

Journal of Xidian University ›› 2020, Vol. 47 ›› Issue (4): 55-63.doi: 10.19665/j.issn1001-2400.2020.04.008
Previous Articles Next Articles
KONG Xin1,2( ),CHEN Gang1,GONG Guoliang1,LU Huaxiang1,2,3,4,Mao Wenyu1
),CHEN Gang1,GONG Guoliang1,LU Huaxiang1,2,3,4,Mao Wenyu1
Received:2020-01-06
Online:2020-08-20
Published:2020-08-14
CLC Number:
KONG Xin,CHEN Gang,GONG Guoliang,LU Huaxiang,Mao Wenyu. High performance multiply-accumulator for the convolutional neural networks accelerator[J].Journal of Xidian University, 2020, 47(4): 55-63.
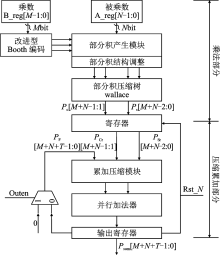
"
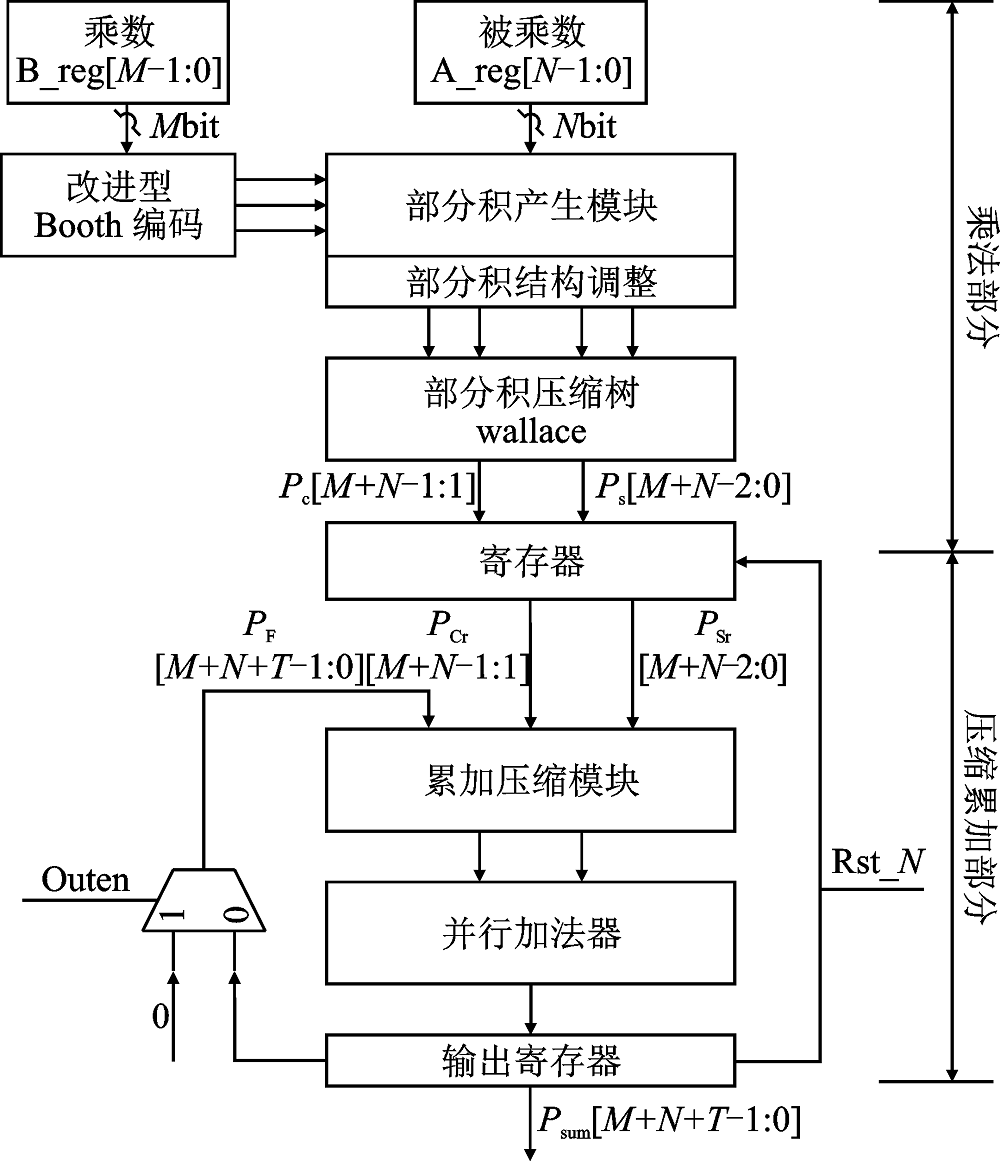
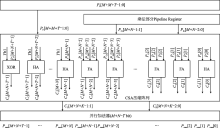
"
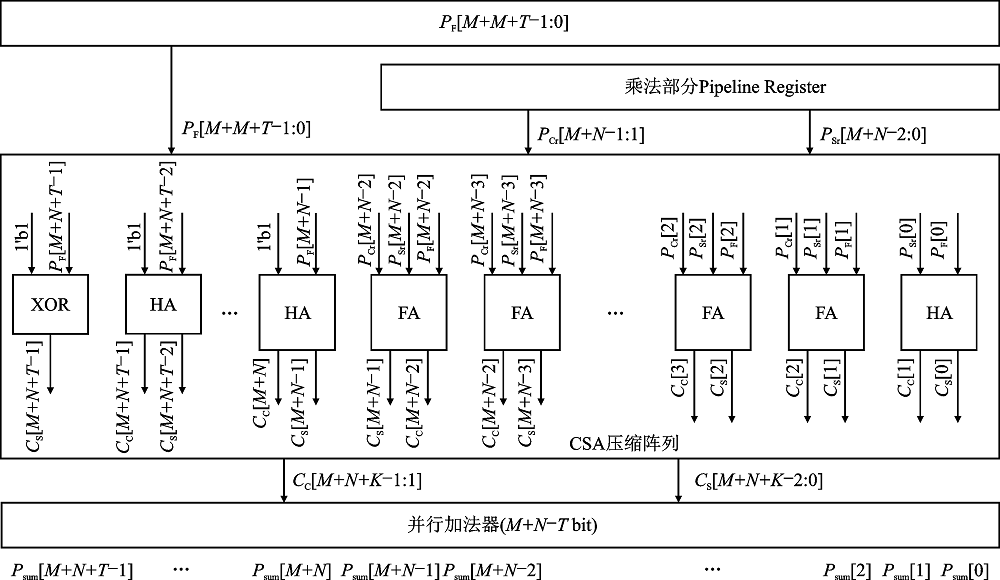
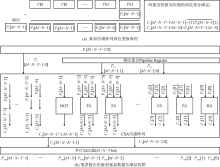
"
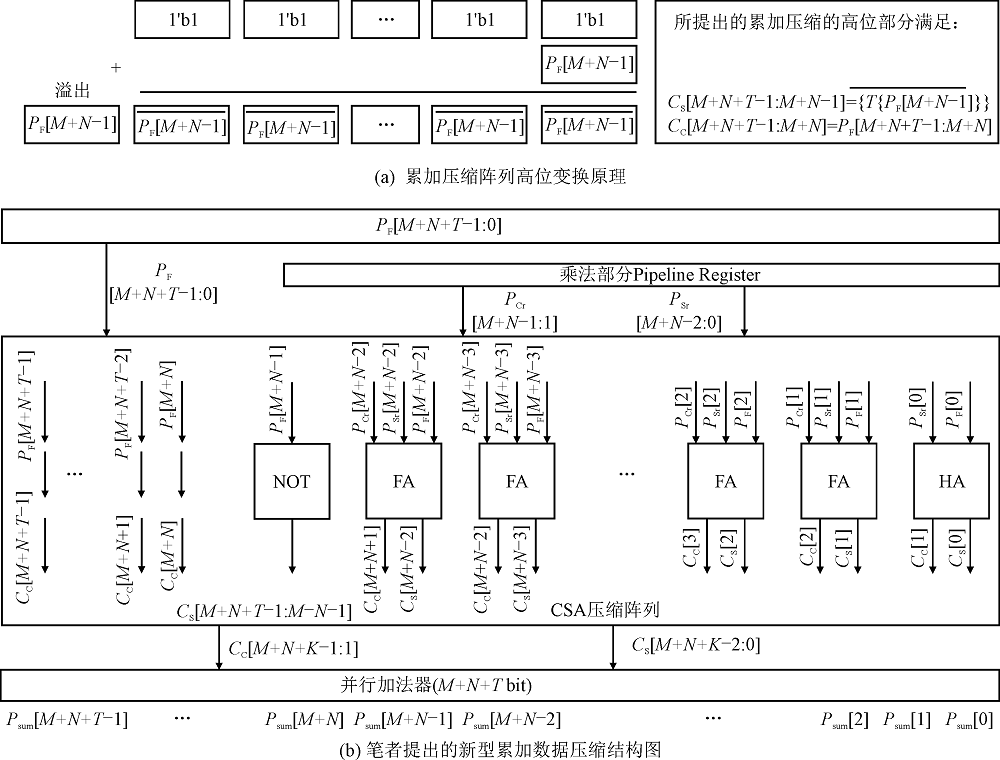

"

"
| operate | SNEG | SONE | SZERO | ||||
|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 0 | 0 | 1 | A | 0 | 1 | 0 | 0 |
| 0 | 1 | 0 | A | 0 | 1 | 0 | 0 |
| 0 | 1 | 1 | 2A | 0 | 0 | 1 | 0 |
| 1 | 0 | 0 | -2A | 1 | 0 | 1 | 0 |
| 1 | 0 | 1 | -A | 1 | 1 | 0 | 0 |
| 1 | 1 | 0 | -A | 1 | 1 | 0 | 0 |
| 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
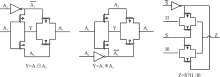
"
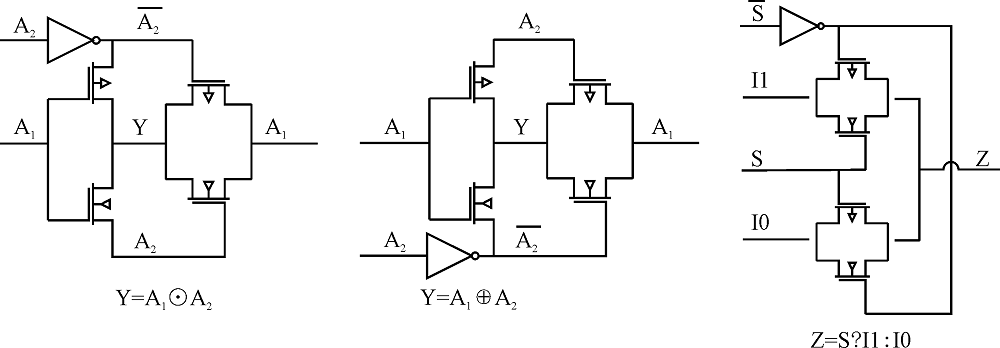

"

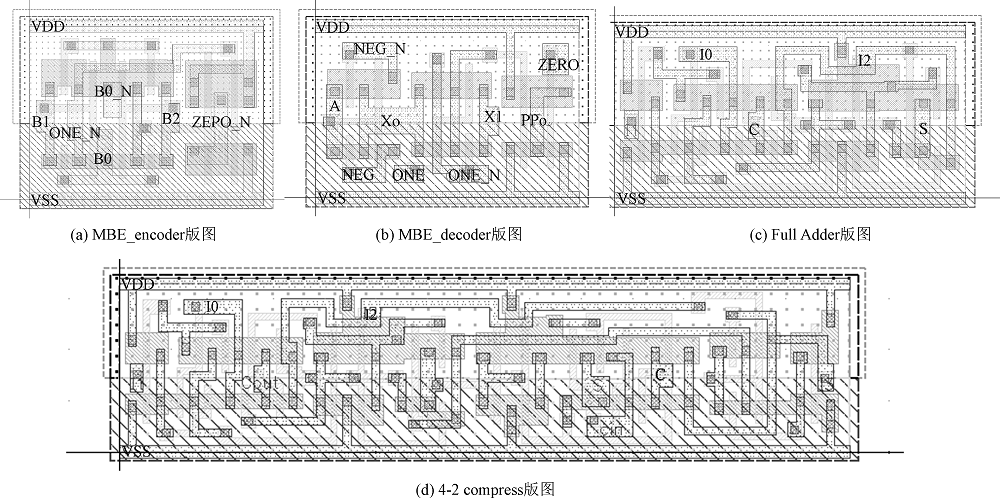
"
"

"
| 性能参数指标 | 参数值 |
|---|---|
| 工艺技术 | SMIC 130nm PDK |
| 版图尺寸/μm2 | 9049.41 |
| 输入位宽/bit | 16×8 |
| 输出位宽/bit | 32 |
| 供电电压/V | 1.08~1.32 |
| 关键路径延迟/ns | 1.173 |
| 时钟频率/MHz | 800 |
| 平均功耗/mW | 4.153 |
"
| 单元电路 | 实现方式 | 关键路径延迟/ns | 版图面积/μm2 | 平均功率/μW,500MHz |
|---|---|---|---|---|
| 改进型Booth编码器 | 传输门 | 0.199 | 18.696 | 0.839 |
| 标准单元库 | 0.253 | 32.275 | 7.417 | |
| MBE-III[ | 0.210 | 40.344 | 9.220 | |
| 改进型Booth译码器 | 传输门 | 0.294 | 16.467 | 0.643 |
| 标准单元库 | 0.454 | 32.275 | 6.834 | |
| MBE-III | 0.521 | 46.215 | 8.711 | |
| CSA单元电路 (全加器) | 传输门 | 0.275 | 22.47 | 3.237 |
| 标准单元库 | 0.407 | 40.34 | 11.287 | |
| 4-2压缩器 | 传输门 | 0.421 | 46.71 | 6.415 |
| 标准单元库 | 0.655 | 80.69 | 21.370 | |
| 所提出的加法器 所提出的加法器 | 传输门 | 1.197 | 1688.54 | 260.699 |
| 标准单元库 | 1.447 | 1958.03 | 583.174 | |
| Brent Kung加法器 | 标准单元库 | 1.493 | 1986.75 | 638.767 |
| 超前进位加法器 | 标准单元库 | 1.486 | 1933.62 | 596.283 |
| Kogge Stone加法器 | 标准单元库 | 1.237 | 3738.54 | 1131.161 |
"
| 名称 | 工艺库 | 实现方式 | 关键路径延迟/ns | 版图面积/μm2 | 功耗/mW,400MHz |
|---|---|---|---|---|---|
| 所提出乘累加器 | SMIC 130nm PDK | 全定制设计方法 | 1.633 | 9049.41 | 1.988 |
| 所提出乘累加器 | SCC013UGHDLVT | 数字后端设计 | 1.880 | 15486.07 | 3.849 |
| 传统乘累加器 | SCC013UGHDLVT | 数字后端设计 | 2.244 | 17358.74 | 4.599 |
| 文献[ | SCC013UGHDLVT | 数字后端设计 | 2.347 | 17077.85 | 4.897 |
| 文献[ | SCC013UGHDLVT | 数字后端设计 | 1.894 | 16518.43 | 3.878 |
| 文献[ | SCC013UGHDLVT | 数字后端设计 | 1.944 | 16273.13 | 4.329 |
| [1] | 乔瑞秀, 陈刚, 龚国良, 等. 一种高性能可重构深度卷积神经网络加速器[J]. 西安电子科技大学学报, 2019,46(3):130-139. |
| QIAO Ruixiu, CHEN Gang, GONG Guoliang, et al. High Performance Reconfigurable Accelerator for Deep Convolutional Neural Networks[J]. Journal of Xidian University, 2019,46(3):130-139. | |
| [2] |
HEIDARI M, SHAMSI H. Analog Programmable Neuron and Case Study on VLSI Implementation of Multi-layer Perceptron (MLP)[J]. Microelectronics Journal, 2019,84:36-47.
doi: 10.1016/j.mejo.2018.12.007 |
| [3] |
TOYAMA Y, YOSHIOKA K, BAN K, et al. An 8 Bit 12.4 TOPS/W Phase-domain MAC Circuit for Energy-constrained Deep Learning Accelerators[J]. IEEE Journal of Solid-State Circuits, 2019,54(10):2730-2742.
doi: 10.1109/JSSC.4 |
| [4] | 沈耀坡, 梁煜, 张为. 一种高性能快速傅里叶变换的硬件设计[J]. 西安电子科技大学学报, 2018, 45(3):63-67+96. |
| SHEN Yaopo, LIANG Yu, ZHANG Wei. Hardware Efficient Fast Fourier Transform Architecture[J]. Journal of Xidian University, 2018, 45(3):63-67+96. | |
| [5] |
SEO Y H, KIM D W. A New VLSI Architecture of Parallel Multiplier-accumulator Based on Radix-2 Modified Booth Algorithm[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2010,18(2):201-208.
doi: 10.1109/TVLSI.2008.2009113 |
| [6] |
HOANG T T, SJALANDER M, LARSSON-EDEFORS P, et al. A High-speed, Energy-efficient Two-cycle Multiply-accumulate (MAC) Architecture and Its Application to a Double-throughput MAC Unit[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2010,57(12):3073-3081.
doi: 10.1109/TCSI.2010.2091191 |
| [7] | EFTAXIOPOULOS N, ZERVAKIS G, PEKMESTZI K, et al. High Performance MAC Designs[C]// Proceedings of the 2014 9th International Design and Test Symposium. Piscataway: IEEE, 2014: 30-35. |
| [8] |
LIU W Q, CAO T, YIN P P, et al. Design and Analysis of Approximate Redundant Binary Multipliers[J]. IEEE Transactions on Computers, 2019,68(6):804-819.
doi: 10.1109/TC.12 |
| [9] |
GUPTA P, GUPTA A, ASATI A, et al. Ultra Low Power MUX Based Compressors for Wallace and Dadda Multipliers in Sub-threshold Regime[J]. American Journal of Engineering and Applied Sciences, 2015,8:702-716.
doi: 10.3844/ajeassp.2015.702.716 |
| [10] |
MEWADA M, ZAVERI M, THAKKER R. Improving the Performance of Transmission Gate and Hybrid CMOS Full Adders in Chain and Tree Structure Architectures[J]. Integration, 2019,69:381-392.
doi: 10.1016/j.vlsi.2019.09.002 |
| [11] |
CARBOGNANI F, BUERGIN F, FELBER N, et al. Transmission Gates Combined with Level-restoring CMOS Gates Reduce Glitches in Low-power Low-frequency Multipliers[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2008,16(7):830-836.
doi: 10.1109/TVLSI.2008.2000457 |
| [12] |
PUDI V, SRIDHARAN K. Low Complexity Design of Ripple Carry and Brent-Kung Adders in QCA[J]. IEEE Transactions on Nanotechnology, 2012,11(1):105-119.
doi: 10.1109/TNANO.2011.2158006 |
| [13] |
KUANG S R, WANG J P, GUO C Y. Modified Booth Multipliers with a Regular Partial Product Array[J]. IEEE Transactions on Circuits and Systems II: Express Briefs, 2009,56(5):404-408.
doi: 10.1109/TCSII.2009.2019334 |
| [14] |
CARBOGNANI F, BUERGIN F, FELBER N, et al. A Low-power Transmission-gate-based 16-bit Multiplier for Digital Hearing Aids[J]. Analog Integrated Circuits and Signal Processing, 2008,56(1-2):5-12.
doi: 10.1007/s10470-007-9086-0 |
| [15] |
SARADA M., SRINIVASULU A, PAL D. Novel, Low-supply, Differential XOR/ XNOR with Rail-to-rail Swing, for Hamming-code Generation[J]. International Journal of Electronics Letters, 2018,6(3):272-287.
doi: 10.1080/21681724.2017.1357761 |
| [16] |
YEH W C, JEN C W. High-speed Booth Encoded Parallel Multiplier Design[J]. IEEE Transactions on Computers, 2000,49(7):692-701.
doi: 10.1109/12.863039 |
| [1] | YU Haoyang,YIN Liang,LI Shufang,LV Shun. Recognition algorithm for the little sample radar modulation signal based on the generative adversarial network [J]. Journal of Xidian University, 2021, 48(6): 96-104. |
| [2] | SUN Yanjing,WEI Li,ZHANG Nianlong,YUN Xiao,DONG Kaiwen,GE Min,CHENG Xiaozhou,HOU Xiaofeng. Person re-identification method combining the DD-GAN and Global feature in a coal mine [J]. Journal of Xidian University, 2021, 48(5): 201-211. |
| [3] | ZHOU Peng,YANG Jun. Semantic segmentation of remote sensing images based on neural architecture search [J]. Journal of Xidian University, 2021, 48(5): 47-57. |
| [4] | YANG Yunhang,MIN Lianquan. Multi-scalefusion sketch recognition model by dilated convolution [J]. Journal of Xidian University, 2021, 48(5): 92-99. |
| [5] | CHEN Changchuan,WANG Haining,HUANG Lian,HUANG Tao,LI Lianjie,HUANG Xiangkang,DAI Shaosheng. Facial expression recognition based on local representation [J]. Journal of Xidian University, 2021, 48(5): 100-109. |
| [6] | SONG Jianfeng,MIAO Qiguang,WANG Chongxiao,XU Hao,YANG Jin. Multi-scale single object tracking based on the attention mechanism [J]. Journal of Xidian University, 2021, 48(5): 110-116. |
| [7] | ZHANG Yuhao,CHENG Peitao,ZHANG Shuhao,WANG Xiumei. Lightweight image super-resolution with the adaptive weight learning network [J]. Journal of Xidian University, 2021, 48(5): 15-22. |
| [8] | HUI Haisheng,ZHANG Xueying,WU Zelin,LI Fenglian. Method for stroke lesion segmentation using the primary-auxiliary path attention compensation network [J]. Journal of Xidian University, 2021, 48(4): 200-208. |
| [9] | WANG Ping,JIANG Yuze,ZHAO Guanghui. Object detection based on the multiscale location Enhancement network [J]. Journal of Xidian University, 2021, 48(3): 85-90. |
| [10] | GUO Zekun,TIAN Long,HAN Ning,WANG Penghui,LIU Hongwei,CHEN Bo. Radar HRRP based few-shot target recognition with CNN-SSD [J]. Journal of Xidian University, 2021, 48(2): 7-14. |
| [11] | CHENG Lei,WANG Yue,TIAN Chunna. Residual attention mechanism for visual tracking [J]. Journal of Xidian University, 2020, 47(6): 148-157. |
| [12] | DANG Jisheng,YANG Jun. 3D model recognition and segmentation based on multi-feature fusion [J]. Journal of Xidian University, 2020, 47(4): 149-157. |
| [13] | LI Kunlun,ZHANG Lu,XU Hongke,SONG Huansheng. Waveletdomain dilated network for fast low-dose CT image reconstruction [J]. Journal of Xidian University, 2020, 47(4): 86-93. |
| [14] | CUI Yanpeng,WANG Yuanhao,HU Jianwei. Detection method for a dynamic small target using the improved YOLOv3 [J]. Journal of Xidian University, 2020, 47(3): 1-7. |
| [15] | WANG Jijun,HAO Ziyu,LI Hongliang. Optimization of memory access for the convolutional neural network training [J]. Journal of Xidian University, 2020, 47(2): 98-107. |
|