

Journal of Xidian University ›› 2022, Vol. 49 ›› Issue (2): 108-115.doi: 10.19665/j.issn1001-2400.2022.02.013
• Information and Communications Engineering • Previous Articles Next Articles
ZHANG Min( ),JIA Hairong(),ZHANG Gangmin(),WANG Suying()
),JIA Hairong(),ZHANG Gangmin(),WANG Suying()
Received:2020-10-28
Online:2022-04-20
Published:2022-05-31
Contact:
Hairong JIA
E-mail:1640167660@qq.com;helenjia722@163.com;1353430842@qq.com;2356275208@qq.com
CLC Number:
ZHANG Min,JIA Hairong,ZHANG Gangmin,WANG Suying. Speech enhancement combining the self-adaptive soft mask and mixed features[J].Journal of Xidian University, 2022, 49(2): 108-115.
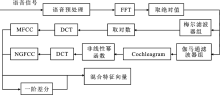
"
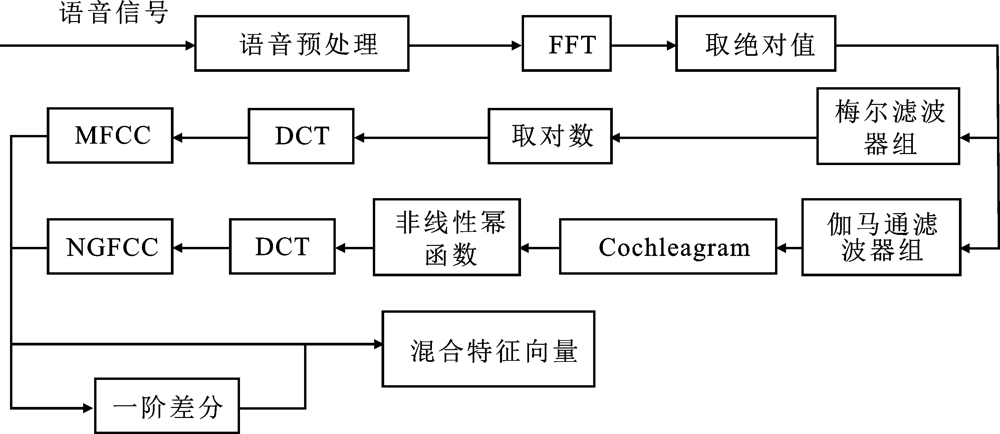
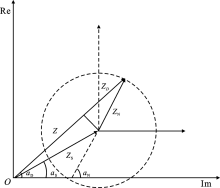
"
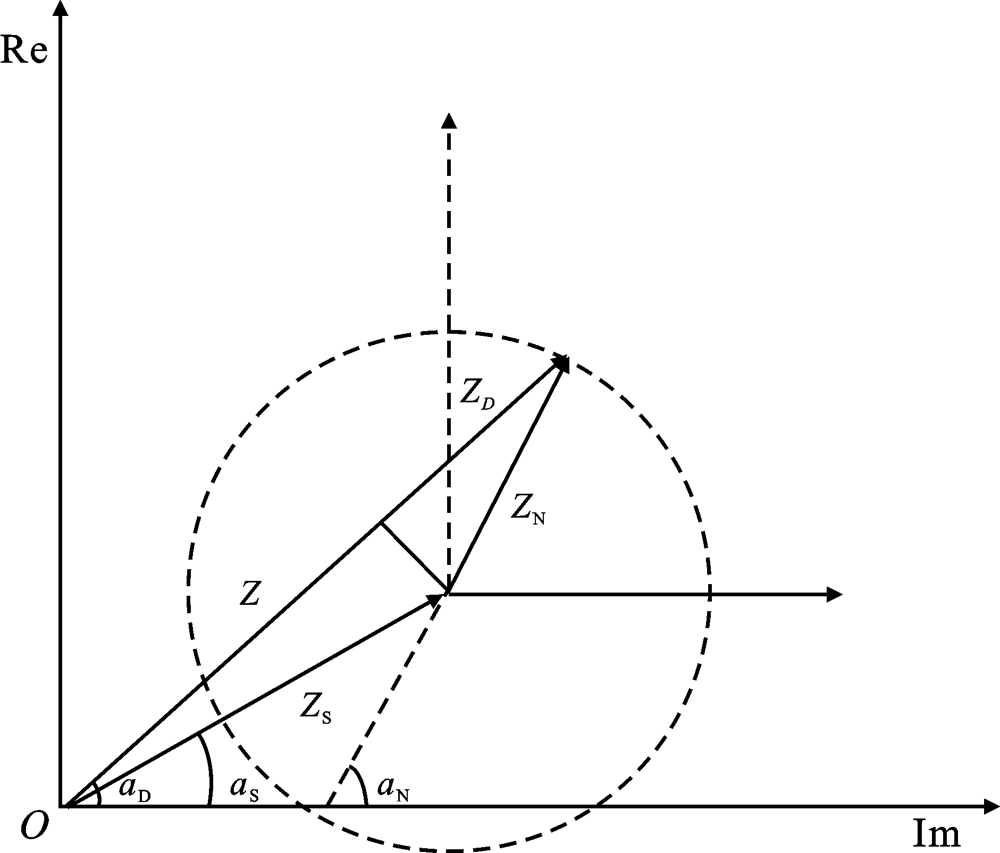
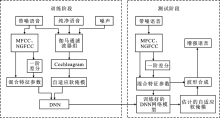
"
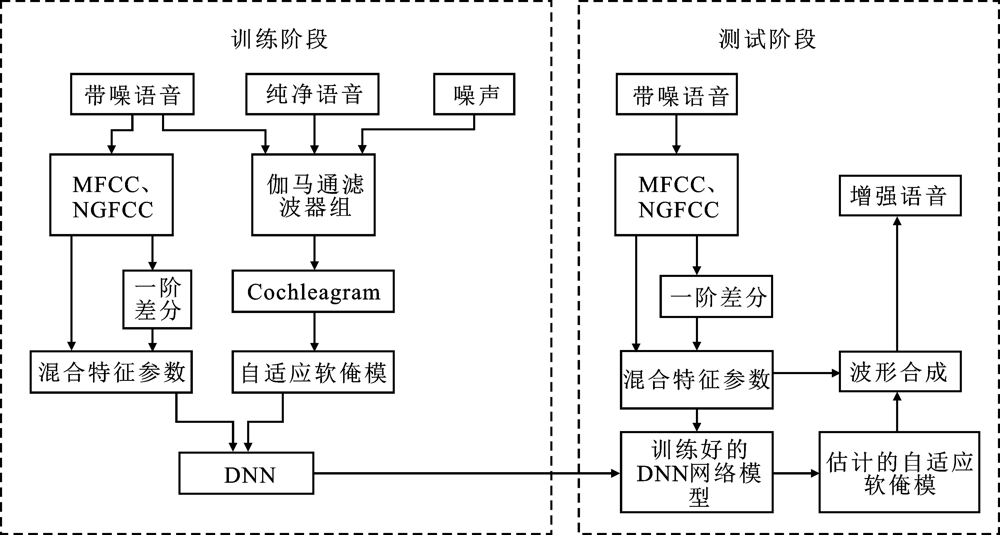
"
| 噪声 | 信噪比/dB | PESQ | |||
|---|---|---|---|---|---|
| noisy | 实验1 | 实验2 | 实验3 | ||
| factory | -5 | 1.343 8 | 1.531 7 | 1.543 2 | 1.858 1 |
| 0 | 1.582 3 | 1.866 0 | 2.126 3 | 2.318 3 | |
| 5 | 1.901 4 | 2.423 2 | 2.538 6 | 2.699 7 | |
| white | -5 | 1.310 9 | 1.846 5 | 1.959 4 | 2.211 3 |
| 0 | 1.497 7 | 2.235 6 | 2.379 7 | 2.465 2 | |
| 5 | 1.767 7 | 2.633 6 | 2.718 1 | 2.891 2 | |
| pink | -5 | 1.229 7 | 1.541 8 | 1.755 8 | 1.984 2 |
| 0 | 1.516 5 | 2.049 6 | 2.199 2 | 2.389 4 | |
| 5 | 1.845 1 | 2.486 2 | 2.646 7 | 2.812 3 | |
"
| 噪声 | 信噪比/dB | STOI | |||
|---|---|---|---|---|---|
| noisy | 实验1 | 实验2 | 实验3 | ||
| factory | -5 | 0.562 2 | 0.627 6 | 0.647 3 | 0.682 4 |
| 0 | 0.666 8 | 0.755 2 | 0.789 3 | 0.794 5 | |
| 5 | 0.780 1 | 0.866 3 | 0.879 8 | 0.887 9 | |
| white | -5 | 0.652 2 | 0.757 6 | 0.757 8 | 0.774 6 |
| 0 | 0.735 2 | 0.837 5 | 0.831 7 | 0.849 7 | |
| 5 | 0.810 5 | 0.897 7 | 0.891 7 | 0.900 1 | |
| pink | -5 | 0.584 5 | 0.685 9 | 0.720 0 | 0.736 9 |
| 0 | 0.685 9 | 0.806 3 | 0.820 5 | 0.830 1 | |
| 5 | 0.792 3 | 0.883 4 | 0.891 1 | 0.906 7 | |

"
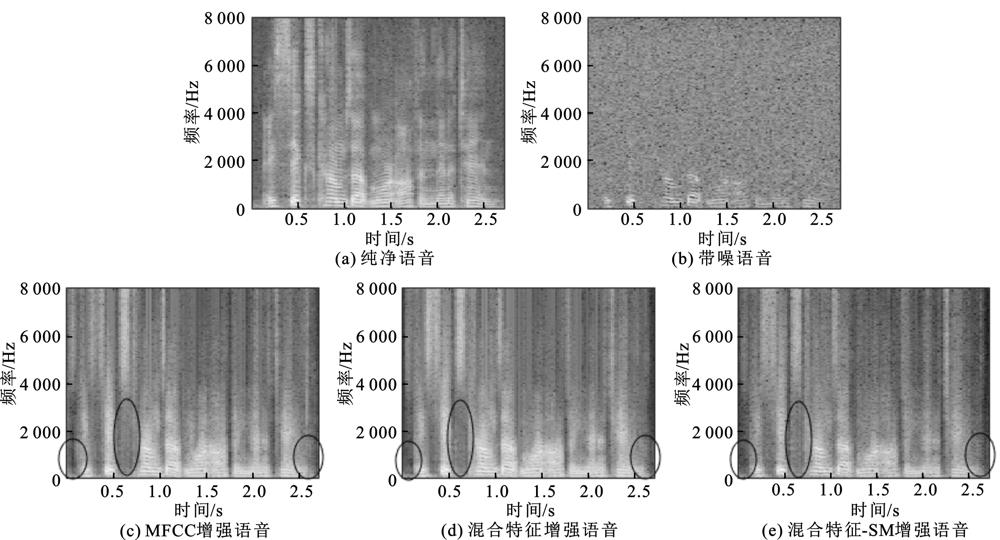
| [1] |
BAO F, ABDULLA W H. A New Ratio Mask Representation for CASA-Based Speech Enhancement[J]. IEEE/ACM Transactions on Audio,Speech and Language Processing, 2019, 27(1):7-19.
doi: 10.1109/TASLP.2018.2868407 |
| [2] | 白静, 史燕燕, 薛珮芸, 等. 融合非线性幂函数和谱减法的CFCC特征提取[J]. 西安电子科技大学学报, 2019, 46(1):86-92. |
| BAI Jing, SHI Yanyan, XUE Peiyun, et al. CFCC Feature Extraction for Fusion of the Power-Law Nonlinearity Function and Spectral Subtraction[J]. Journal of Xidian University, 2019, 46(1):86-92. | |
| [3] | 尹向雷, 郑恩让, 马令坤, 等. 基于掩蔽效应的维纳滤波器语音增强及DSP实现[J]. 电子技术应用, 2010, 36(4):123-126. |
| YIN Xianglei, ZHENG Enrang, MA Lingkun, et al. Speech Enhancement and DSP Implementation of Wiener Filter Based on Masking Effect[J]. Application of Electronic Technique, 2010, 36(4):123-126. | |
| [4] |
WANG Y, NARAYANAN A, WANG D L. On Training Targets for Supervised Speech Separation[J]. IEEE/ACM Transactions on Audio,Speech and Language Processing, 2014, 22(12):1849-1858.
doi: 10.1109/TASLP.2014.2352935 |
| [5] |
KANG T G, SHIN J W, KIM N S. DNN-Based Monaural Speech Enhancement with Temporal and Spectral Variations Equalization[J]. Digital Signal Processing, 2018, 74:102-110.
doi: 10.1016/j.dsp.2017.12.002 |
| [6] |
KIM C, STERN R M. Power-Normalized Cepstral Coefficients (PNCC) for Robust Speech Recognition[J]. IEEE/ACM Transactions on Audio,Speech and Language Processing, 2016, 24(7):1315-1329.
doi: 10.1109/TASLP.2016.2545928 |
| [7] |
CHEN J T, WANG Y X, WANG D L, et al. A Feature Study for Classification-Based Speech Separation at Low Signal-to-Noise Ratios[J]. IEEE/ACM Transactions on Audio,Speech and Language Processing, 2014, 22(12):1993-2002.
doi: 10.1109/TASLP.2014.2359159 |
| [8] | 王雁, 贾海蓉, 吉慧芳, 等. 特征联合优化深度信念网络的语音增强算法[J]. 计算机工程与应用, 2019, 55(9):38-42. |
| WANG Yan, JIA Hairong, JI Huifang, et al. Feature Joint Optimization of Deep Belief Network for Speech Enhancement[J]. Computer Engineering and Applications, 2019, 55(9):38-42. | |
| [9] | 余琳, 姜囡. 基于Gammatone滤波器的混合特征语音情感识别[J]. 光电技术应用, 2020, 35(3):50-54. |
| YU Lin, JIANG Nan. Speech Emotion Recognition with Mixed Features Based on Gammatone Filter[J]. Electro-Optic Technology Application, 2020, 35(3):50-54. | |
| [10] | 郭卉, 姜囡, 任杰. 基于MFCC和GFCC混合特征的语音情感识别研究[J]. 光电技术应用, 2019, 34(6):34-39. |
| GUO Hui, JIANG Nan, REN Jie. Research on Speech Emotion Recognition Based on Mixed Features of MFCC and GFCC[J]. Electro-Optic Technology Application, 2019, 34(6):34-39. | |
| [11] | 李如玮, 孙晓月, 刘亚楠, 等. 基于深度学习的听觉倒谱系数语音增强算法[J]. 华中科技大学学报:自然科学版, 2019, 47(9):78-83. |
| LI Ruwei, SUN Xiaoyue, LIU Yanan, et al. Speech Enhancement Based on Auditory Cepstral Coefficient with Deep Learning[J]. Journal of Huazhong University of Science and Technology:Nature Science Edition, 2019, 47(9):78-83. | |
| [12] | 贾海蓉, 王卫梅, 吉慧芳. 信噪比信息与时频特征修正相位的语音增强[J]. 西安电子科技大学学报, 2019, 46(5):162-170. |
| JIA Hairong, WANG Weimei, JI Huifang. SpeechEnhancement Based on the Modified Phase Using Signal-to-Noise Ratio Information and Time-frequency Characteristics[J]. Journal of Xidian University, 2019, 46(5):162-170. | |
| [13] |
ROMERO E, MAZZANTI F, DELGADO J, et al. Weighted Contrastive Divergence[J]. Neural Networks, 2019, 114:147-156.
doi: 10.1016/j.neunet.2018.09.013 |
| [14] |
HU Y, LOIZOU P C. Evaluation of Objective Quality Measures for Speech Enhancement[J]. IEEE Transactions on Audio,Speech and Language Processing, 2008, 16(1):229-238.
doi: 10.1109/TASL.2007.911054 |
| [15] |
TAAL C H, HENDRIKS R C, HEUSDENS R, et al. An Algorithm for Intelligibility Prediction of Time-Frequency Weighted Noisy Speech[J]. IEEE Transactions on Audio,Speech and Language Processing, 2011, 19(7):2125-2136.
doi: 10.1109/TASL.2011.2114881 |
| [1] | ZHANG Yang,ZHENG Guotian,ZHANG Jian,PANG Lihua,LUAN Yingzi. Low complexity preamble detection algorithm in the low SNR region [J]. Journal of Xidian University, 2022, 49(2): 1-10. |
| [2] | LIN Hongbo,MA Yang. Spatially adaptive EPLL denoising for low-frequency seismic random noise [J]. Journal of Xidian University, 2021, 48(6): 204-211. |
| [3] | LV Wenkai,YANG Pengfei,DING Yunqing,ZHANG Heyu,ZHENG Tianyang. JEDERL:A task scheduling optimization algorithm for heterogeneous computing platforms [J]. Journal of Xidian University, 2021, 48(6): 67-74. |
| [4] | ZHANG Yuhao,CHENG Peitao,ZHANG Shuhao,WANG Xiumei. Lightweight image super-resolution with the adaptive weight learning network [J]. Journal of Xidian University, 2021, 48(5): 15-22. |
| [5] | SONG Jianqiao,WANG Feng,NIU Jin,SHI Zezhou,MA Junhui. Potential emotion recognition based on the fusion of the spatio-temporal neural network and facial pulse signals [J]. Journal of Xidian University, 2021, 48(4): 159-167. |
| [6] | HUI Haisheng,ZHANG Xueying,WU Zelin,LI Fenglian. Method for stroke lesion segmentation using the primary-auxiliary path attention compensation network [J]. Journal of Xidian University, 2021, 48(4): 200-208. |
| [7] | CAO Yi,CAI Xiaodong. Effective learning strategy for hard samples [J]. Journal of Xidian University, 2021, 48(3): 99-105. |
| [8] | WANG Ping,JIANG Yuze,ZHAO Guanghui. Object detection based on the multiscale location Enhancement network [J]. Journal of Xidian University, 2021, 48(3): 85-90. |
| [9] | MEI Shulin,JIA Hairong,WANG Xiaogang,WU Yifeng. Combination of dynamic features with a new mask to optimize neural network speech enhancement [J]. Journal of Xidian University, 2021, 48(3): 91-98. |
| [10] | GUO Zekun,TIAN Long,HAN Ning,WANG Penghui,LIU Hongwei,CHEN Bo. Radar HRRP based few-shot target recognition with CNN-SSD [J]. Journal of Xidian University, 2021, 48(2): 7-14. |
| [11] | ZHANG Shudong,GAO Haichang,CAO Xiwen,KANG Shuai. Adaptive fast and targeted adversarial attack for speech recognition [J]. Journal of Xidian University, 2021, 48(1): 168-175. |
| [12] | ZHOU Yu,CHEN Zhixiong,ZHUO Zepeng,DU Xiaoni. Survey of results of (n,m)-functions against differential power attack [J]. Journal of Xidian University, 2021, 48(1): 50-60. |
| [13] | DANG Jisheng,YANG Jun. 3D model recognition and segmentation based on multi-feature fusion [J]. Journal of Xidian University, 2020, 47(4): 149-157. |
| [14] | LI Kunlun,ZHANG Lu,XU Hongke,SONG Huansheng. Waveletdomain dilated network for fast low-dose CT image reconstruction [J]. Journal of Xidian University, 2020, 47(4): 86-93. |
| [15] | NGUYEN Van-Truong,CAI Jueping,WEI Linyu,CHU Jie. Low complexity probability-based piecewise linear approximation of the sigmoid function [J]. Journal of Xidian University, 2020, 47(3): 58-65. |
|