

Journal of Xidian University ›› 2019, Vol. 46 ›› Issue (2): 89-94.doi: 10.19665/j.issn1001-2400.2019.02.015
Previous Articles Next Articles
YUAN Wenhao,LOU Yingxi,LIANG Chunyan,WANG Zhiqiang
Received:2018-09-25
Online:2019-04-20
Published:2019-04-20
CLC Number:
YUAN Wenhao,LOU Yingxi,LIANG Chunyan,WANG Zhiqiang. Speech enhancement method based on the perceptual joint optimization deep neural network[J].Journal of Xidian University, 2019, 46(2): 89-94.
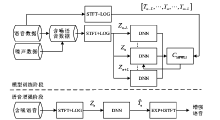
"
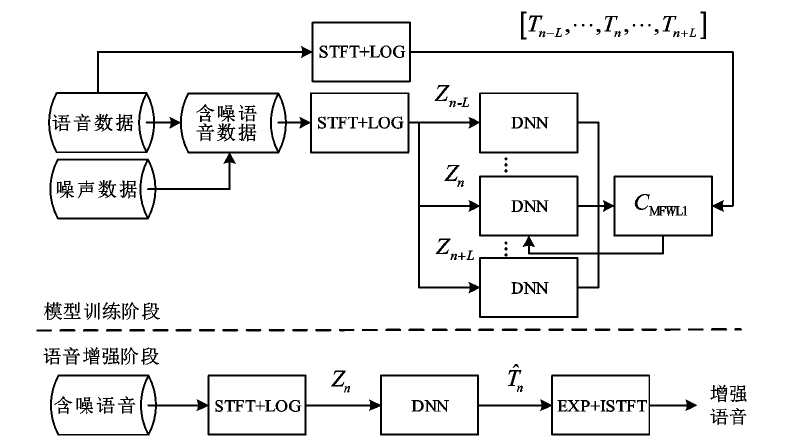
"
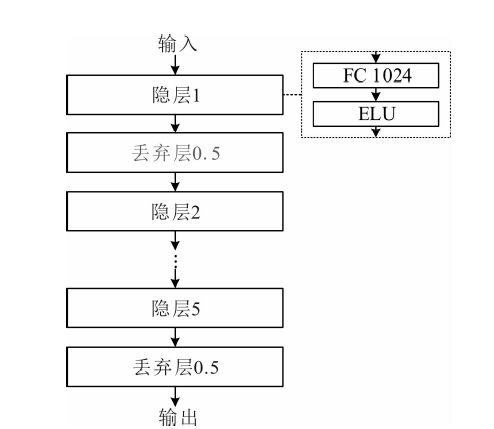
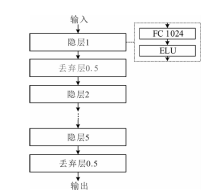
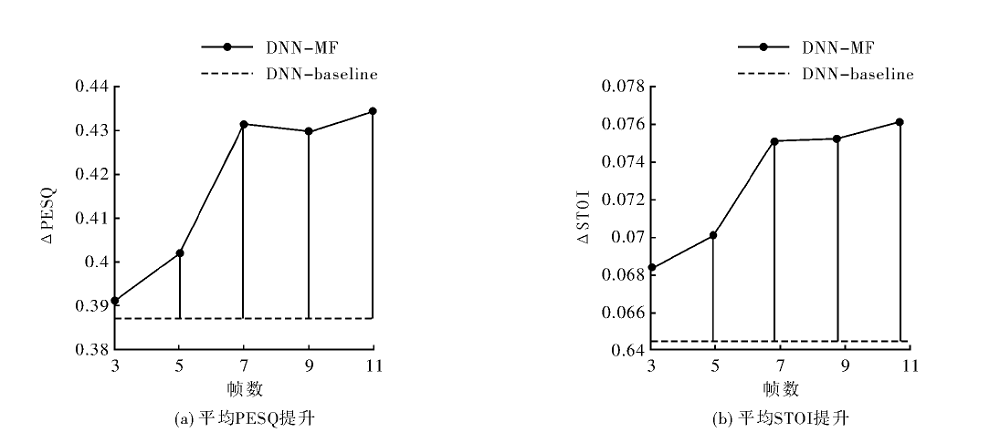
"
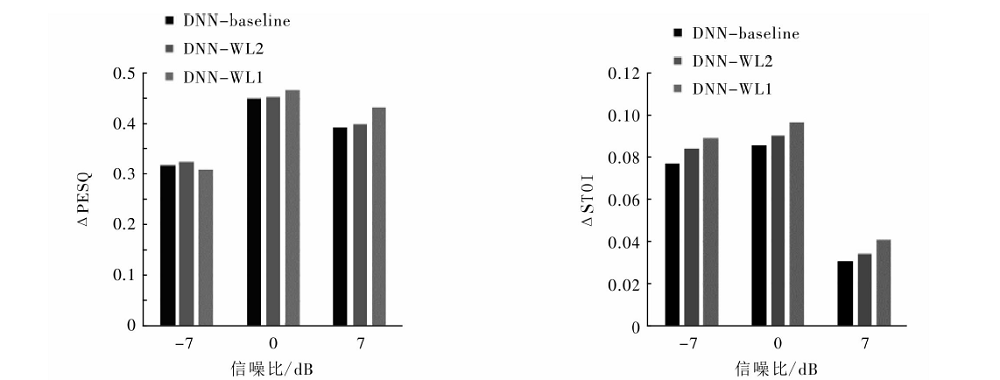
"

"
| [1] |
WANG D M, HANSEN J H L . Single Channel Speech Enhancement Based on Harmonic Estimation Combined with Statistical Based Method to Improve Speech Intelligibility for Cochlear Implant Recipients[J]. Acoustical Society of America Journal, 2017,141(5):3985-3986.
doi: 10.1121/1.4989114 |
| [2] |
刘文举, 聂帅, 梁山 , 等. 基于深度学习语音分离技术的研究现状与进展[J]. 自动化学报, 2016,42(6):819-833.
doi: 10.16383/j.aas.2016.c150734 |
|
LIU Wenju, NIE Shuai, LIANG Shan , et al. Deep Learning Based Speech Separation Technology and Its Developments[J]. Acta Automatica Sinica, 2016,42(6):819-833.
doi: 10.16383/j.aas.2016.c150734 |
|
| [3] |
XU Y, DU J, DAI L R , et al. An Experimental Study on Speech Enhancement Based on Deep Neural Networks[J]. IEEE Signal Processing Letters, 2014,21(1):65-68.
doi: 10.1109/LSP.2013.2291240 |
| [4] |
XU Y, DU J, DAI L R , et al. A Regression Approach to Speech Enhancement Based on Deep Neural Networks[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015,23(1):7-19.
doi: 10.1109/TASLP.2014.2364452 |
| [5] |
CHEN J, WANG Y, YOHO S E , et al. Large-scale Training to Increase Speech Intelligibility for Hearing-impaired Listeners in Novel Noises[J]. Journal of the Acoustical Society of America, 2016,139(5):2604-2612.
doi: 10.1121/1.4948445 pmid: 27250154 |
| [6] |
CHEN J, WANG D . Long Short-term Memory for Speaker Generalization in Supervised Speech Separation[J]. Journal of the Acoustical Society of America, 2017,141(6):4705-4714.
doi: 10.1121/1.4986931 pmid: 28679261 |
| [7] |
WILLIAMSON D S, WANG D L . Time-frequency Masking in the Complex Domain for Speech Dereverberation and Denoising[J]. IEEE/ACM Transactions on Audio , Speech, and Language Processing, 2017,25(7):1492-1501.
doi: 10.1109/TASLP.2017.2696307 |
| [8] |
袁文浩, 孙文珠, 夏斌 , 等. 利用深度卷积神经网络提高未知噪声下的语音增强性能[J]. 自动化学报, 2018,44(4):751-759.
doi: 10.16383/j.aas.2018.c170001 |
|
YUAN Wenhao, SUN Wenzhu, XIA Bin , et al. Improving Speech Enhancement in Unseen Noise Using Deep Convolutional Neural Network[J]. Acta Automatica Sinica, 2018,44(4):751-759.
doi: 10.16383/j.aas.2018.c170001 |
|
| [9] |
LOIZOU P C . Speech Enhancement Based on Perceptually Motivated Bayesian Estimators of the Magnitude Spectrum[J]. IEEE Transactions on Speech and Audio Processing, 2005,13(5):857-869.
doi: 10.1109/TSA.2005.851929 |
| [10] | GAROFOLO J S, LAMEL L F, FISHER W M , et al. TIMIT Acoustic-Phonetic Continuous Speech Corpus: LDC93S1[R/OL]. [2018-09-10]. https://catalog.ldc.upenn.edu/LDC93S1. |
| [11] | HU G N . 100 Nonspeech Environmental Sounds[S/OL]. [ 2018- 09- 03]. http://web.cse.ohio-state.edu/pnl/corpus/HuNonspeech/HuCorpus.html. |
| [12] |
VARGA A, STEENEKEN H J M . Assessment for Automatic Speech Recognition: II. NOISEX-92: a Database and an Experiment to Study the Effect of Additive Noise on Speech Recognition Systems[J]. Speech Communication, 1993,12(3):247-251.
doi: 10.1016/0167-6393(93)90095-3 |
| [13] | YU D, EVERSOLE A, SELTZER M , et al. An Introduction to Computational Networks and the Computational Network Toolkit : MSR-TR-2014-112 [R/OL]. [2018-09-10].https://www.microsoft.com/en-us/research/publication/an-introduction-to-computational-networks-and-the-computational-network-toolkit/. |
| [14] | RIX A W, BEERENDS J G, HOLLIER M P , et al. Perceptual Evaluation of Speech Quality (PESQ)—A New Method for Speech Quality Assessment of Telephone Networks and Codecs[C]// Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE, 2001: 749-752. |
| [15] |
TAAL C H, HENDRIKS R C, HEUSDENS R , et al. An Algorithm for Intelligibility Prediction of Time-frequency Weighted Noisy Speech[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2011,19(7):2125-2136.
doi: 10.1109/TASL.2011.2114881 |
| [1] | WANG Haijun,ZHANG Shengyan,DU Yujie. UAV object tracking via the correlation filter with the response divergence constraint [J]. Journal of Xidian University, 2021, 48(5): 149-155. |
| [2] | ZHANG Fei,MA Shiping,ZHANG Lichao,HE Linyuan,QIU Zhuling,HAN Yongsai. Joint spatial reliability and correlation filter learning for visual tracking [J]. Journal of Xidian University, 2021, 48(5): 167-177. |
| [3] | ZHANG Shuwei,LI Junmin. Human body detection algorithm in complex monitoring scenes [J]. Journal of Xidian University, 2021, 48(5): 68-77. |
| [4] | ZHAN Keyu,SUN Yue,LI Ying. Video super-resolution based on multi-scale 3D convolution [J]. Journal of Xidian University, 2021, 48(5): 8-14. |
| [5] | WANG Xingxin,HU Wei,TAN Jing,ZHU Jiacheng,TANG Shibo. Correlation fault attack on AES [J]. Journal of Xidian University, 2021, 48(4): 192-199. |
| [6] | CAO Yi,CAI Xiaodong. Effective learning strategy for hard samples [J]. Journal of Xidian University, 2021, 48(3): 99-105. |
| [7] | MEI Shulin,JIA Hairong,WANG Xiaogang,WU Yifeng. Combination of dynamic features with a new mask to optimize neural network speech enhancement [J]. Journal of Xidian University, 2021, 48(3): 91-98. |
| [8] | LIU Jieyi,GONG Maoguo,ZHAN Tao,LI Hao,ZHANG Mingyang. Method for discrimination of false targets in multistation radar systems based on the deep neural network [J]. Journal of Xidian University, 2021, 48(2): 133-138. |
| [9] | XU Bin,ZHANG Yongshun,ZHANG Qin,WANG Fuping,ZHENG Guimei. Radar HRRP target recognition based on the multiplicative RNN model [J]. Journal of Xidian University, 2021, 48(2): 49-54. |
| [10] | ZHANG Hua,GAO Haoran,YANG Xingguo,LI Wenmin,GAO Fei,WEN Qiaoyan. TargetedFool:an algorithm for achieving targeted attacks [J]. Journal of Xidian University, 2021, 48(1): 149-159. |
| [11] | ZHANG Shudong,GAO Haichang,CAO Xiwen,KANG Shuai. Adaptive fast and targeted adversarial attack for speech recognition [J]. Journal of Xidian University, 2021, 48(1): 168-175. |
| [12] | FENG Dengguo. On the significance and function of the Xiao-Massey theorem [J]. Journal of Xidian University, 2021, 48(1): 7-13. |
| [13] | YANG Hongyu,ZHANG Xugao. Network security situation adaptive prediction model [J]. Journal of Xidian University, 2020, 47(3): 14-22. |
| [14] | CHANG Xinxu,ZHANG Yang,YANG Lin,KOU Jinqiao,WANG Xin,XU Dongdong. Speech enhancement method based on the multi-head self-attention mechanism [J]. Journal of Xidian University, 2020, 47(1): 104-110. |
| [15] | YANG Lei,YUE Yunze,LI Pucheng,ZHANG Tao,YANG Huan. Sparse representation of large dynamic range SAR imaging for multiple ground moving targets [J]. Journal of Xidian University, 2019, 46(5): 31-40. |
|