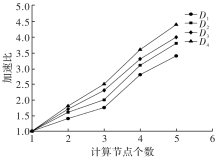
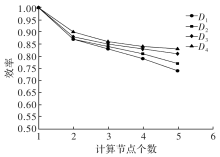
| [1] |
Kulkarni V Y, Sinha P K . Efficient learning of random forest classifier using disjoint partitioning approach[J]. Proceedings of the World Congress on Engineering, 2013,2(5):1-5.
|
| [2] |
Mi Y . Imbalanced classification based on active learning SMOTE[J]. Research Journal of Applied Sciences Engineering & Technology, 2013,5(3):944-949.
|
| [3] |
Amaratunga D Cabrera J Lee Y S . Enriched random forests[J]. Bioinformatics, 2008,24(18):2010-2014.
doi: 10.1093/bioinformatics/btn356
|
| [4] |
Xu B X, Huang J Z, Williams G , et al. Classifying very high-dimensional data with random forests built from small subspaces[J]. International Journal of Data Warehousing and Mining, 2011,8(2):44-63.
doi: 10.4018/jdwm.2012040103
|
| [5] |
Ye Y M, Wu Q Y, Huang J Z , et al. Stratified sampling for feature subspace selection in random forests for high dimensional data[J]. Pattern Recognition, 2013,46(3):769-787.
doi: 10.1016/j.patcog.2012.09.005
|
| [6] |
Sun K, Miao W, Zhang X, et al. An improvement to feature selection of random forests on Spark [C].Chengdu:2014 IEEE 17 th International Conference on Computational Science and Engineering , 2014.
|
| [7] |
Wu X, Zhu X, Wu G Q . Data mining with big data[J]. IEEE Transactions on Knowledge Data Engineering, 2014,26(1):97-107.
doi: 10.1109/TKDE.2013.109
|
| [8] |
Kuang L, Hao F, Yang L T , et.al. A tensor-based approach for big data representation and dimensionality reduction[J]. IEEE Transactions on Emerge Topics Computer, 2014,2(3):280-291.
doi: 10.1109/TETC.2014.2330516
|
| [9] |
Zhang C, Yuan D. Fast fine-grained air quality index level prediction using random forest algorithm on cluster computing of Spark [C].Beijing: IEEE,UIC-ATC-ScalCom-CBDCom-Iop, 2015.
|
| [10] |
Dean J, Ghemawat S . MapReduce: simplified data processing on large clusters[J]. Communications of the ACM, 2008,51(1):107-113.
|
| [11] |
夏卫雷, 王立松 . 基于MapReduce的并行蚁群算法研究与实现[J]. 电子科技, 2013,26(2):146-149.
doi: 10.3969/j.issn.1007-7820.2013.02.046
|
|
Xia Weilei, Wang Lisong . Research on and implementation of parallel ant colony algorithm based on MapReduce[J]. Electronic Science and Technology, 2013,26(2):146-149.
doi: 10.3969/j.issn.1007-7820.2013.02.046
|
| [12] |
Dimple B, Sudarshan T . IBM text analytics on Apache Spark[M]. San Francisco:Saprk Summit, 2014.
|
| [13] |
Li W, Cheng H L, Peng Y. Visualized data mining platform based on the Spark [C].Hangzhou:Proceedings of the 16 th System Simulation Technology and Application , 2014.
|
| [14] |
Bian H Q, Chen Y G, Du X Y . Equal-join optimization on Spark[J]. Journal of East China Normal University :Natural Science, 2014,5(1):263-270.
|
| [15] |
Zhang J, Li T, Da R . A parallel method for computing rough set approximations[J]. Information Sciences, 2012,194(5):209-223.
doi: 10.1016/j.ins.2011.12.036
|
| [16] |
Zhu Weisheng, Wang Peng . Large-scale image retrieval solution based on hadoop cloud computing platform[J]. Journal of Computer Aplliction, 2014,34(3):695-699.
|