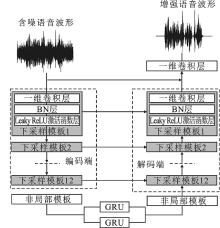
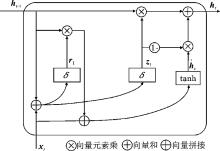
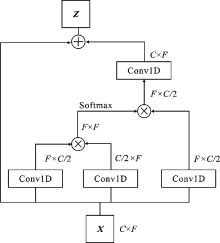
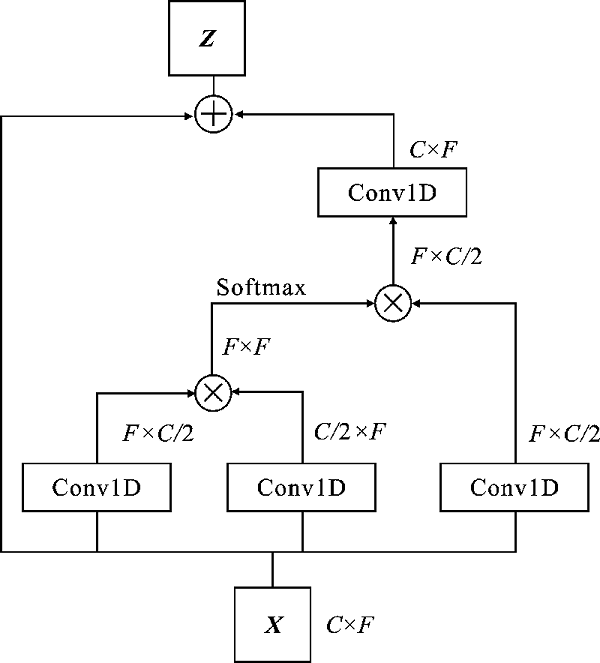
| [1] |
刘文举, 聂帅, 梁山 , 等. 基于深度学习语音分离技术的研究现状与进展[J]. 自动化学报, 2016,42(6):819-833.
|
|
Liu Wenju, Nie Shuai, Liang Shan , et al. Deep learning based speech separation technology and its developments[J]. Acta Automatica Sinica, 2016,42(6):819-833.
|
| [2] |
毕灶荣, 童东兵, 陈巧玉 . 基于快速MFCC计算的说话人识别系统的设计[J]. 电子科技, 2018,31(4):25-28.
|
|
Bi Zaorong, Tong Dongbing, Chen Qiaoyu . Design of speaker recognition system based on fast MFCC calculation[J]. Electronic Science and Technology, 2018,31(4):25-28.
|
| [3] |
刘立辉, 杨毅, 王旭阳 , 等. 机载任务系统语音交互技术应用研究[J]. 电子科技, 2017,30(12):125-129.
|
|
Liu Lihui, Yang Yi, Wang Xuyang , et al. Applied research on the speech interaction technology in airborne mission system[J]. Electronic Science and Technology, 2017,30(12):125-129.
|
| [4] |
Wang D L, Chen J T . Supervised speech separation based on deep learning:an overview[J]. IEEE/ACM Transactions on Audio Speech and Language Processing, 2018,26(10):1702-1726.
|
| [5] |
Xu Y, Du J, Dai L R , et al. An experimental study on speech enhancement based on deep neural networks[J]. IEEE Signal Processing Letters, 2013,21(1):65-68.
|
| [6] |
袁文浩, 孙文珠, 夏斌 , 等. 利用深度卷积神经网络提高未知噪声下的语音增强性能[J]. 自动化学报, 2018,44(4):751-759.
|
|
Yuan Wenhao, Sun Wenzhu, Xia Bin , et al. Improving speech enhancement in unseen noise using deep convolutional neural network[J]. Acta Automatica Sinica, 2018,44(4):751-759.
|
| [7] |
范存航, 刘斌, 陶建华 , 等. 一种基于卷积神经网络的端到端语音分离方法[J]. 信号处理, 2019,35(4):542-548.
|
|
Fan Cunhang, Liu Bin, Tao Jianhua , et al. An end-to-end speech separation method based on convolutional neural network[J]. Journal of Signal Processing, 2019,35(4):542-548.
|
| [8] |
Paliwal K, Wójcicki K, Shannon B . The importance of phase in speech enhancement[J]. Speech Communication, 2011,53(4):465-494.
|
| [9] |
Pascual S, Bonafonte A, Serrà J. SEGAN:speech enhancement generative adversarial network[C]. Stockholm:Proceedings of the International Speech Communication Association, 2017.
|
| [10] |
王怡斐, 韩俊刚, 樊良辉 . 基于WGAN的语音增强算法研究[J]. 重庆邮电大学学报(自然科学版), 2019,31(1):136-142.
|
|
Wang Yifei, Han Jungang, Fan Lianghui . Algorithm research of speech enhancement based on WGAN[J]. Journal of Chongqing University of Posts and Telecommunications(Natural Science Edition), 2019,31(1):136-142.
|
| [11] |
Baby D, Verhulst S. Sergan:speech enhancement using relativistic generative adversarial networks with gradient penalty[C]. Brighton:Proceedings of the International Conference on Acoustics,Speech and Signal Processing, 2019.
|
| [12] |
Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation [C].Boston:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015.
|
| [13] |
Stoller D, Ewert S, Dixon S. Wave-U-Net: a multi-scale neural network for end-to-end audio source separation[C]. Paris:International Society for Music InformationRetrieval, 2018.
|
| [14] |
Wang X L, Girshick R, Gupta A, et al. Non-local neural networks[C]. Salt Lake City:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018.
|
| [15] |
袁文浩, 娄迎曦, 夏斌 , 等. 基于卷积门控循环神经网络的语音增强方法[J]. 华中科技大学学报(自然科学版), 2019,47(4):13-18.
|
|
Yuan Wenhao, Lou Yingxi, Xia Bin , et al. Speech enhancement method based on convolutional gated recurrent neural network[J]. Journal of Huazhong University of Science and Technology(Natural Science Edition), 2019,47(4):13-18.
|
| [16] |
黎阳, 沈烨, 刘敏 , 等. 融合运动信息与表观信息的多目标跟踪算法[J]. 电子科技, 2020,33(9):21-24.
|
|
Li Yang, Shen Ye, Liu Min , et al. Multi-target tracking algorithm by combining motion information and apparent information[J]. Electronic Science and Technology, 2020,33(9):21-24.
|
| [17] |
贝琛圆, 于海滨, 潘勉 , 等. 基于改进U-Net网络的腺体细胞图像分割算法[J]. 电子科技, 2019,32(11):18-22.
|
|
Bei Chenyuan, Yu Haibin, Pan Mian , et al. Gland cell image segmentation algorithm based on improved U-Net network[J]. Electronic Science and Technology, 2019,32(11):18-22.
|
| [18] |
Piczak K J. ESC:Dataset for environmental sound classification[C]. Brisbane:Proceedings of the Twenty-third Acm International Conference on Multimedia, 2015.
|
| [19] |
Varga A, Steeneken H J M. Assessment for automatic speech recognition:II. NOISEX-92:A database and an experiment to study the effect of additive noise on speech recognition systems[J]. Speech Communication, 1993,12(3):247-251.
|
| [20] |
Rix A W, Beerends J G, Hollier M P, et al. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs[C]. Piscataway:Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, 2001.
|
| [21] |
Taal C H, Hendriks R C, Heusdens R , et al. An algorithm for intelligibility prediction of time-frequency weighted noisy speech[J]. IEEE Transactions on Audio Speech and Language Processing, 2011,19(7):2125-2136.
|