

Journal of Xidian University ›› 2021, Vol. 48 ›› Issue (5): 222-230.doi: 10.19665/j.issn1001-2400.2021.05.025
Previous Articles Next Articles
TIAN Chunna( ),YE Yanyu(),SHAN Xiao(),DING Yuxuan(),ZHANG Xiangnan()
),YE Yanyu(),SHAN Xiao(),DING Yuxuan(),ZHANG Xiangnan()
Received:2021-05-21
Online:2021-10-20
Published:2021-11-09
CLC Number:
TIAN Chunna,YE Yanyu,SHAN Xiao,DING Yuxuan,ZHANG Xiangnan. Survey of self-supervised video representation learning[J].Journal of Xidian University, 2021, 48(5): 222-230.
"
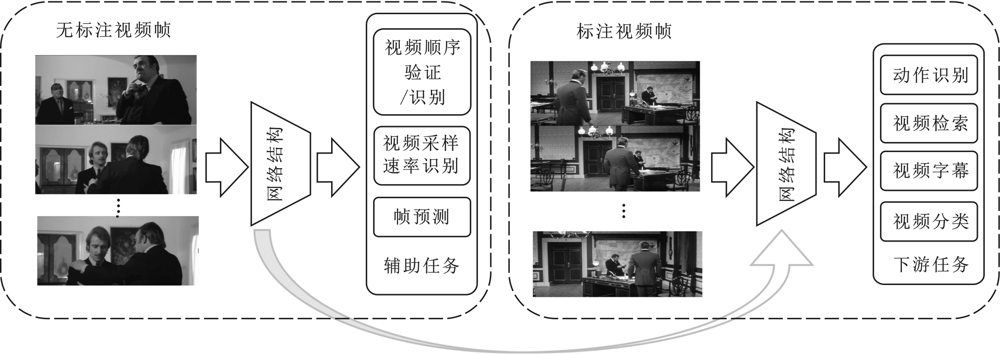
"
| 模型 | 方法 | 骨架网络 | UCF101 | HMDB51 |
|---|---|---|---|---|
| VCOP[ | 顺序识别 | R(2+1) | 72.40 | 30.90 |
| TCG[ | 顺序识别+对比学习 | R(2+1)D | 77.60 | 39.70 |
| PRP[ | 采样速率识别+视频预测 | R(2+1)D | 72.10 | 35.00 |
| Pace[ | 采样速率识别+对比学习 | S3D | 87.10 | 52.60 |
| RTT[ | 顺序验证与识别+采样速率识别 | R(2+1)D | 81.60 | 46.40 |
| TaCo[ | 旋转、顺序、采样速率识别+对比学习 | 3D | 78.85 | 40.60 |
| BFP[ | 对比学习 | 2D+ResNet18-3D | 66.40 | 45.30 |
| VideoMoCo[ | 视频预测 | R(2+1)D | 78.70 | 49.20 |
| HDC[ | 对比学习 | R(2+1)D-10 | 76.20 | 39.80 |
| DSM[ | 对比学习 | ResNet34-3D | 78.20 | 52.80 |
| PCL[ | 旋转角度预测+对比学习 | ResNet18-3D | 82.30 | 43.20 |
| FLAVR[ | 帧插值 | R3D-18 | 63.10 | 23.48 |
"
| 模型 | 方法 | 网络骨架 | Top-1 | Top-5 | Top-10 | Top-20 | Top-50 |
|---|---|---|---|---|---|---|---|
| VCOP[ | 顺序识别 | R3D | 14.1 | 30.3 | 40.0 | 51.1 | 66.5 |
| TCG[ | 顺序识别+对比学习 | R3D | 23.9 | 43.0 | 53.0 | 62.9 | 75.7 |
| PRP[ | 采样速率识别+视频预测 | C3D | 23.2 | 38.1 | 46.0 | 55.7 | 68.4 |
| Pace[ | 采样速率识别+对比学习 | C3D | 31.9 | 49.7 | 59.2 | 68.9 | 80.2 |
| RTT[ | 顺序验证与识别+采样速率识别 | 3D-ResNet18 | 26.1 | 48.5 | 59.1 | 69.9 | 82.8 |
| HDC[ | 对比学习 | C3D | 33.9 | 49.6 | 55.7 | 61.6 | 69.9 |
| IIC[ | 对比学习+光流信息 | ResNet-18 | 42.4 | 60.9 | 69.2 | 77.1 | 86.5 |
| PCL[ | 旋转角度、顺序等识别+对比学习 | R3D | 40.5 | 59.4 | 68.9 | 77.4 | 87.0 |
"
| 模型 | 方法 | 网络骨架 | Top-1 | Top-5 | Top-10 | Top-20 | Top-50 |
|---|---|---|---|---|---|---|---|
| VCOP[ | 顺序识别 | R3D | 7.6 | 22.9 | 34.4 | 48.8 | 68.9 |
| TCG[ | 顺序识别+对比学习 | R3D | 11.2 | 30.6 | 42.9 | 58.1 | 77.0 |
| PRP[ | 采样速率识别+视频预测 | C3D | 10.5 | 27.2 | 40.4 | 56.3 | 75.9 |
| Pace[ | 采样速率识别+对比学习 | C3D | 12.5 | 32.2 | 45.4 | 61.0 | 80.7 |
| HDC[ | 对比学习 | C3D | 14.6 | 28.8 | 36.1 | 44.8 | 57.9 |
| IIC[ | 对比学习+光流信息 | ResNet-18 | 19.7 | 42.9 | 57.1 | 70.6 | 85.9 |
| PCL[ | 旋转角度、顺序等识别+对比学习 | R3D | 16.8 | 38.4 | 53.4 | 68.9 | 85.1 |
| [1] | LIU X, ZHANG F, HOU Z, et al. Self-Supervised Learning:Generative or Contrastive[EB/OL]. [2021-04-30]. https://arxiv.org/abs/2006.08128. |
| [2] | LECUN Y. Self-Supervised Learning(2020)[EB/OL]. [2021-04-21]. https://www.sohu.com/a/372788688_505819. |
| [3] | Huy bery. Self-supervised Learning (2020)[EB/OL]. [2021-04-21]. https://mp.weixin.qq.com/s/Ekh0CqHuXGxKsy7sFropoA. |
| [4] | 成磊, 王玥, 田春娜. 一种添加残差注意力机制的视觉目标跟踪算法[J]. 西安电子科技大学学报, 2020, 47(6):148-157. |
| CHENG Lei, WANG Yue, TIAN Chunna. Residual Attention Mechanism for Visual Tracking[J]. Journal of Xidian University, 2020, 47(6):148-157. | |
| [5] | 孙豪杰, 李苗钰, 章盼盼, 等. 用于面瘫分级的自监督非对称特征学习方法[J]. 西安电子科技大学学报, 2021, 48(3):115-122. |
| SUN Haojie, LI Miaoyu, ZHANG Panpan, et al. Self-Supervised Facial Asymmetry Learning for Automatic Evaluation of Facial Paralysis[J]. Journal of Xidian University, 2021, 48(3):115-122. | |
| [6] | JING L, TIAN Y. Self-Supervised Visual Feature Learning with Deep Neural Networks:A Survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020(99):1. |
| [7] | KIM D, CHO D, KWEON I S. Self-Supervised Video Representation Learning with Space-Time Cubic Puzzles[C]// Proceedings of the AAAI Conference on Artificial Intelligence.Palo Alto:AAAI, 2019:8545-8552. |
| [8] | JING L, YANG X, LIU J, et al. Self-Supervised Spatiotemporal Feature Learning via Video Rotation Prediction (2018)[J/OL]. [2018-11-28]. https://arXiv.org/pdf/1811.11387.pdf. |
| [9] | MISRA I, ZITNICK C L, HEBERT M. Shuffle and Learn:Unsupervised Learning Using Temporal Order Verification[C]// European Conference on Computer Vision.Heidelberg:Springer, 2016:527-544. |
| [10] | WEI D, LIM J J, ZISSERMAN A, et al. Learning and Using the Arrow of Time[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2018:8052-8060. |
| [11] | XU D, XIAO J, ZHAO Z, et al. Self-Supervised Spatiotemporal Learning via Video Clip Order Prediction[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2019:10334-10343. |
| [12] | LIU Y, WANG K, LAN H, et al. Temporal Contrastive Graph for Self-Supervised Video Representation Learning (2021)[J/OL]. [2021-02-01]. https://arxiv.org/abs/2101.00820v1. |
| [13] | YAO Y, LIU C, LUO D, et al. Video Playback Rate Perception for Self-Supervised Spatio-Temporal Representation Learning[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2020:6548-6557. |
| [14] | BENAIM S, EPHRAT A, LANG O, et al. SpeedNet:Learning the Speediness in Videos[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2020:9922-9931. |
| [15] | WANG J, JIAO J, LIU Y H. Self-Supervised Video Representation Learning by Pace Prediction[C]// European Conference on Computer Vision.Heidelberg:Springer, 2020:504-521. |
| [16] | JENNI S, MEISHVILI G, FAVARO P. Video Representation Learning by Recognizing Temporal Transformations (2020)[J/OL]. [2020-07-21]. https://arxiv.org/pdf/2007.10730.pdf. |
| [17] | BAI Y, FAN H, MISRA I, et al. Can Temporal Information Help with Contrastive Self-Supervised Learning? (2020)[J/OL]. [2020-11-25]. https://arxiv.org/pdf/2011.13046.pdf. |
| [18] | 莫凌飞, 蒋红亮, 李煊鹏. 基于深度学习的视频预测研究综述[J]. 智能系统学报, 2018, 13(1):85-96. |
| MO Lingfei, JIANG Hongliang, LI Xuanpeng. Review of Deep Learning-Based Video Prediction[J]. CAAI Transactions on Intelligent Systems, 2018, 13(1):85-96. | |
| [19] | GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative Adversarial Nets[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems.New York:ACM, 2014:2672-2680. |
| [20] | TULYAKOV S, LIU M Y, YANG X, et al. MoCoGAN:Decomposing Motion and Content for Video Generation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2018:1526-1535. |
| [21] | KWON Y H, PARK M G. Predicting Future Frames Using Retrospective Cycle GAN[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2019:1811-1820. |
| [22] | PAN T, SONG Y, YANG T, et al. VideoMoCo:Contrastive Video Representation Learning with Temporally Adversarial Examples (2021)[J/OL]. [2021-03-10]. https://arxiv.org/pdf/2103.05905.pdf. |
| [23] | HE K, FAN H, WU Y, et al. Momentum Contrast for Unsupervised Visual Representation Learning[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2020:9729-9738. |
| [24] | KINGMA D P, WELLING M. Auto-Encoding Variational Bayes (2013)[J/OL]. [2013-12-20]. https://arxiv.org/pdf/1312.6114v3.pdf. |
| [25] | HSIEH J T, LIU B, HUANG D A, et al. Learning to Decompose and Disentangle Representations for Video Prediction (2018)[J/OL]. [2018-06-11]. https://arxiv.org/pdf/1806.04166.pdf. |
| [26] | LI Y, ZENG J, SHAN S, et al. Self-Supervised Representation Learning from Videos for Facial Action Unit Detection[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2019:10924-10933. |
| [27] | SHU Z, SAHASRABUDHE M, GULER A, et al. Deforming Autoencoders:Unsupervised Distentangling of Shape and Appearance[C]// European Conference on Computer Vision.Heidelberg:Springer, 2018:664-680. |
| [28] | WU B, NAIR S, MARTIN-MARTIN R, et al. Greedy Hierarchical Variational Autoencoders for Large-Scale Video Prediction (2021)[J/OL]. [2021-03-06]. https://arxiv.org/pdf/2103.04174v1.pdf. |
| [29] | QIAN R, MENG T, GONG B, et al. Spatiotemporal Contrastive Video Representation Learning (2020)[J/OL]. [2020-08-09]. https://arxiv.org/pdf/2008.03800v3.pdf. |
| [30] | ZHANG Z, CRANDALL D. Hierarchically Decoupled Spatial-Temporal Contrast for Self-Supervised Video Representation Learning (2020)[J/OL]. [2020-11-23]. https://arxiv.org/pdf/2011.11261.pdf. |
| [31] | WANG J, GAO Y, LI K, et al. Enhancing Unsupervised Video Representation Learning by Decoupling the Scene and the Motion (2020)[J/OL]. [2020-09-12]. https://arxiv.org/pdf/2009.05757v3.pdf. |
| [32] | TAO L, WANG X, YAMASAKI T. Self-Supervised Video Representation Using Pretext-Contrastive Learning (2020)[J/OL]. [2020-10-29]. https://arxiv.org/pdf/2010.15464v1.pdf. |
| [33] | DEVLIN J, CHANG M W, LEE K, et al. BERT:Pre-Training of Deep Bidirectional Transformers for Language Understanding (2018)[J/OL]. [2018-10-11]. https://arxiv.org/pdf/1810.04805v1.pdf. |
| [34] | SUN C, MYERS A, VONDRICK C, et al. VideoBERT:A Joint Model for Video and Language Representation Learning[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision.Piscataway:IEEE, 2019:7464-7473. |
| [35] | ZHU L, YANG Y. ActBERT:LearningGlobal-Local Video-Text Representations[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2020:8746-8755. |
| [36] | LI L, CHEN Y C, CHENG Y, et al. HERO:Hierarchical Encoder for Video+Language Omni-Representation Pre-Training (2020)[J/OL]. [2020-05-01]. https://arxiv.org/pdf/2005.00200.pdf. |
| [37] | LEI J, LI L, ZHOU L, et al. Less is More:ClipBERT for Video-and-Language Learning via Sparse Sampling (2020)[J/OL]. [2021-02-11]. https://arxiv.org/pdf/2102.06183.pdf. |
| [38] | KORBAR B, TRAN D, TORRESANI L. Cooperative Learning of Audio and Video Models from Self-Supervised Synchronization (2018)[J/OL]. [2018-06-30]. https://arxiv.org/pdf/1807.00230.pdf. |
| [39] | VALVERDE F R, HURTADO J V, VALADA A. There is More than Meets the Eye:Self-Supervised Multi-Object Detection and Tracking with Sound by Distilling Multimodal Knowledge (2021)[J/OL]. [2021-03-01]. https://arxiv.org/pdf/2103.01353.pdf. |
| [40] | JIAO J, CAI Y, ALSHARID M, et al. Self-supervised Contrastive Video-Speech Representation Learning for Ultrasound[C]// International Conference on Medical Image Computing and Computer-Assisted Intervention.Heidelberg:Springer, 2020:534-543. |
| [41] | HAN T, XIE W, ZISSERMAN A. Self-Supervised Co-Training for Video Representation Learning (2020)[J/OL]. [2020-10-19]. https://arxiv.org/pdf/2010.09709.pdf. |
| [42] | TAO L, WANG X, YAMASAKI T. Self-SupervisedVideo Representation Learning Using Inter-Intra Contrastive Framework[C]// Proceedings of the 28th ACM International Conference on Multimedia.New York:ACM, 2020:2193-2201. |
| [43] | SOOMRO K, ZAMIR A R, SHAH M. UCF101:A Dataset of 101 Human Actions Classes from Videos in the Wild[R/OL]. [2021-04-30]. https://arxiv.org/ols/1212.0402v1. |
| [44] | KUEHNE H, JHUANG H, GARROTE E, et al. HMDB:A Large Video Database for Human Motion Recognition[C]// 2011 International Conference on Computer Vision.Piscataway:IEEE, 2011:2556-2563. |
| [45] | KAY W, CARREIRA J, SIMONYAN K, et al. The Kinetics Human Action Video Dataset (2017)[J/OL]. [2017-05-19]. https://arxiv.org/pdf/1705.06950v1.pdf. |
| [46] | MIECH A, ZHUKOV D, ALAYRAC J B, et al. HowTo100M:Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision.Piscataway:IEEE, 2019:2630-2640. |
| [47] | TANG Y, DING D, RAO Y, et al. COIN:A Large-Scale Dataset for Comprehensive Instructional Video Analysis[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2019:1207-1216. |
| [48] | ZHOU L, XU C, CORSO J. Towards Automatic Learning of Procedures from WebInstructional Videos (2017)[J/OL]. [2017-03-28]. https://arxiv.org/pdf/1703.09788.pdf. |
| [49] | XU J, MEI T, YAO T, et al. MSR-VTT:A Large Video Description Dataset for Bridging Video and Language[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE, 2016:5288-5296. |
| [50] | SRIVASTAVA N, MANSIMOV E, SALAHUDINOV R. Unsupervised Learning of Video Representations Using LSTMs[C]// International Conference on Machine Learning.New York:ACM, 2015:843-852. |
| [51] | TIAN Y, SHI J, LI B, et al. Audio-Visual Event Localization in Unconstrained Videos[C]// Proceedings of the European Conference on Computer Vision.Heidelberg:Springer, 2018:247-263. |
| [52] | BEHRMANN N, GALL J, NOROOZI M. Unsupervised Video Representation Learning by Bidirectional Feature Prediction[C]// Proceedings of the IEEE Winter Conference on Applications of Computer Vision.Piscataway:IEEE, 2021:1670-1679. |
| [53] | KALLURI T, PATHAK D, CHANDRAKER M, et al. FLAVR:Flow-Agnostic Video Representations for Fast Frame Interpolation (2020)[J/OL]. [2020-12-15]. https://arxiv.org/pdf/2012.08512.pdf. |
| [1] | MAO Zhaoyong,WANG Yichen,WANG Xin,SHEN Junge. Vehicle video surveillance and analysis system for the expressway [J]. Journal of Xidian University, 2021, 48(5): 178-189. |
| [2] | ZHANG Shuwei,LI Junmin. Human body detection algorithm in complex monitoring scenes [J]. Journal of Xidian University, 2021, 48(5): 68-77. |
| [3] | ZHAN Keyu,SUN Yue,LI Ying. Video super-resolution based on multi-scale 3D convolution [J]. Journal of Xidian University, 2021, 48(5): 8-14. |
| [4] | ZHANG Zhi,ZHENG Jin. Interframe target regression network for vehicle detection in UAV video [J]. Journal of Xidian University, 2021, 48(4): 151-158. |
| [5] | SHI Juan,XIE De,JIANG Qing. Deep consistency-preserving hashing [J]. Journal of Xidian University, 2021, 48(3): 71-77. |
| [6] | ZHANG Hongwei,TAN Quanlu,LU Shuai,GE Zhiqiang,XU Jian. Yarn-dyed shirt piece defect detection based on an unsupervised reconstruction model of the U-shaped denoising convolutional auto-encoder [J]. Journal of Xidian University, 2021, 48(3): 123-130. |
| [7] | LI Qiang,ZUO Jing,WANG Haining. Fast algorithm for intra prediction in quality SHVC [J]. Journal of Xidian University, 2020, 47(2): 60-66. |
| [8] | HUANG Zhangqin,MU Zhao,CEN Chen,GAO Han. 360-degree real-time stitching technology for multi-channel video [J]. Journal of Xidian University, 2020, 47(2): 1-8. |
| [9] | JIANG Shaobin,DU Chun,CHEN Hao,LI Jun,WU Jiangjiang. Unsupervised adversarial learning method for hard disk failure prediction [J]. Journal of Xidian University, 2020, 47(2): 118-125. |
| [10] | SHEN Haijie,BIAN Qian,CHEN Xiaofan,WANG Zhenduo,TIAN Xinzhi. Video deblurring using the generative adversarial network [J]. Journal of Xidian University, 2019, 46(6): 112-117. |
| [11] | WANG Yanfen,ZHU Xuran,YUN Xiao,SUN Yanjing,SHI Yunkai,WANG Sainan. Vehicle re-identification by multi-cameras for public security surveillance [J]. Journal of Xidian University, 2019, 46(4): 190-196. |
| [12] | ZHANG Xingguo;LIU Xiaolei;LI Jing;WANG Huandong. Real-time detection and identification of speed limit traffic signs under the BP neural network [J]. Journal of Xidian University, 2018, 45(5): 136-142. |
| [13] | CAI Jiangzheng;HEI Yong;YUAN Jia;CHEN Liming. Near-threshold non-precharged SRAM [J]. Journal of Xidian University, 2018, 45(1): 106-111. |
| [14] | WANG Sen;QIU Yang;TIN Jin;XU Qinglin. Electromagnetic leakage characteristics of the digital video cable [J]. Journal of Xidian University, 2017, 44(5): 81-86. |
| [15] | GE Chuan;LIU Ju;YUAN Hui;XIAO Yifan;LI Fengrong. Temporal subsampling based depth maps coding and the reconstruction method [J]. Journal of Xidian University, 2016, 43(4): 160-165+171. |
|