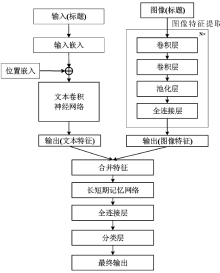
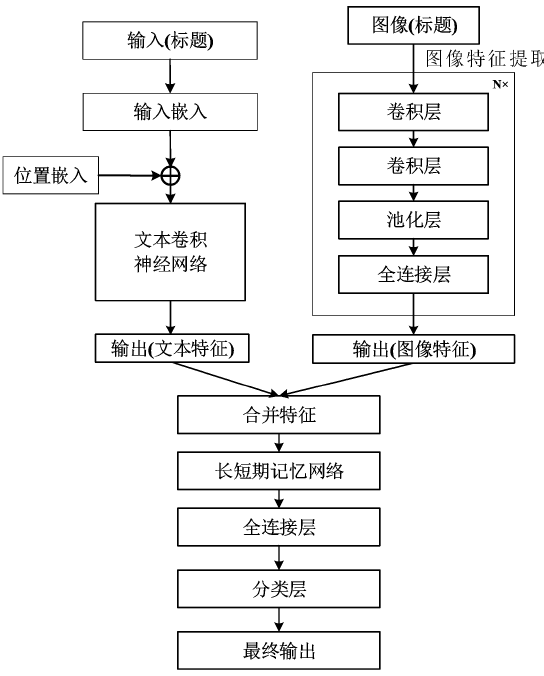
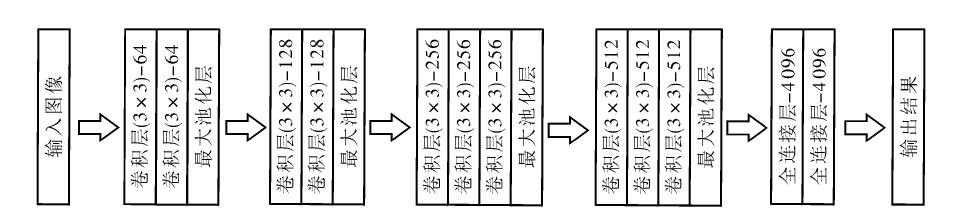
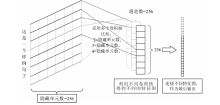
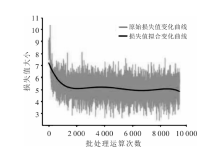
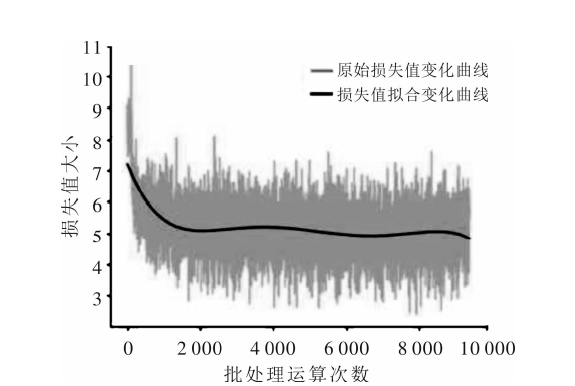
| [1] |
VINYALS O, TOSHEV A, BENGIO S , et al. Show and Tell: a Neural Image Caption Generator[C]// Proceedings of the 2015 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington: IEEE Computer Society, 2015: 3156-3164.
|
| [2] |
SZEGEDY C, LIU W, JIA Y Q , et al. Going Deeper with Convolutions[C]// Proceedings of the 2015 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington: IEEE Computer Society, 2015: 1-9.
|
| [3] |
KARPATHY A, LI F F . Deep Visual-semantic Alignments for Generating Image Descriptions[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017,39(4):664-676.
doi: 10.1109/TPAMI.2016.2598339
pmid: 27514036
|
| [4] |
许强, 李伟, 占荣辉 , 等. 一种改进的卷积神经网络SAR目标识别算法[J]. 西安电子科技大学学报, 2018,45(5):177-183.
|
|
XU Qiang, LI Wei, ZHAN Ronghui , et al. Improved Algorithm for SAR Target Recognition Based on the Convolutional Neural Network[J]. Journal of Xidian University, 2018,45(5):177-183.
|
| [5] |
LU J, XIONG C, PARIKH D , et al. Knowing When to Look: Adaptive Attention via a Visual Sentinel for Image Captioning[C]// Proceedings of the 2017 30th IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 3242-3250.
|
| [6] |
WANG Y, LIN Z, SHEN X , et al. Skeleton Key: Image Captioning by Skeleton-attribute Decomposition[C]// Proceedings of the 2017 30th IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 7378-7387.
|
| [7] |
张金刚, 方圆, 袁豪 , 等. 一种识别表情序列的卷积神经网络[J]. 西安电子科技大学学报, 2018,45(1):150-155.
doi: 10.3969/j.issn.1001-2400.2018.01.027
|
|
ZHANG Jingang, FANG Yuan, YUAN Hao , et al. Multiple Convolutional Neural Networks for Facial Expression Sequence Recognition[J]. Journal of Xidian University, 2018,45(1):150-155.
doi: 10.3969/j.issn.1001-2400.2018.01.027
|
| [8] |
SANTORO A, RAPOSO D, BARRETT D G T , et al. A Simple Neural Network Module for Relational Reasoning[C]// Advances in Neural Information Processing Systems. Vancouver, Canada: Neural Information Processing System Foundation, 2017: 4968-4977.
|
| [9] |
REN Z, WANG X, ZHANG N , et al. Deep Reinforcement Learning-based Image Captioning with Embedding Reward[C]// Proceedings of the 2017 30th IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1151-1159.
|