

Journal of Xidian University ›› 2021, Vol. 48 ›› Issue (6): 161-171.doi: 10.19665/j.issn1001-2400.2021.06.020
• Computer Science and Technology • Previous Articles Next Articles
ZHANG Chunxiang( ),ZHOU Xuesong(),GAO Xueyao(),LIU Huan()
),ZHOU Xuesong(),GAO Xueyao(),LIU Huan()
Received:2020-03-11
Online:2021-12-20
Published:2022-02-24
Contact:
Xueyao GAO
E-mail:z6c6x666@163.com;1583829471@qq.com;xueyao_gao@163.com;18473681@qq.com
CLC Number:
ZHANG Chunxiang,ZHOU Xuesong,GAO Xueyao,LIU Huan. Semi-supervised word sense disambiguation by combining k-means clustering and the LSTM network[J].Journal of Xidian University, 2021, 48(6): 161-171.
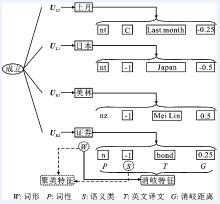
"
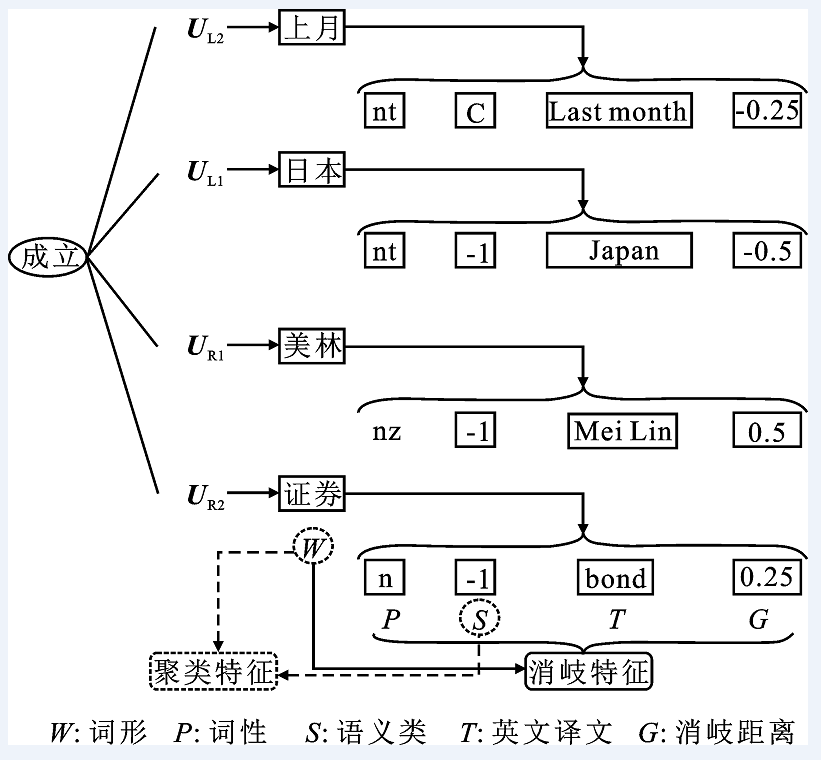
"
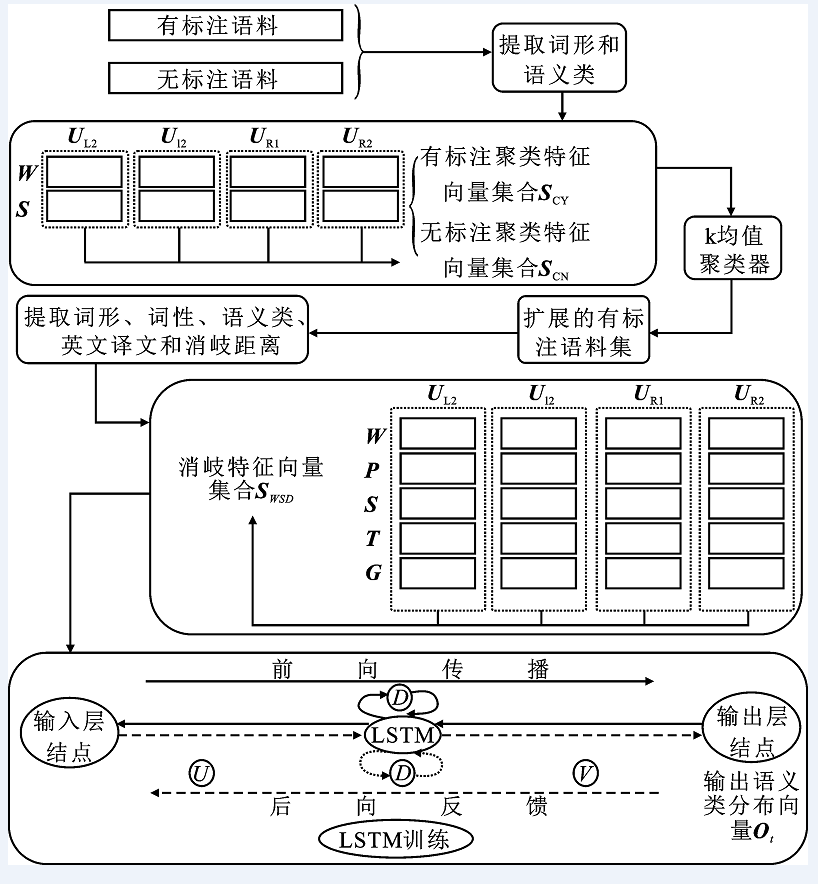
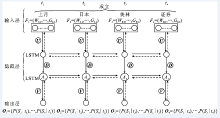
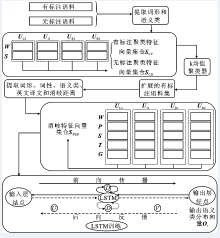
"
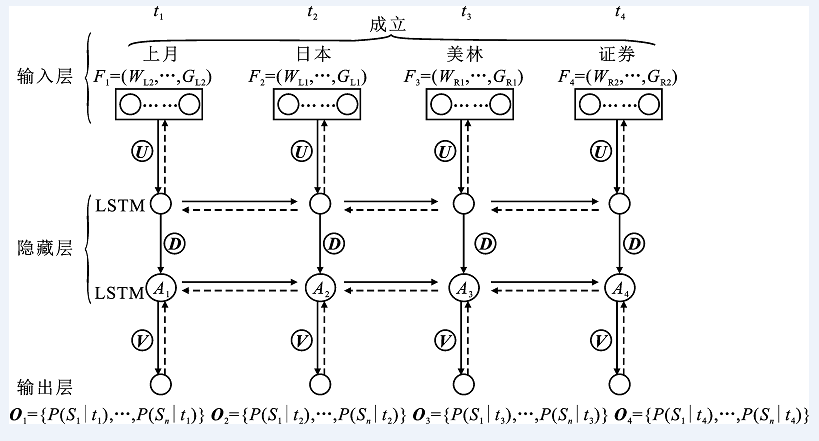
"
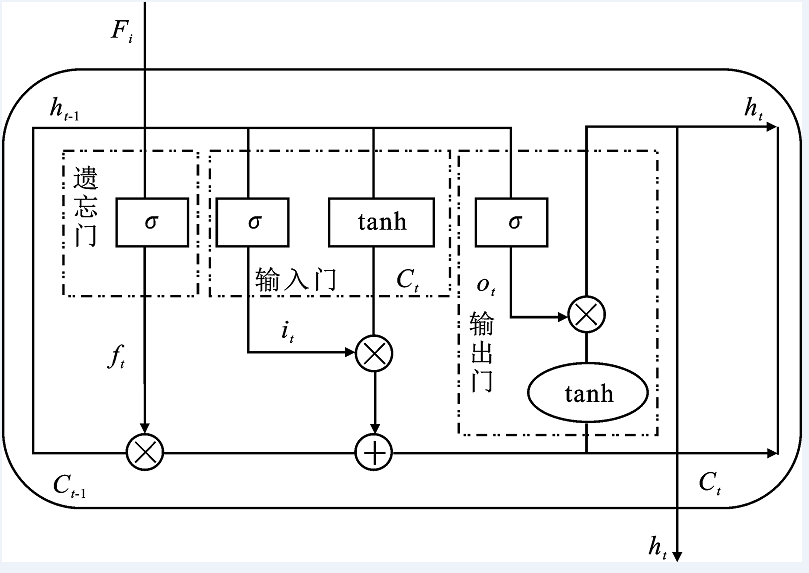
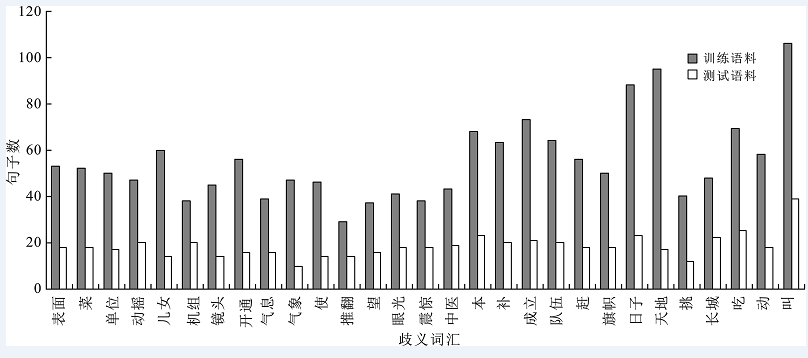
"
"
| 歧义词汇 | 2层 | 3层 | 4层 | 歧义词汇 | 2层 | 3层 | 4层 |
|---|---|---|---|---|---|---|---|
| 表面(2) | 0.611 | 0.667 | 0.722 | 中医(2) | 0.750 | 0.938 | 0.813 |
| 菜(2) | 0.667 | 0.611 | 0.500 | 本(3) | 0.480 | 0.440 | 0.600 |
| 单位(2) | 0.765 | 0.882 | 0.706 | 补(3) | 0.750 | 0.750 | 0.600 |
| 动摇(2) | 0.875 | 0.950 | 0.938 | 成立(3) | 0.700 | 0.733 | 0.733 |
| 儿女(2) | 0.900 | 0.950 | 0.950 | 队伍(3) | 0.455 | 0.318 | 0.318 |
| 机组(2) | 0.950 | 0.950 | 0.950 | 赶(3) | 0.611 | 0.278 | 0.500 |
| 镜头(2) | 0.667 | 0.533 | 0.533 | 旗帜(3) | 0.611 | 0.556 | 0.667 |
| 开通(2) | 0.950 | 0.950 | 0.900 | 日子(3) | 0.500 | 0.469 | 0.438 |
| 气息(2) | 0.714 | 0.706 | 0.53 | 天地(3) | 0.400 | 0.320 | 0.440 |
| 气象(2) | 0.875 | 0.813 | 0.813 | 挑(3) | 0.571 | 0.571 | 0.357 |
| 使(2) | 0.750 | 0.625 | 0.688 | 长城(3) | 0.476 | 0.381 | 0.381 |
| 推翻(2) | 0.600 | 0.700 | 0.700 | 吃(4) | 0.478 | 0.478 | 0.522 |
| 望(2) | 0.923 | 0.769 | 0.600 | 动(4) | 0.500 | 0.550 | 0.450 |
| 眼光(2) | 0.714 | 0.643 | 0.714 | 叫(4) | 0.375 | 0.476 | 0.425 |
| 震惊(2) | 0.786 | 0.714 | 0.857 | Pmar | 0.669 | 0.646 | 0.633 |
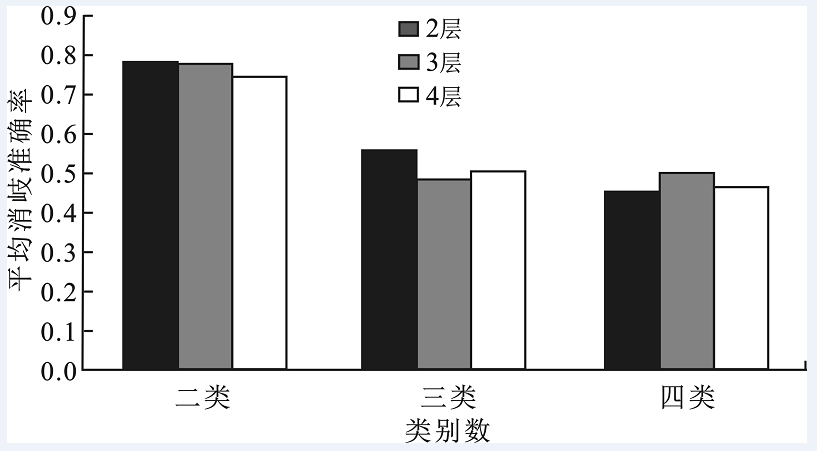
"
"
| 岐义词汇 | 无标注语料添加比例 | ||||
|---|---|---|---|---|---|
| 0% | 20% | 40% | 60% | 80% | |
| 表面(2) | 0.611 | 0.722 | 0.778 | 0.720 | 0.850 |
| 菜(2) | 0.667 | 0.667 | 0.714 | 0.710 | 0.765 |
| 单位(2) | 0.765 | 0.765 | 0.706 | 0.690 | 0.778 |
| 动摇(2) | 0.875 | 0.876 | 0.813 | 0.880 | 0.950 |
| 儿女(2) | 0.900 | 0.800 | 0.900 | 0.950 | 0.900 |
| 机组(2) | 0.950 | 0.950 | 0.950 | 0.930 | 0.929 |
| 镜头(2) | 0.667 | 0.667 | 0.633 | 0.650 | 0.692 |
| 开通(2) | 0.950 | 0.950 | 0.923 | 0.930 | 0.960 |
| 气息(2) | 0.714 | 0.714 | 0.733 | 0.750 | 0.733 |
| 气象(2) | 0.875 | 0.875 | 0.833 | 0.880 | 0.876 |
| 使(2) | 0.750 | 0.688 | 0.750 | 0.810 | 0.813 |
| 推翻(2) | 0.600 | 0.600 | 0.500 | 0.700 | 0.600 |
| 望(2) | 0.923 | 0.923 | 0.929 | 0.950 | 0.929 |
| 眼光(2) | 0.714 | 0.643 | 0.643 | 0.640 | 0.714 |
| 震惊(2) | 0.786 | 0.828 | 0.714 | 0.860 | 0.857 |
| 中医(2) | 0.750 | 0.625 | 0.813 | 0.690 | 0.688 |
| 本(3) | 0.480 | 0.500 | 0.500 | 0.520 | 0.640 |
| 补(3) | 0.750 | 0.750 | 0.633 | 0.770 | 0.609 |
| 成立(3) | 0.700 | 0.700 | 0.700 | 0.800 | 0.700 |
| 队伍(3) | 0.318 | 0.500 | 0.500 | 0.590 | 0.409 |
| 赶(3) | 0.611 | 0.500 | 0.722 | 0.500 | 0.667 |
| 旗帜(3) | 0.611 | 0.667 | 0.667 | 0.610 | 0.667 |
| 日子(3) | 0.500 | 0.406 | 0.438 | 0.470 | 0.500 |
| 天地(3) | 0.400 | 0.400 | 0.320 | 0.280 | 0.640 |
| 挑(3) | 0.571 | 0.571 | 0.429 | 0.430 | 0.500 |
| 长城(3) | 0.476 | 0.381 | 0.524 | 0.480 | 0.429 |
| 吃(4) | 0.478 | 0.522 | 0.652 | 0.440 | 0.522 |
| 动(4) | 0.500 | 0.600 | 0.364 | 0.500 | 0.500 |
| 叫(4) | 0.375 | 0.475 | 0.550 | 0.500 | 0.475 |
| Pmar | 0.664 | 0.664 | 0.667 | 0.677 | 0.700 |
"
| 歧义词汇 | 实验1 | 实验2 | 实验3 | 歧义词汇 | 实验1 | 实验2 | 实验3 |
|---|---|---|---|---|---|---|---|
| 表面(2) | 0.500 | 0.667 | 0.876 | 中医(2) | 0.375 | 0.625 | 0.750 |
| 菜(2) | 0.333 | 0.667 | 0.876 | 本(3) | 0.680 | 0.579 | 0.813 |
| 单位(2) | 0.471 | 0.647 | 0.785 | 补(3) | 0.400 | 0.600 | 0.640 |
| 动摇(2) | 0.750 | 0.813 | 0.826 | 成立(3) | 0.609 | 0.546 | 0.700 |
| 儿女(2) | 0.500 | 0.600 | 0.938 | 队伍(3) | 0.364 | 0.840 | 0.733 |
| 机组(2) | 0.714 | 0.857 | 0.980 | 赶(3) | 0.143 | 0.600 | 0.591 |
| 镜头(2) | 0.600 | 0.667 | 0.950 | 旗帜(3) | 0.556 | 0.667 | 0.667 |
| 开通(2) | 0.700 | 0.800 | 0.733 | 日子(3) | 0.469 | 0.308 | 0.611 |
| 气息(2) | 0.643 | 0.785 | 0.970 | 天地(3) | 0.720 | 0.714 | 0.500 |
| 气象(2) | 0.430 | 0.688 | 0.750 | 挑(3) | 0.500 | 0.525 | 0.440 |
| 使(2) | 0.625 | 0.688 | 0.813 | 长城(3) | 0.278 | 0.542 | 0.571 |
| 推翻(2) | 0.560 | 0.700 | 0.700 | 吃(4) | 0.633 | 0.579 | 0.429 |
| 望(2) | 0.700 | 0.385 | 0.950 | 动(4) | 0.600 | 0.722 | 0.522 |
| 眼光(2) | 0.714 | 0.600 | 0.714 | 叫(4) | 0.530 | 0.546 | 0.550 |
| 震惊(2) | 0.733 | 0.650 | 0.929 | Pmar | 0.546 | 0.642 | 0.735 |
| [1] | 杨陟卓, 黄河燕. 基于词语距离的网络图词义消歧[J]. 软件学报, 2012, 23(4):776-785. |
| YANG Zhizhuo, HUANG Heyan. Graph Based Word Sense Disambiguation Method Using Distance Between Words[J]. Journal of Software, 2012, 23(4):776-785. | |
| [2] | 钱涛, 姬东鸿, 戴文华. 一个基于超图的词义归纳模型[J]. 四川大学学报:工程科学版, 2016, 48(1):152-157. |
| QIAN Tao, JI Donghong, DAI Wenhua. A Hypergraph Model for Word Sense Induction[J]. Journal of Sichuan University:Engineering Science Edition, 2016, 48(1):152-157. | |
| [3] | BORDES A, GLOROT X, WESTON J, et al. A Semantic Matching Energy Function for Learning With Multi-Relational Data:Application to Word Sense Disambiguation[J]. Machine Language, 2014, 94(2):233-259. |
| [4] |
DUQUE A, STEVENSON M, MARTINEZ-ROMO J, et al. Co-Occurrence Graphs for Word Sense Disambiguation in the Biomedical Domain[J]. Artificial Intelligence in Medicine, 2018, 87:9-19.
doi: 10.1016/j.artmed.2018.03.002 |
| [5] |
TRIPODI R, PELILLO M, DELMONTE R, et al. A Evolutionary Game Theoretic Approach to Word Sense Disambiguation[J]. Computational Linguistics, 2017, 43(1):31-70.
doi: 10.1162/COLI_a_00274 |
| [6] |
ERK K, MCCARTHY D, GAYLORD N. Measuring Word Meaning in Context[J]. Computational Linguistics, 2013, 39(3):511-554.
doi: 10.1162/COLI_a_00142 |
| [7] | LOPEZ-AREVALLO I, SOSA-SOSA V J, ROJAS-LOPEZ F, et al. Improving Selection of Synsets from WordNet for Domain-Specific Word Sense Disambiguation[J]. Computer Speech & Language, 2017, 41:128-145. |
| [8] |
ALIAN M, AWAJAN A, AI-KOUZ A. Word Sense Disambiguation for Arabic Text Using Wikipedia and Vector Space Model[J]. International Journal of Speech Technology, 2016, 19(4):857-867.
doi: 10.1007/s10772-016-9376-y |
| [9] |
ANTONIOD M, ROBERTO N. Clustering and Diversifying Web Search Results with Graph-Based Word Sense Induction[J]. Computational Linguistics, 2013, 39(3):709-754.
doi: 10.1162/COLI_a_00148 |
| [10] | 杨路辉, 刘光杰, 翟江涛, 等. 一种改进的卷积神经网络恶意域名检测算法[J]. 西安电子科技大学学报, 2020, 47(1):37-43. |
| YANG Luhui, LIU Guangjie, ZHAI Jiangtao, et al. Improved Algorithm for Detection of the Malicious Domain Name Based on the Convolutional Neural Network[J]. Journal of Xidian University, 2020, 47(1):37-43. | |
| [11] | 曹卫东, 李嘉琪, 王怀超. 采用注意力门控卷积网络模型的目标情感分析[J]. 西安电子科技大学学报, 2019, 46(6):30-36. |
| CAO Weidong, LI Jiaqi, WANG Huaichao. Analysis of Targeted Sentiment by the Attention Gated Convolutional Network Model[J]. Journal of Xidian University, 2019, 46(6):30-36. | |
| [12] | 张志昌, 张治满, 张珍文. 融合局部语义和全局结构信息的健康问句分类[J]. 西安电子科技大学学报, 2020, 47(2):9-15. |
| ZHANG Zhichang, ZHANG Zhiman, ZHANG Zhenwen. Classifying Health Questions with Local Semantic and Global Structural Information[J]. Journal of Xidian University, 2020, 47(2):9-15. | |
| [13] |
PESARANGHADER A, MATWIN S, SOKOLOVA M, et al. DeepBioWSD:Effective Deep Neural Word Sense Disambiguation of Biomedical Text Data[J]. Journal of the American Medical Informatics Association, 2019, 26(5):438-446.
doi: 10.1093/jamia/ocy189 |
| [14] |
CALVO H, ROCHA-RAMIREZ A P, MORENO-ARMENDARIZ M A, et al. Toward Universal Word Sense Disambiguation Using Deep Neural Networks[J]. IEEE Access, 2019, 7:60264-60275.
doi: 10.1109/Access.6287639 |
| [15] |
RUAS T, GROSKY W, AIZAWA A. Multi-Sense Embeddings through A Word Sense Disambiguation Process[J]. Expert Systems with Applications, 2019, 136:288-303.
doi: 10.1016/j.eswa.2019.06.026 |
| [16] | MOHAMMED H, DIAS G, FERRARI S, et al. Identifying Temporal Orientation of Word Senses[C]// Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning.Berlin:CoNLL, 2016:22-30. |
| [17] | 范弘屹, 张仰森. 一种基于HowNet的词语语义相似度计算方法[J]. 北京信息科技大学学报, 2014, 29(4):42-45. |
| FAN Hongyi, ZHANG Yangsen. Computing Method for Semantic of Words Based on HowNet[J]. Journal of Beijing Information Science and Technology University, 2014, 29(4):42-45. | |
| [18] | 唐善成, 马付玉, 张镤月, 等. 采用Seq2Seq模型的非受限词义消歧方法[J]. 西北大学学报:自然科学版, 2019, 49(3):351-355. |
| TANG Shancheng, MA Fuyu, ZHANG Puyue, et al. Unrestricted Word Sense Disambiguation Method Using Seq2Seq Model[J]. Journal of Northwest University:Natural Science Edition, 2019, 49(3):351-355. | |
| [19] | 杨安, 李素建, 李芸. 基于领域知识和词向量的词义消歧方法[J]. 北京大学学报:自然科学版, 2017, 53(2):204-210. |
| YANG An, LI Sujian, LI Yun. Word Sense Disambiguation Based on Domain Knowledge and Word Vector Model[J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2017, 53(2):204-210. | |
| [20] |
LI Z, YANG F, LUO Y. Context Embedding Based on Bi-LSTM in Semi-Supervised Biomedical Word Sense Disambiguation[J]. IEEE Access, 2019, 7:72928-72935.
doi: 10.1109/Access.6287639 |
| [1] | LI Jinze,WANG Zhonghao,LI Mengheng,QIN Tuanfa. Spectrum sharing management method for the small-area-blockchain based on district partition [J]. Journal of Xidian University, 2020, 47(6): 122-130. |
| [2] | LI Zhao,YUAN Wenhao,REN Chongguang,HUANG Chengcheng,DONG Xiaoxiao. Approximate computing method based on cross-layer dynamic precision scaling for the k-means [J]. Journal of Xidian University, 2020, 47(3): 50-57. |
| [3] | LI Yong,CHENG Honghong,LIANG Xinyan,GUO Qian,QIAN Yuhua. CNN image caption generation [J]. Journal of Xidian University, 2019, 46(2): 152-157. |
| [4] | JIANG Jiewei, LIU Xiyang, LIU Lin, WANG Shuai, YANG Haoqing, CUI Jiangtao. Method for automatic prediction of the development trend of an ophthalmic disease [J]. Journal of Xidian University, 2018, 45(6): 19-25. |
| [5] | WANG Yunfei;BI Duyan;LIU Huawei;LIU Ling;ZHAO Xiaolin. Locally-restricted regular clustering superpixel algorithm [J]. Journal of Xidian University, 2016, 43(3): 95-100. |
|