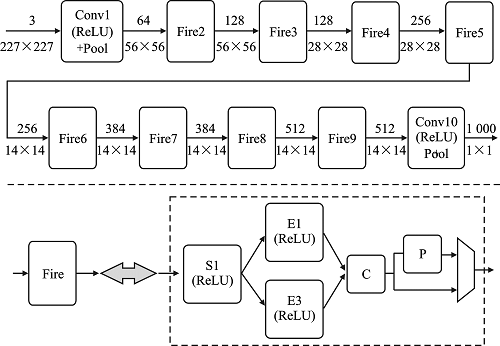
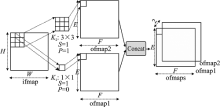
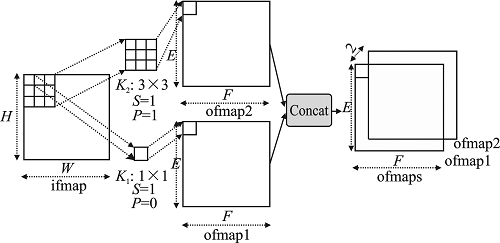
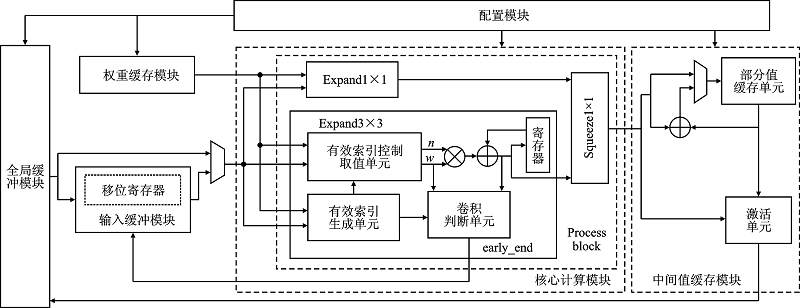
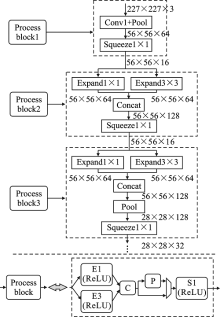
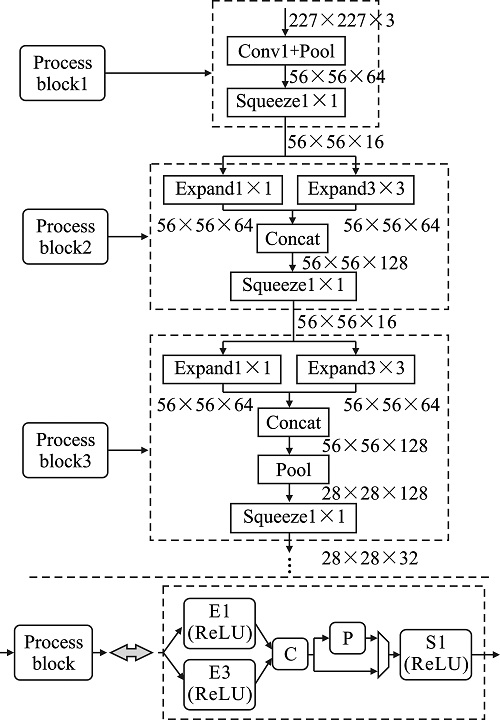
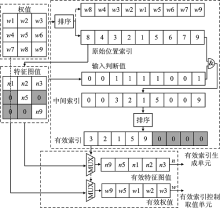
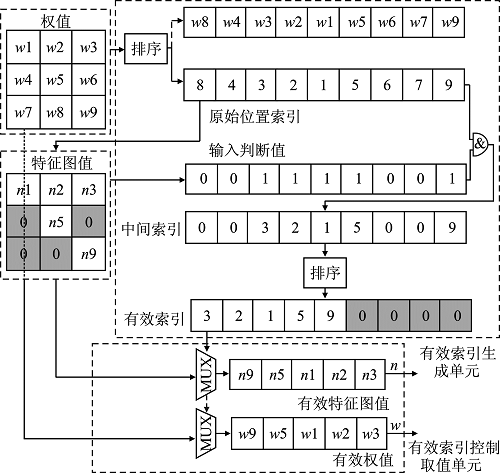
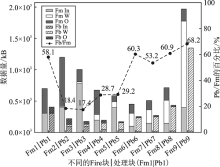
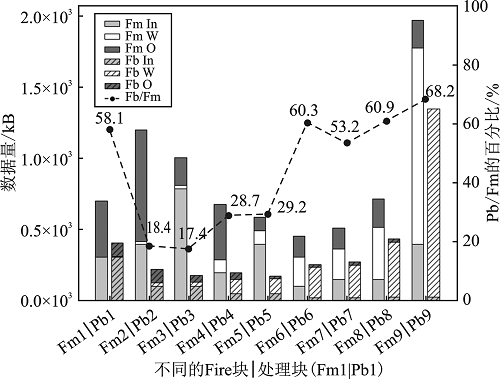
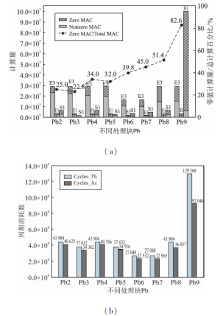
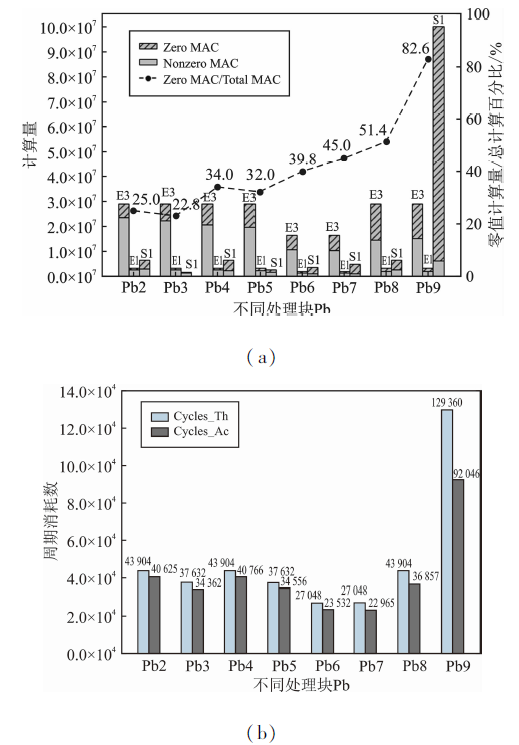
| [1] |
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[C]. San Diego:Proceedings of the International Conference on Learning Representations, 2015.
|
| [2] |
Szegedy C, Liu W, Jia Y Q, et al. Going deeper with convolutions[C]. Boston:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015.
|
| [3] |
He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]. Seattle:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016.
|
| [4] |
Han S, Mao H, Dally W J, et al. Deep compression: compressing deep neural networks with pruning, trained quantization and huffman coding[C]. San Juan:Proceedings of the International Conference on Learning Representations, 2016.
|
| [5] |
Han S, Liu X Y, Mao H Z, et al. EIE: efficient inference engine on compressed deep neural network[J]. International Symposium on Computer Architecture, 2016, 44(3):243-254.
|
| [6] |
Courbariaux M, Bengio Y, David J P. Binaryconnect: training deep neural networks with binary weights during propagations[C]. Montreal:Proceedings of the Twenty-ninth Annual Conference on Neural Information Processings Systems, 2015.
|
| [7] |
Rastegari M, Ordonez V, Redmon J, et al. XNOR-Net: imageNet classification using binary convolutional neural networks[C]. Amsterdam:Proceedings of the Fourteenth European Conference on Computer Vision, 2016.
|
| [8] |
Zhang X Y, Zhou X Y, Lin M X, et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices[C]. Salt Lake City:Proceedings of the Thirty-first IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018.
|
| [9] |
Sandler M, Howard A, Zhu M, et al. MobilenetV2: inverted residuals and linear bottlenecks[C]. Salt Lake City: IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018.
|
| [10] |
Santos A G, Souza C D, Zanchettin C, et al. Reducing SqueezeNet Storage Size with Depthwise Separable Convolutions[C]. Rio de Janeiro:International Joint Conference on Neural Networks, 2018.
|
| [11] |
毕鹏程, 罗健欣, 陈卫卫, 等. 面向移动端的轻量化卷积神经网络结构[J]. 信息技术与网络安全, 2019, 38(9):24-29.
|
|
Bi Pengcheng, Luo Jianxin, Chen Weiwei, et al. Lightweight convolutional neural network structure for mobile terminal[J]. Information Technology and Network Security, 2019, 38(9):24-29.
|
| [12] |
胡挺, 祝永新, 田犁, 等. 面向移动平台的轻量级卷积神经网络架构[J]. 计算机工程, 2019, 45(1):17-22.
|
|
Hu Ting, Zhu Yongxin, Tian Li, et al. Lightweight convolutional neural network architecture for mobile platforms[J]. Computer Engineering, 2019, 45(1):17-22.
|
| [13] |
秦兴, 高晓琪, 陈滨. 基于压缩卷积神经网络的图像超分辨率算法[J]. 电子科技, 2020, 33(5):1-8.
|
|
Qin Xing, Gao Xiaoqi, Chen Bin. Image super-resolution algorithm based on SqueezeNet convolution neural network[J]. Electronic Science and Technology, 2020, 33(5):1-8.
|
| [14] |
Huang C, Ni S Y, Chen G S. A layer-based structured design of CNN on FPGA[C]. Guiyang:Proceedings of the Twelfth IEEE International Conference on ASIC, 2017.
|
| [15] |
Aimar A, Mostafa H, Calabrese E, et al. Nullhop: a flexible convolutional neural network accelerator based on sparse representations of feature maps[J]. IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(3):644-656.
doi: 10.1109/TNNLS.2018.2852335
|
| [16] |
Mousouliotis P G, Petrou L P. SqueezeJet: high-level synthesis accelerator design for deep convolutional neural networks[C]. Voros:Proceedings of the International Symposium on Applied Reconfigurable Computing, 2018.
|