for Text-to-Image Person Retrieval[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE, 2023:2787-2797. |
| [12] | HUANG R, LONG Y,HANJ, et al. Nlip:Noise-Robust Language-Image Pre-Training[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI, 2023, 37(1):926-934. |
| [13] | YANG A, PAN J, LIN J, et al. Chinese Clip:Contrastive Vision-Language Pretraining in Chinese(2022)[J/OL].[2022-11-02]. https://arxiv.org/abs/2211.01335. |
| [14] | LI J, SELVARAJU R, GOTMARE A, et al. Align before Fuse:Vision and Language Representation Learning with Momentum Distillation[J]. Advances in Neural Information Processing Systems, 2021,34:9694-9705. |
| [15] | LI J, LI D, XIONG C, et al. Blip:Bootstrapping Language-Image Pre-Training for Unified Vision-Language Understanding and Generation[C]//International Conference on Machine Learning. New York: PMLR, 2022:12888-12900. |
| [16] | LI J, LI D, SAVARESE S, et al. BLIP-2:Bootstrapping Language-Image Pre-Training with Frozen Image Encoders and Large Language Models[C]//Proceedings of the 40th International Conference on Machine Learning. New York: PMLR, 2023:19730-19742. |
| [17] | 姜定, 叶茫. 面向跨模态文本到图像行人重识别的Transformer网络[J]. 中国图象图形学报, 2023, 28(5):1384-1395. |
| JIANG Ding, YE Mang. Transformer Network for Cross-Modal Text-to-Image Person Re-Identification[J]. Journal of Image and Graphics, 2023, 28(5):1384-1395. | |
| [18] | QI J, PENG Y, YUAN Y. Cross-Media Multi-Level Alignment with Relation Attention Network(2018)[J/OL].[2018-04-25]. https://arxiv.org/abs/1804.09539. |
| [19] | ZHANG Y, ZHOU W, WANG M, et al. Deep Relation Embedding for Cross-Modal Retrieval[J]. IEEE Transactions on Image Processing, 2020,30:617-627. |
| [20] | JI Z, WANG H, HAN J, et al. Saliency-Guided Attention Network for Image-Sentence Matching[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway:IEEE, 2019:5754-5763. |
| [21] | HE K, ZHANG X, REN S, et al. Deep Residual Learning for Image Recoginition[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE, 2016:770-778. |
| [22] | REN S, HE K, GIRSHICK R, et al. Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6):1137-1149. |
| [23] | ANDERSON P, HE X, BUEHLER C, et al. Bottom-up and Top-down Attention for Image Captioning and Visual Question Answering[C]//Proceedings of IEEE Conference on COMPUTER Vision and Pattern Recognition. Piscataway:IEEE, 2018:6077-6086. |
| [24] | KRISHNA R, ZHU Y, GROTH O, et al. Visual Genome:Connecting Language and Vision Using Crowdsourced Dense Image Annotations[J]. International Journal of Computer Vision, 2017, 123(1):32-73. |
| [25] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is All You Need[C]//Advances in Neural Information Processing Systems. San Diego: NeruIPS, 2017:5998-6008. |
| [26] | DEVLIN J, CHANG M, LEE K, et al. BERT:Pre-Training of Deep Bidirectional Transformers for Language Understanding(2018)[J/OL].[2018-10-11]. https://arxiv.org/abs/1810.04805. |
| [27] | YOUNG P, LAI A, HODOSH M, et al. From Image Descriptions to Visual Denotations:New Similarity Metrics for Semantic Inference over Event Descriptions[J]. Transactions of the Association for Computational Linguistics, 2014, 2(1):67-78. |
| [28] | LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft Coco:Common Objects in Context[C]//Proceedings of the European Conference on Computer Vision. Heidelberg:Springer, 2014:740-755. |
| [29] | LIU C, MAO Z, LIU A, et al. Focus Your Attention:A Bidirectional Focal Attention Network for Image-Text Matching[C]//Proceedings of the 27th ACM International Conference on Multimedia. New York: ACM, 2019:3-11. |
| [30] | CHEN H, DING G, LIU X, et al. Imram:Iterative Matching with Recurrent Attention Memory for Cross-Modal Image-Text Retrieval[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE, 2020:4321-4329. |
| [1] | ZHANG Mingjin, ZHOU Nan, LI Yunsong. Smooth interactive compression network for infrared small target detection [J]. Journal of Xidian University, 2024, 51(4): 1-14. |
| [2] | WAN Pengwu, HUI Xi, CHEN Dongrui, WU Bo. Modulation recognition based on the two-dimensional asynchronous in-phase quadrature histogram [J]. Journal of Xidian University, 2024, 51(4): 78-90. |
| [3] | GUAN Yepeng, SU Guangyao, SHENG Yi. Time series prediction method based on the bidirectional long short-term memory network [J]. Journal of Xidian University, 2024, 51(3): 103-112. |
| [4] | HE Wangpeng, HU Deshun, LI Cheng, ZHOU Yue, GUO Baolong. Siamese network tracking using template updating and trajectory prediction [J]. Journal of Xidian University, 2024, 51(3): 46-54. |
| [5] | LIU Wei, WANG Mengyang, BAI Baoming. Efficient semantic communication method for bandwidth constrained scenarios [J]. Journal of Xidian University, 2024, 51(3): 9-18. |
| [6] | LIU Zhenyan, ZHANG Hua, LIU Yong, YANG Libo, WANG Mengdi. Efficient seed generation method for software fuzzing [J]. Journal of Xidian University, 2024, 51(2): 126-136. |
| [7] | ZHAI Fengwen, SUN Fanglin, JIN Jing. Study of EEG classification of depression by multi-scale convolution combined with the Transformer [J]. Journal of Xidian University, 2024, 51(2): 182-195. |
| [8] | DING Xinmiao, WANG Jiaxing, GUO Wen. Three-dimensional attention-enhanced algorithm for violence scene detection [J]. Journal of Xidian University, 2024, 51(1): 114-124. |
| [9] | LIU Bochong, CAI Huaiyu, WANG Yi, CHEN Xiaodong. Self-supervised contrastive representation learning for semantic segmentation [J]. Journal of Xidian University, 2024, 51(1): 125-134. |
| [10] | XIONG Jingwei, PAN Jifei, BI Daping, DU Mingyang. Multi-scale convolutional attention network for radar behavior recognition [J]. Journal of Xidian University, 2023, 50(6): 62-74. |
| [11] | CAI Ying,ZHANG Meng,LI Xin,ZHANG Yu,FAN Yanfang. Anti-collusion attack image retrieval privacy protection scheme for ASPE [J]. Journal of Xidian University, 2023, 50(5): 156-165. |
| [12] | HOU Yue,ZHENG Xin,HAN Chengyan. Traffic flow prediction method for integrating longitudinal and horizontal spatiotemporal characteristics [J]. Journal of Xidian University, 2023, 50(5): 65-74. |
| [13] | FAN Wentong,LI Zhenyu,ZHANG Tao,LUO Xiangyang. JPEG image steganalysis based on deep extraction of stego noise [J]. Journal of Xidian University, 2023, 50(4): 157-169. |
| [14] | WANG Yuhua,GAO Sheng,ZHU Jianming,HUANG Chen. Efficient deep learning scheme with adaptive differential privacy [J]. Journal of Xidian University, 2023, 50(4): 54-64. |
| [15] | WANG Juan,LIU Zishan,WU Minghu,CHEN Guanhai,GUO Liquan. Multi-scale object detection algorithm combined with super-resolution reconstruction technology [J]. Journal of Xidian University, 2023, 50(3): 122-131. |
|
||