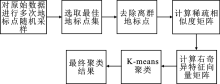
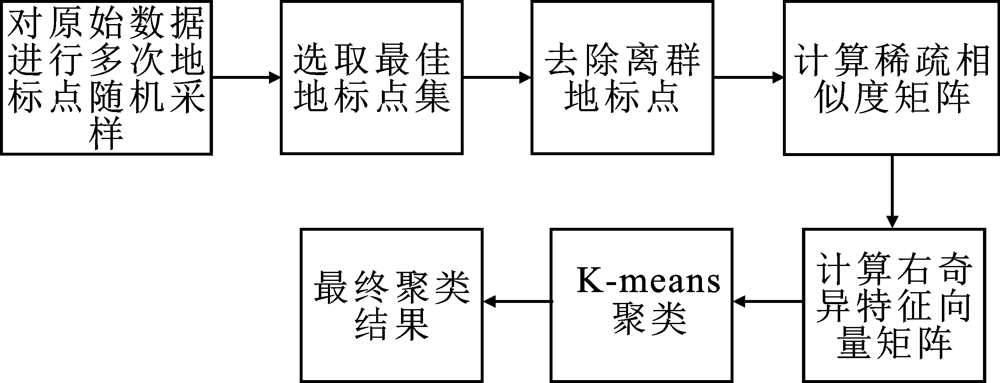
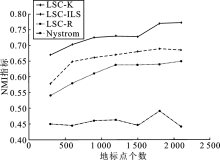
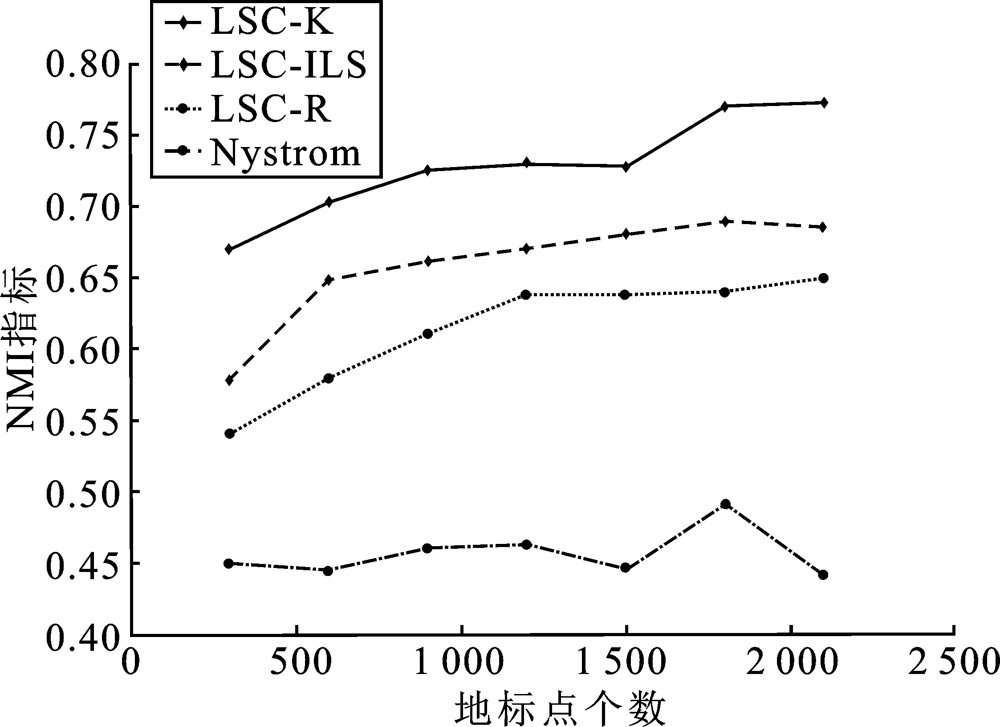
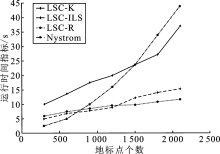
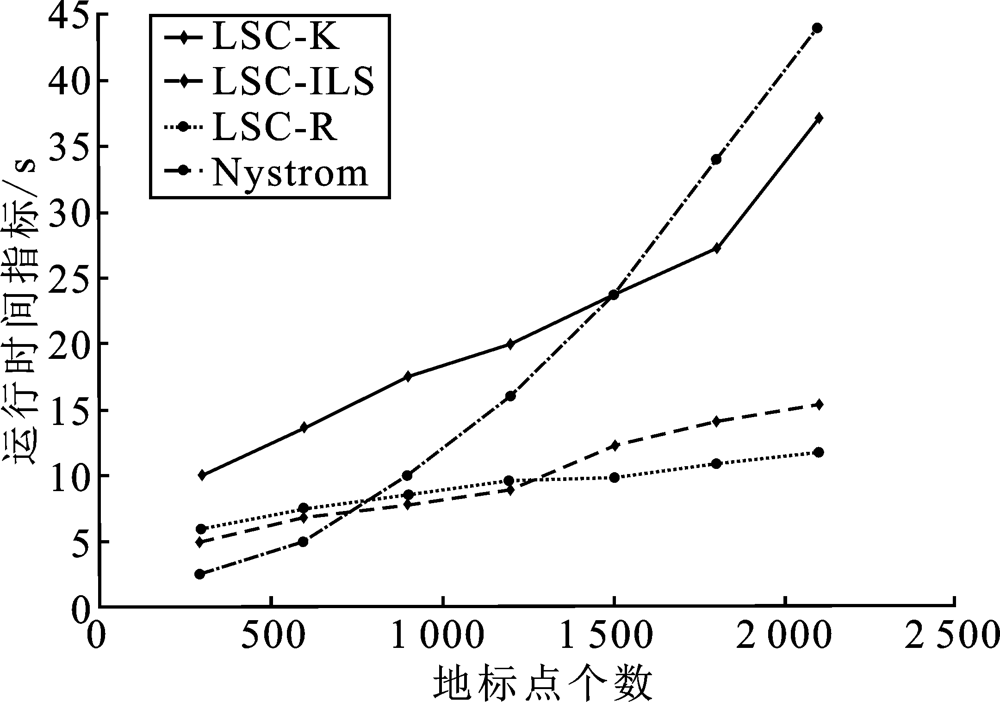
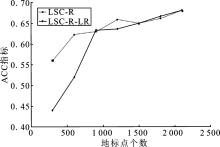
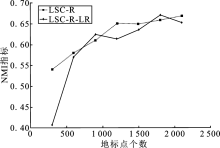
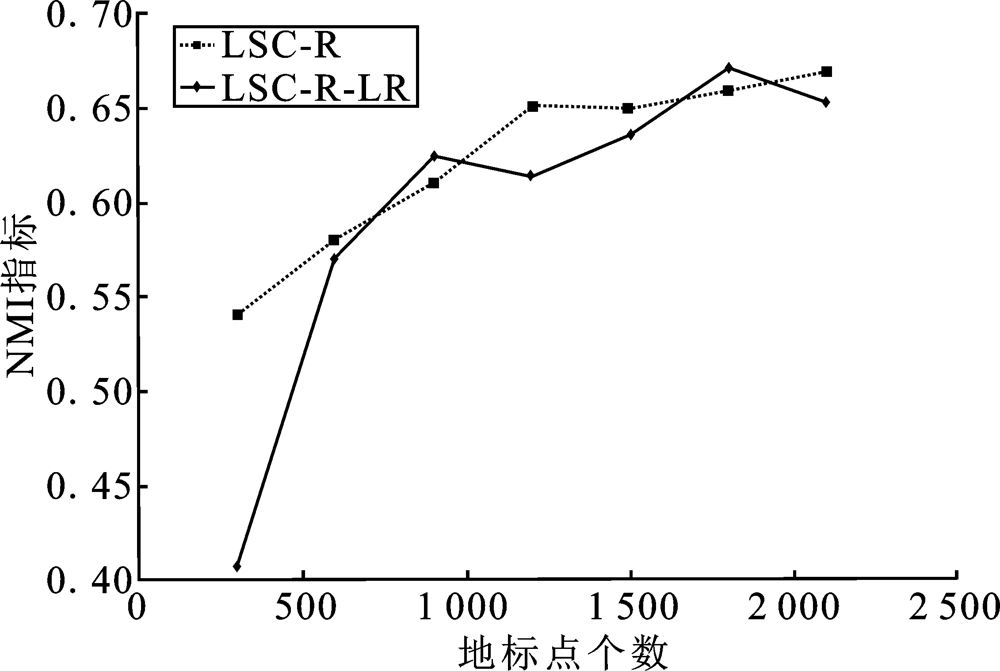
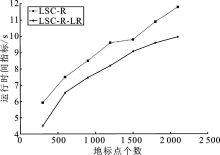
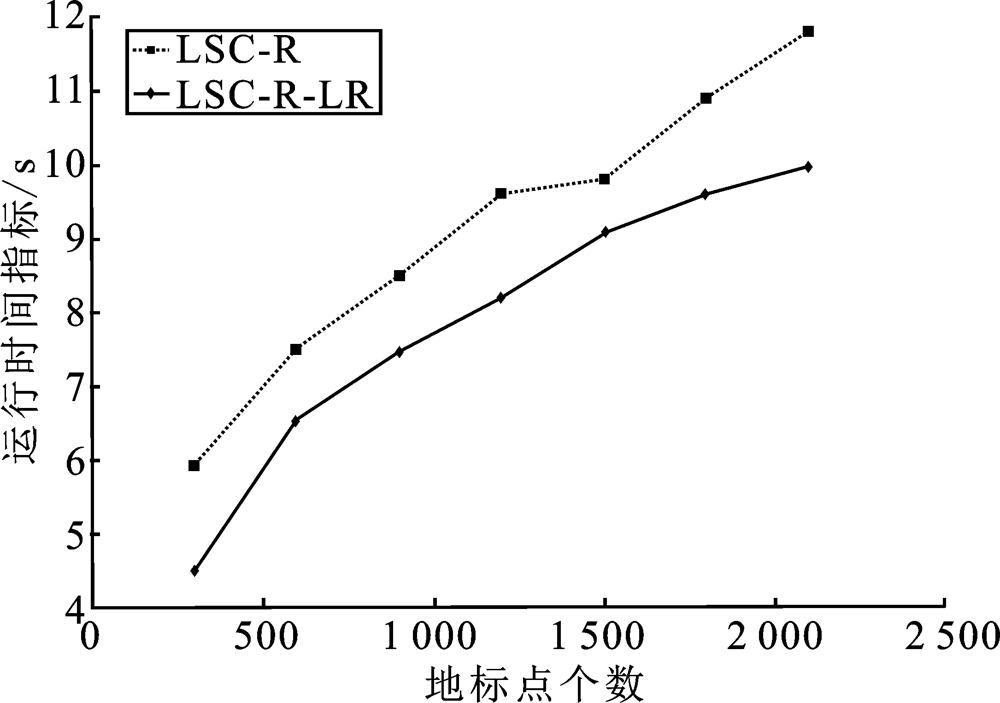
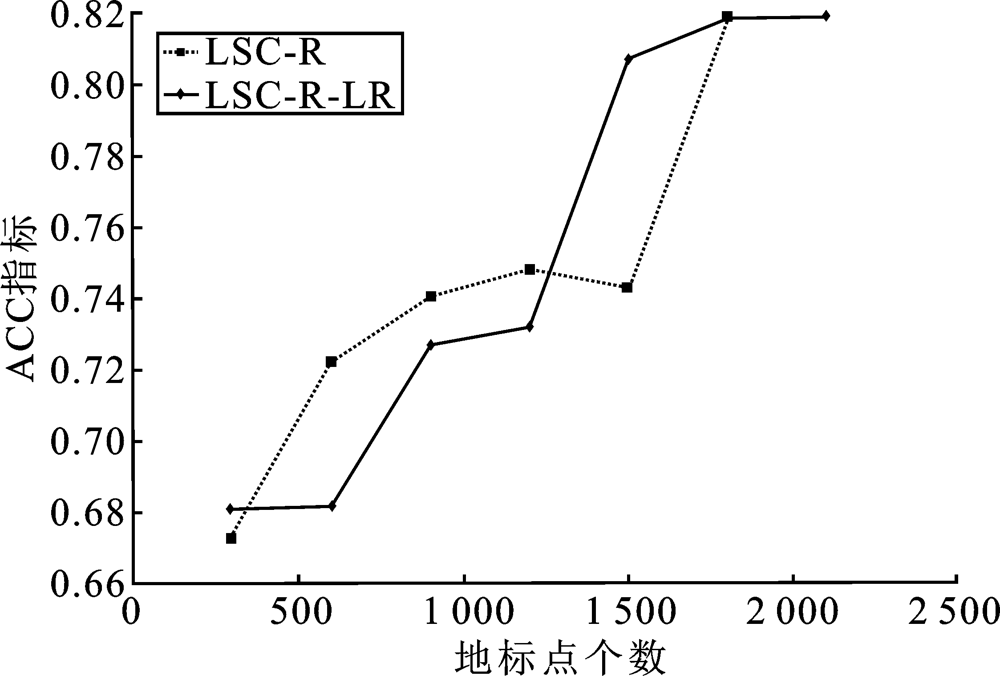
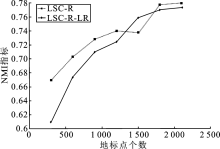
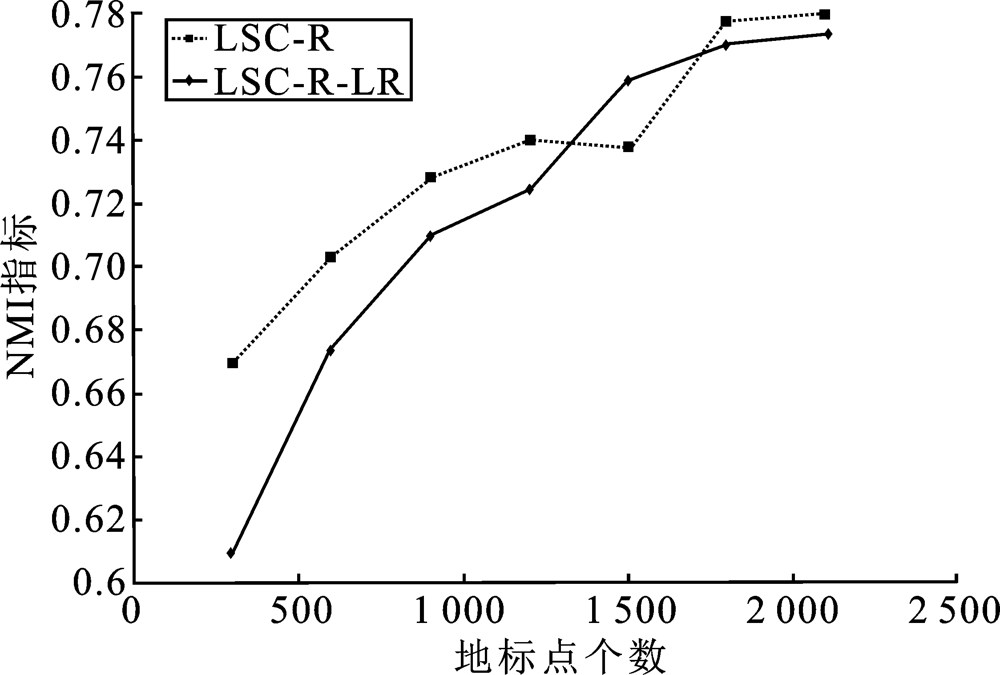
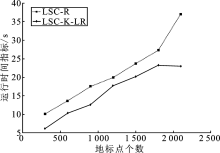
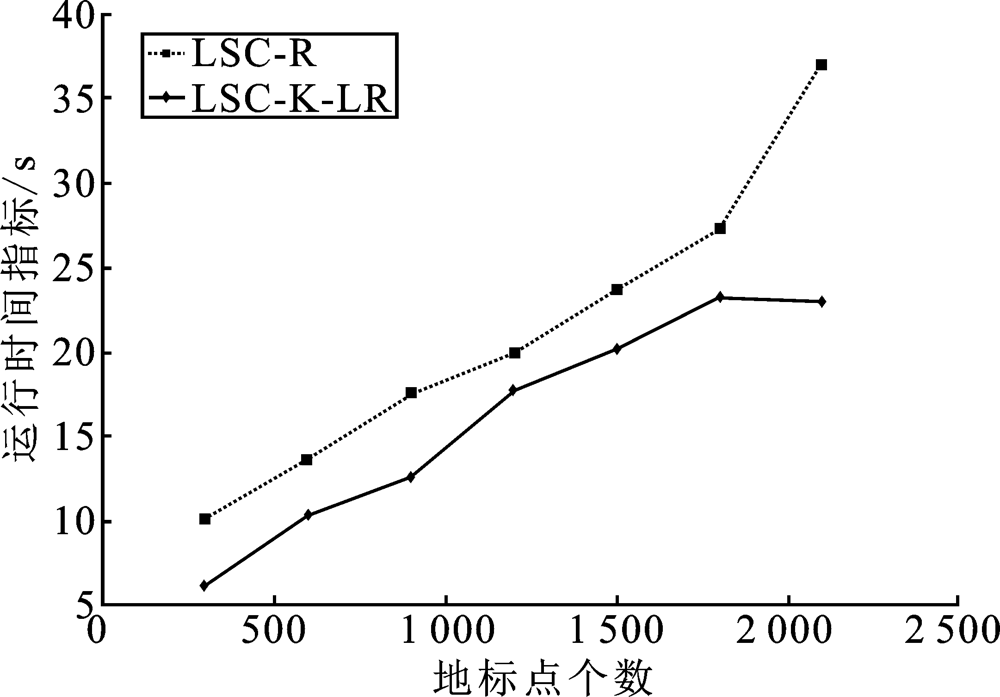
| [1] |
Wu X, Zhu X, Wu G Q, et al. Data mining with big data[J]. IEEE Transactions on Knowledge & Data Engineering, 2013,26(1):97-107.
|
| [2] |
Wu J, Liu H, Xiong H, et al. K-means-based consensus clustering: a unified view[J]. IEEE Transactions on Knowledge and Data Engineering, 2015,27(1):155-169.
doi: 10.1109/TKDE.69
|
| [3] |
Song Q, Ni J, Wang G. A fast clustering-based feature subset selection algorithm for high-dimensional data[J]. IEEE Transactions on Knowledge & Data Engineering, 2013,25(1):1-14.
|
| [4] |
向志华, 邵亚丽. 一种结合贪心选择和特征加权的高维数据聚类算法[J]. 电子科技, 2019,32(11):70-73.
|
|
Xiang Zhihua, Shao Yali. A high dimensional data clustering algorithm combining greedy selection and feature weighting[J]. Electronic Science and Technology, 2019,32(11):70-73.
|
| [5] |
Jia H, Ding S, Xu X, et al. The latest research progress on spectral clustering[J]. Neural Computing & Applications, 2014,24(7-8):1477-1486.
|
| [6] |
李根, 王亚刚, 周小伟, 等. 一种基于密度均值的谱聚类算法[J]. 电子科技, 2016,29(8):74-77.
|
|
Li Gen, Wang Yagang, Zhou Xiaowei, et al. A spectral clustering algorithm based on average density[J]. Electronic Science and Technology, 2016,29(8):74-77.
|
| [7] |
Hagen L, Kahng A B. New spectral methods for ratio cut partitioning and clustering[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2002,11(9):1074-1085.
doi: 10.1109/43.159993
|
| [8] |
Shi J, Malik J. Normalized cuts and image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000,22(8):888-905.
doi: 10.1109/34.868688
|
| [9] |
Ng AY, Jordan M I, Weiss Y. On spectral clustering: analysis and an algorithm[J]. Neural Information Processing Systems, 2002,(14):849-856.
|
| [10] |
Fowlkes C, Belongie S, Chung F, et al. Spectral grouping using the Nystrom method[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2004,26(2):214-225.
|
| [11] |
Nyström E J. Über die praktische auflösung von integralgleichungen mit anwendungen auf randwertaufgaben[J]. Acta Mathematica, 1930,54(1):185-204.
doi: 10.1007/BF02547521
|
| [12] |
Li M, Kwok J T, Lu B L. Making large-scale nyström approximation possible[C]. Haifa:International Conference on Machine Learning, 2010.
|
| [13] |
贾洪杰, 丁世飞, 史忠植. 求解大规模谱聚类的近似加权核K-means算法[J]. 软件学报, 2015,26(11):2836-2846.
|
|
Jia Hongjie, Ding Shifei, Shi Zhongzhi. Approximate weighted kernel K-means for large-scale spectral clustering[J]. Journal of Software, 2015,26(11):2836-2846.
|
| [14] |
Cai D, Chen X. Large scale spectral clustering via landmark-based sparse representation[J]. IEEE Transactions on Cybernetics, 2015,45(8):1669-1680.
doi: 10.1109/TCYB.2014.2358564
|
| [15] |
Donoho D L, Elad M. Optimally sparse representation in general (nonorthogonal) dictionaries via ℓ'minimization[J]. Proceedings of the National Academy of Sciences of the United States of America, 2003,100(5):2197-2202.
|
| [16] |
Olshausen B A, Field D J. Emergence of simple-cell receptive field properties by learning a sparse code for natural images[J]. Nature, 1996,381(6583):607-609.
pmid: 8637596
|
| [17] |
Rafailidis D, Constantinou E, Manolopoulos Y. Landmark selection for spectral clustering based on Weighted PageRank[J]. Future Generation Computer Systems, 2017,68(3):465-472.
doi: 10.1016/j.future.2016.03.006
|
| [18] |
叶茂, 刘文芬. 基于快速地标采样的大规模谱聚类算法[J]. 电子与信息学报, 2017,39(2):278-284.
|
|
Ye Mao, Liu Wenfen. Large scale spectral clustering based on fast landmark sampling[J]. Journal of Electronics and Information Technology, 2017,39(2):278-284.
|
| [19] |
Fahad A, Alshatri N, Tari Z, et al. A survey of clustering algorithms for big data:taxonomy and empirical analysis[J]. IEEE Transactions on Emerging Topics in Computing, 2014,2(3):267-279.
doi: 10.1109/TETC.2014.2330519
|
| [20] |
Strehl A, Ghosh J. Cluster ensembles: a knowledge reuse framework for combining partitionings[J]. Journal of Machine Learning Research, 2002,3(3):583-617.
|
| [21] |
Munkres J. Algorithms for the assignment and transportation problems[J]. Journal of the Society for Industrial & Applied Mathematics, 1957,5(1):32-38.
|