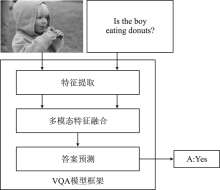
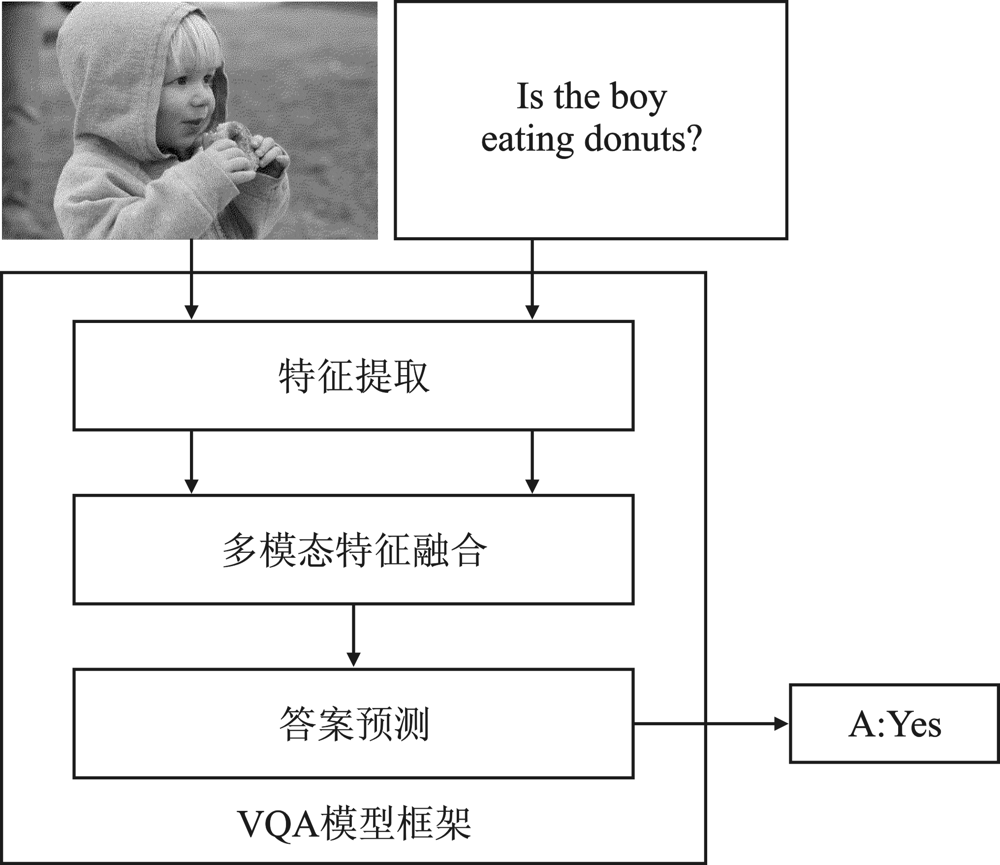
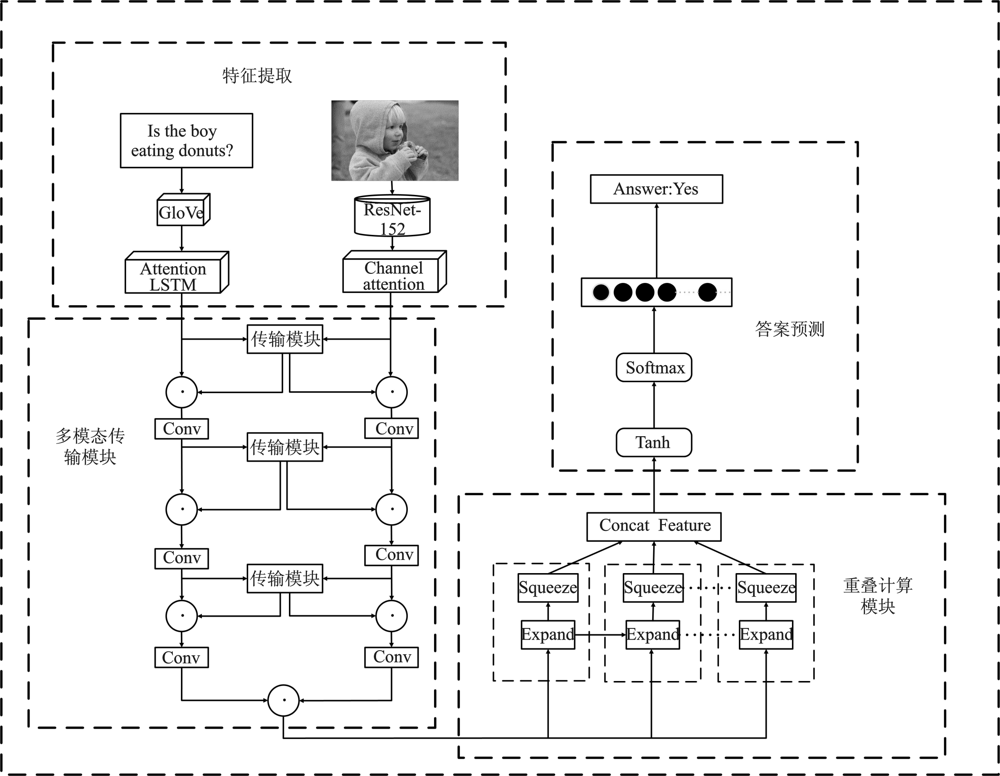
| [1] |
Peng L, Yang Y, Zhang X, et al. Answer again: Improving VQA with cascaded-answering model[J]. IEEE Transactions on Knowledge and Data Engineering, 2020, 9(9):1-12.
doi: 10.1109/TKDE.1997.649323
|
| [2] |
Chen C, Han D, Wang J. Multimodal encoder-decoder attention networks for visual question answering[J]. IEEE Access, 2020(8):35662-35671.
|
| [3] |
Yu Z, Yu J, Xiang C, et al. Beyond bilinear: Generalized multimodal factorized high-order pooling for visual question answering[J]. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(12):5947-5959.
doi: 10.1109/TNNLS.2018.2817340
pmid: 29993847
|
| [4] |
Zeng D J, Zhou G H, Wang J. Residual self-attention for visual question answering[C]. Kuala Lumpur: Proceedings of the First International Conference on Electrical, Control and Instrumentation Engineering, 2019.
|
| [5] |
Li R Y, Jia J Y. Visual question answering with question representation update(QRU)[C]. Barcelona: Proceedings of the Thirtieth International Conference on Neural Information Processing Systems, 2016.
|
| [6] |
Lu J, Yang J, Batra D, et al. Hierarchical question-image co-attention for visual question answering[C]. Barcelona: Proceedings of the Thirtieth International Conference on Neural Information Processing Systems, 2016.
|
| [7] |
郑萌. 基于改进注意力机制模型的智能英语翻译方法研究[J]. 电子科技, 2020, 33(11):84-87.
|
|
Zheng Meng. Research on intelligent English translation method based on improved attention mechanism model[J]. Electronic Science and Technology, 2020, 33(11):84-87.
|
| [8] |
和文杰, 刘敬彪, 潘勉, 等. 基于Attention-CTC的自然场景文本识别算法[J]. 电子科技, 2019, 32(12):32-36.
|
|
He Wenjie, Liu Jingbiao, Pan Mian, et al. Natural scene text recognition algorithm based on Attention-CTC[J]. Electronic Science and Technology, 2019, 32(12):32-36.
|
| [9] |
Tian W D, He B, Wang N X, et al. Multi-channel co-attention network for visual question answering[C]. Glasgow: Proceedings of the International Joint Conference on Neural Networks, 2020.
|
| [10] |
Lao M R, Guo Y M, Wang H, et al. Cross-modal multistep fusion network with co-attention for visual question answering[J]. IEEE Access, 2018(6):31516-31524.
|
| [11] |
Yu Z, Yu J, Cui Y H, et al. Deep modular co-attention networks for visual question answering[C]. Long Beach: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019.
|
| [12] |
Gao P, Jiang Z, You H, et al. Dynamic fusion with intra-and inter-modality attention flow for visual question answering[C]. Long Beach: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019.
|
| [13] |
Pennington J, Socher R, Manning C D. Glove: Global vectors for word representation[C]. Doha: Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2014.
|
| [14] |
Gers F. Long short-term memory in recurrent neural networks[J]. Verlag Nicht Ermittelbar, 2001, 9(8):1735-1780.
|
| [15] |
He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]. Las Vegas: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016.
|
| [16] |
Antol S, Agrawal A, Lu J, et al. Vqa: Visual question answering[C]. Santiago: Proceedings of the IEEE International Conference on Computer Vision, 2015.
|
| [17] |
Yang Z C, He X D, Gao J F, et al. Stacked attention networks for image question answering[C]. Las Vegas: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016.
|
| [18] |
Xiong C, Merity S, Socher R. Dynamic memory networks for visual and textual question answering[C]. New York: Proceedings of the International Conference on Machine Learning, 2016.
|
| [19] |
Yu D F, Fu J L, Mei T, et al. Multi-level attention networks for visual question answering[C]. Honolulu: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017.
|