电子科技 ›› 2022, Vol. 35 ›› Issue (9): 30-36.doi: 10.16180/j.cnki.issn1007-7820.2022.09.005
牛嘉丰,石蕴玉,刘翔,李任斯
收稿日期:2021-03-22
出版日期:2022-09-15
发布日期:2022-09-15
作者简介:牛嘉丰(1993-),男,硕士研究生。研究方向:图像处理。|石蕴玉(1982-),女,博士,讲师。研究方向:视频处理分析及质量评价。|刘翔(1972-),男,博士,副教授。研究方向:计算机视觉与人工生命。
基金资助:NIU Jiafeng,SHI Yunyu,LIU Xiang,LI Rensi
Received:2021-03-22
Online:2022-09-15
Published:2022-09-15
Supported by:摘要:
视频摘要是监控视频浏览和存储的有效技术。在压缩比的限制下,现有的视频摘要生成方法容易导致重排目标碰撞和时序错乱。针对该问题,文中提出一种融合目标速度变化机制的视频摘要生成模型。在目标重排的能量函数中,除目标起始位置变量之外还加入了目标速度变量,从而能够同时改变目标的起始位置和速度,避免碰撞和时序错乱问题。随后使用马尔科夫链蒙特卡罗随机采样算法求解能量函数的最优值,得到了目标重排方案的最优解。实验表明,在压缩率相同的情况下,相较于其他方法,该模型生成的摘要视频中的目标碰撞和时序错乱的问题较少。
中图分类号:
牛嘉丰,石蕴玉,刘翔,李任斯. 融合目标速度变化机制的视频摘要生成模型[J]. 电子科技, 2022, 35(9): 30-36.
NIU Jiafeng,SHI Yunyu,LIU Xiang,LI Rensi. A Video Synopsis Generation Model Incorporating Object Speed Change Mechanism[J]. Electronic Science and Technology, 2022, 35(9): 30-36.
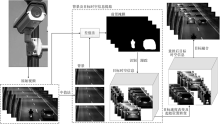
图1
视频摘要生成模型流程图"
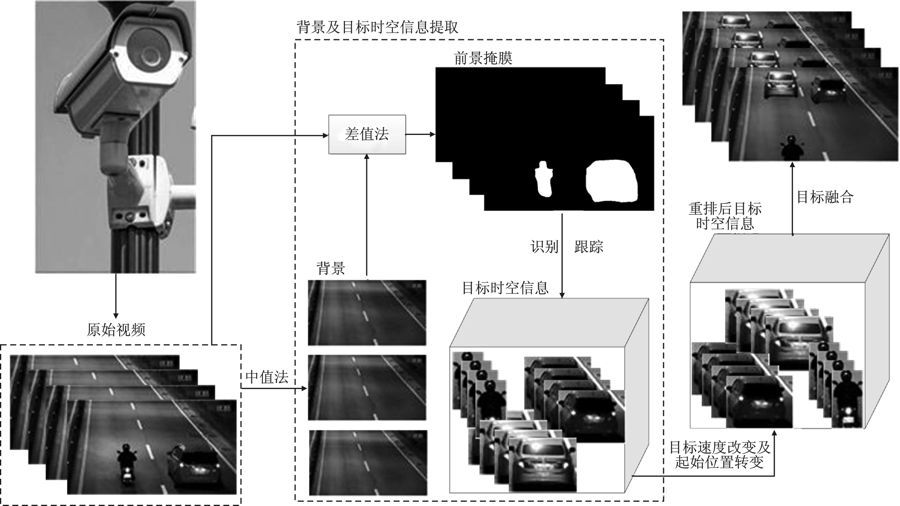
表1
视频参数"
| 编号 | 视频时长 /min | 视频帧率 /frame·s-1 | 目标个数 | 分辨率 |
|---|---|---|---|---|
| 视频1 | 3 | 24 | 21 | 1 280×720 |
| 视频2 | 5 | 25 | 47 | 672×376 |
| 视频3 | 5 | 30 | 18 | 1 920 ×1 072 |
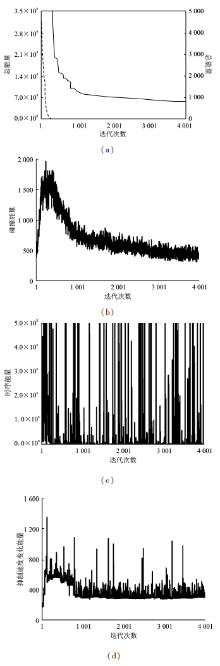
图2
能量变化示意图(a)总能量 (b)碰撞能量 (c)时序能量 (d)抑制速度变化能量"
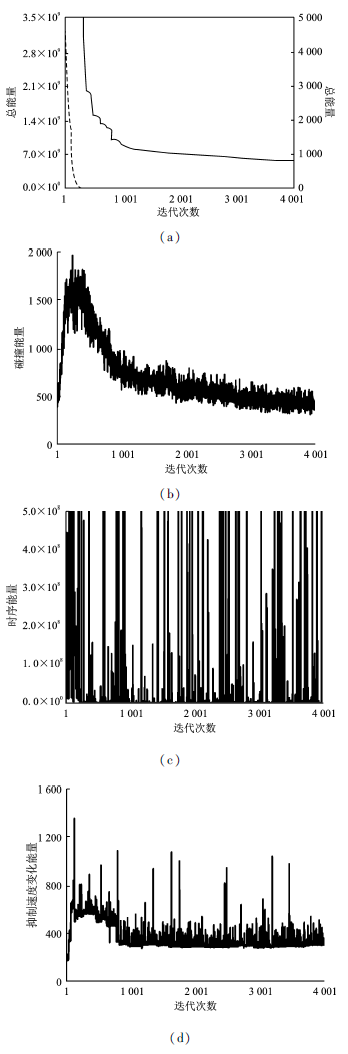
表2
实验结果"
| 测试视 频编号 | 压缩率 | 碰撞数 | 时序错乱数 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 本文 方法 | 文献 [4] | 文献 [8] | 本文 方法 | 文献 [4] | 文献 [8] | 本文 方法 | 文献 [4] | 文献 [8] | |
| 视频1 | 0.21 | 0.21 | 0.21 | 0 | 0 | 3 | 0 | 5 | 1 |
| 视频2 | 0.34 | 0.34 | 0.34 | 0 | 3 | 4 | 0 | 4 | 3 |
| 视频3 | 0.08 | 0.08 | 0.08 | 1 | 0 | 4 | 1 | 4 | 2 |

图3
原始视频帧及摘要视频帧示意图"

| [1] | 李鹏程. 基于张量紧凑表示的视频压缩算法[J]. 电子科技, 2017, 30(5):1-4. |
| Li Pengcheng. Video compression algorithm based on tensor compact representation[J]. Electronic Science and Technology, 2017, 30(5):1-4. | |
| [2] | Lu M, Wang Y, Pan G. Generating fluent tubes in video synopsis[C]. Vancouver: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal, 2013. |
| [3] |
Zhong R, Hu R, Wang Z, et al. Fast synopsis for moving objects using compressed video[J]. IEEE Signal Processing Letters, 2014, 21(7):834-838.
doi: 10.1109/LSP.2014.2317754 |
| [4] |
Nie Y, Xiao C, Sun H, et al. Compact video synopsis via global spatiotemporal optimization[J]. IEEE Transactions on Visualization and Computer Graphics, 2013, 19(10):1664-1676.
doi: 10.1109/TVCG.2012.176 |
| [5] |
He Y, Gao C, Sang N, et al. Graph coloring based surveillance video synopsis[J]. Neurocomputing, 2017, 225(15): 64-79.
doi: 10.1016/j.neucom.2016.11.011 |
| [6] |
Ruan T, Wei S, Li J, et al. Rearranging online tubes for streaming video synopsis: a dynamic graph coloring approach[J]. IEEE Transactions on Image Processing, 2019, 28(8):3873-3884.
doi: 10.1109/TIP.2019.2903322 pmid: 30869618 |
| [7] | Moussa M M, Shoitan R. Object-based video synopsis approach using particle swarm optimization[C]. London: Proceedings of the Signal, Image and Video, 2020. |
| [8] |
Namitha K, Narayanan A. Preserving interactions among moving objects in surveillance video synopsis[J]. Multimedia Tools and Applications, 2020, 79(43):32331-32360.
doi: 10.1007/s11042-020-09493-2 |
| [9] |
Li X L, Wang Z G, Lu X Q. Surveillance video synopsis via scaling down objects[J]. IEEE Transactions on Image Processing, 2015, 25(2):740-755.
doi: 10.1109/TIP.2015.2507942 |
| [10] |
Nie Y W, Li Z K, Zhang Z S, et al. Collision-free video synopsis incorporating object speed and size changes[J]. IEEE Transactions on Image Processing, 2020, 29(24):1465-1478.
doi: 10.1109/TIP.2019.2942543 |
| [11] |
Zivkovic Z, Van Der Heijden F. Efficient adaptive density estimation per image pixel for the task of background subtraction[J]. Pattern Recognition Letters, 2006, 27(7):773-780.
doi: 10.1016/j.patrec.2005.11.005 |
| [12] | Wang Q, Zhang L, Bertinetto L, et al. Fast online object tracking and segmentation: A unifying approach[C]. Long Beach: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019. |
| [13] | 曾照, 吴薇, 汪欣. 改进的核相关滤波跟踪算法[J]. 电子科技, 2020, 33(3):50-55. |
| Zeng Zhao, Wu Wei, Wang Xin. Improved kernelized correlation filter tracking[J]. Electronic Science and Technology, 2020, 33(3):50-55. | |
| [14] | Gilks W R, Richardson S, Spiegelhalter D. Markov chain monte carlo in practice[J]. Technometrics, 1997, 39(3):338-339. |
| [15] |
Metropolis N, Rosenbluth A W, Rosenbluth M N, et al. Equation of state calculations by fast computing machines[J]. The Journal of Chemical Physics, 1953, 21(6):1087-1092.
doi: 10.1063/1.1699114 |
| [16] |
Hastings W K. Monte carlo sampling methods using Markov chains and their applications[J]. Biometrika, 1970, 57(1):97-109.
doi: 10.1093/biomet/57.1.97 |
| [17] | P'erez P, Gangnet M, Blake A. Poisson image editing[J]. ACM Tranactions on Graphics, 2003, 22(3):313-318. |
| [18] | Corona K, Osterdahl K, Collins R, et al. MEVA: A large-scale multiview, multimodal video dataset for activity detection[C]. Virtual: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021. |
| [19] | 周俊, 袁佳明, 万伟江. 基于加权时变泊松模型的电力信用风险判别及预警系统设计[J]. 电子设计工程, 2021, 29(11):21-25. |
| Zhou Jun, Yuan Jiaming, Wan Weijiang. Power credit risk discrimination and early warning system design based on weighted time-varying Poisson model[J]. Electronic Design Engineering, 2021, 29(11):21-25. |
| [1] | 路东生,张玉金,朱海,姜月武. 几何约束下噪声一致性的图像拼接篡改检测[J]. 电子科技, 2022, 35(10): 51-58. |
| [2] | 吴旭,刘翔. 基于非局部自相关的复制粘贴检测算法[J]. 电子科技, 2022, 35(10): 59-64. |
| [3] | 赵鉴,袁渤巽,倪凌凡,林顺富,王维. 基于改进粒子群算法在多能互补微网中的应用[J]. 电子科技, 2022, 35(10): 72-78. |
| [4] | 杨莹莹,刘翔,石蕴玉. 一种改进的AGV障碍物检测方法[J]. 电子科技, 2022, 35(9): 1-6. |
| [5] | 毕嘉桢,沈拓,张轩雄. 基于机器视觉的轨道交通自动测距研究[J]. 电子科技, 2022, 35(9): 37-43. |
| [6] | 章锌栋,付东翔. 基于三维镜框建模的眼镜虚拟试戴系统[J]. 电子科技, 2022, 35(9): 52-57. |
| [7] | 邓源,施一萍,江悦莹,朱亚梅,刘瑾. 基于MobileNetV2与LBP特征融合的婴幼儿表情识别算法[J]. 电子科技, 2022, 35(8): 47-52. |
| [8] | 冯俊逸,沈拓,张轩雄. 基于图像处理的轨旁信号机识别方法[J]. 电子科技, 2022, 35(8): 53-57. |
| [9] | 张乔木,钟倩文,孙明,罗文成,柴晓冬. 复杂环境下弓网接触位置动态监测方法研究[J]. 电子科技, 2022, 35(8): 66-72. |
| [10] | 张茂林,叶轻舟,潘鑫,陆华. 基于Tesseract_OCR的化工包装袋喷码质量检测算法[J]. 电子科技, 2022, 35(7): 27-31. |
| [11] | 陈劲宏,陈玮,尹钟. 基于改进ExfuseNet模型的街景语义分割[J]. 电子科技, 2022, 35(6): 28-34. |
| [12] | 沈宁静,袁健. 基于残差密集连接与注意力融合的人群计数算法[J]. 电子科技, 2022, 35(6): 6-12. |
| [13] | 刘群坡,席秀蕾,杨凌霄. 基于LK光流和网格运动统计的图像匹配改进算法[J]. 电子科技, 2022, 35(5): 1-6. |
| [14] | 施震华,张娜,包晓安,宋杰. 基于分批估计的自适应加权数据融合算法[J]. 电子科技, 2022, 35(5): 19-25. |
| [15] | 程顺达,程颖,孙士江. 基于机器学习的肿瘤智能辅助诊断方法[J]. 电子科技, 2022, 35(5): 56-59. |
|

