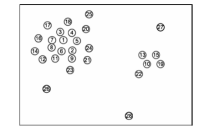
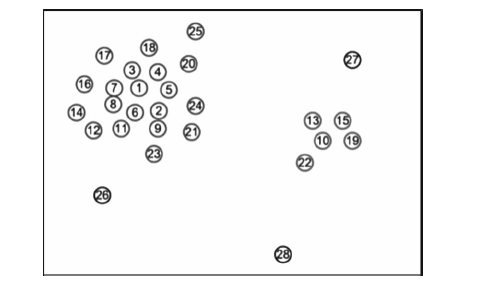
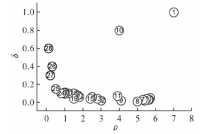
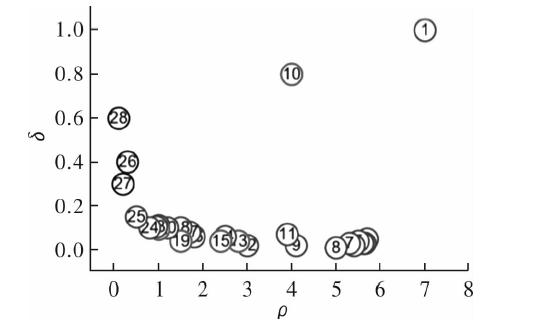
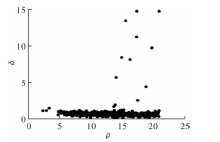
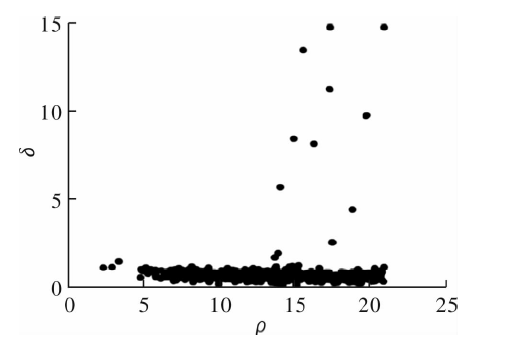
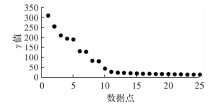
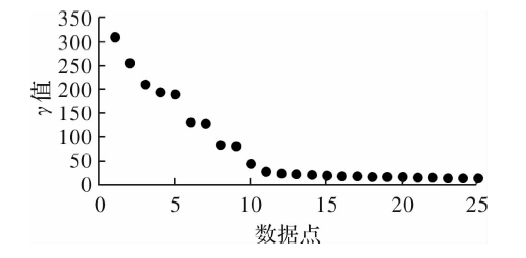
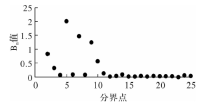
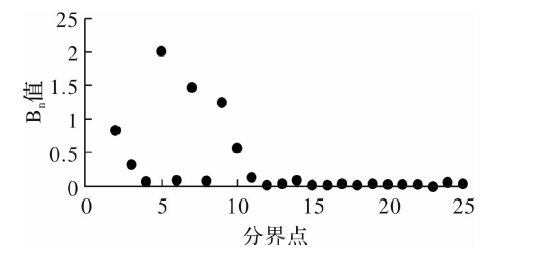
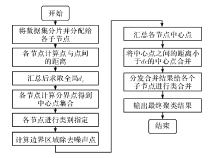
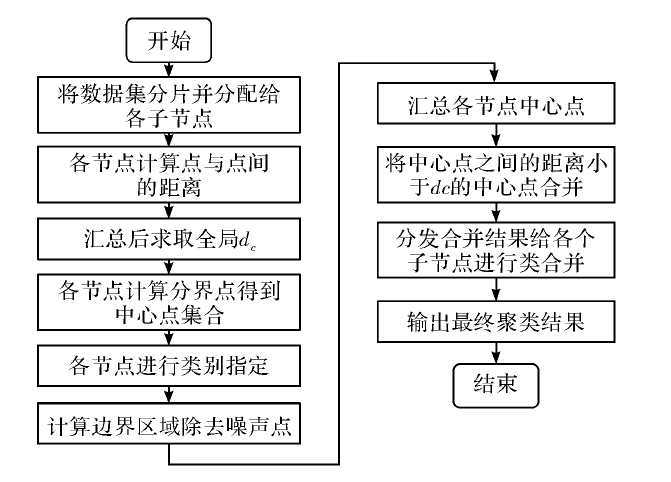
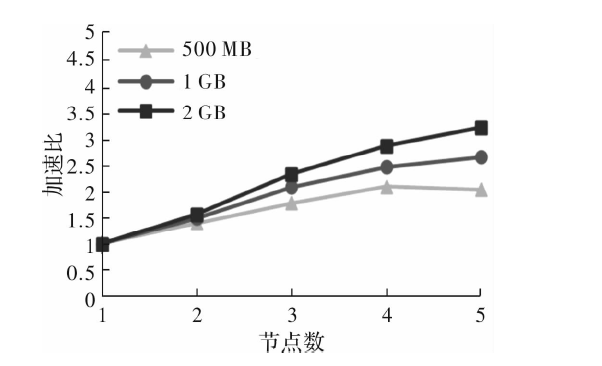
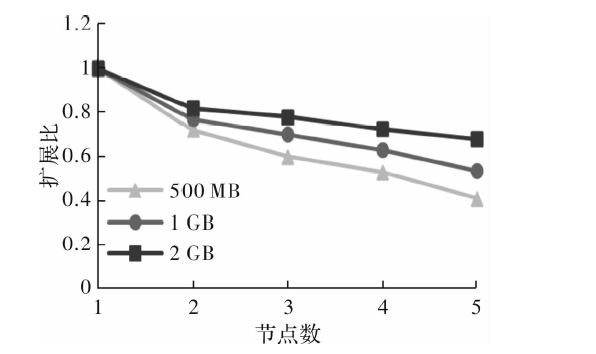
| [1] |
孙吉贵, 刘杰, 赵连宇 . 聚类算法研究[J]. 软件学报, 2008,19(1):48-61.
|
|
Sun Jigui, Liu Jie, Zhao Lianyu . Clustering algorithms research[J]. Journal of Software, 2008,19(1):48-61.
|
| [2] |
Jain A K, Dubes R C . Algorithms for clustering data[M]. New Jersy:Prentice Hall, 1988.
|
| [3] |
Zaharia M, Chowdhury M, Franklin M J, et al. Spark: cluster computing with working sets[C]. USENIX Association:Usenix Conference on Hot Topics in Cloud Computing, 2010.
|
| [4] |
Dean J, Ghemawat S . MapReduce: simplified data processing on large clusters[J]. Communications of the ACM, 2008,51(1):10-17.
|
| [5] |
Engle C, Lupher A, Xin R, et al. Shark:fast data analysis using coarse-grained distributed memory[C]. Scottsdale:ACM SIGMOD International Conference on Management of Data,ACM, 2012.
|
| [6] |
Rodriguez A, Laio A . Clustering by fast search and find of density peaks[J]. Science, 2014,344(6191):1492-1503.
|
| [7] |
杨洁, 王国胤, 庞紫玲 . 密度峰值聚类相关问题的研究[J]. 南京大学学报, 2017,53(4):791-801.
|
|
Yang Jie, Wang Guoyin, Pang Ziling . Relative researches of clustering by fast search and find of density peaks[J]. Journal of Nanjing University, 2017,53(4):791-801.
|
| [8] |
蒋礼青, 张明新, 郑金龙 , 等. 快速搜索与发现密度峰值聚类算法的优化研究[J]. 计算机应用研究, 2016,33(11):3251-3254.
|
|
Jiang Liqing, Zhang Mingxin, Zheng Jinlong , et al. Optimization of clustering by fast search and find of density peaks[J]. Application Research of Computers, 2016,33(11):3251-3254.
|
| [9] |
李敏, 张桂珠 . 密度峰值优化初始中心的K-means算法[J]. 计算机应用与软件, 2017,34(3):212-217.
|
|
Li Min, Zhang Guizhu . K-means algorithm of optimized initial center by density peaks[J]. Computer Applications and Software, 2017,34(3):212-217.
|
| [10] |
Wang S, Wang D, Li C , et al. Clustering by fast search and find of density peaks with data field[J]. Chinese Journal of Electronics, 2016,25(3):397-402.
doi: 10.1049/cje.2016.05.001
|
| [11] |
孙昊, 张明新, 戴娇 , 等. 基于网格的快速搜寻密度峰值的聚类算法优化研究[J]. 计算机工程与科学, 2017,39(5):964-970.
|
|
Sun Hao, Zhang Minxing, Dai Jiao , et al. Optimization of grid based clustering by fast search and find of density peaks[J]. Computer Engineering & Science, 2017,39(5):964-970.
|
| [12] |
戴娇, 张明新, 郑金龙 , 等. 基于密度峰值的快速聚类算法优化[J]. 计算机工程与设计, 2016,37(11):2979-2984.
|
|
Dai Jiao, Zhang Minxing, Zheng Jinlong , et al. Optimization of fast clustering algorithm based on density peaks[J]. Computer Engineering and Design, 2016,37(11):2979-2984.
|
| [13] |
张天宇, 谌志群, 黄孝喜 , 等. 基于改进CFSFDP算法的电信投诉文本聚类方法[J]. 电子科技, 2017,30(10):93-96.
|
|
Zhang Tianyu, Chen Zhiqun, Huang Xiaoxi , et al. Clustering method for telecom complaints text based on improved CFSFDP algorithm[J]. Electronic Science and Technology, 2017,30(10):93-96.
|
| [14] |
张文开 . 基于密度的层次聚类算法研究[D]. 合肥:中国科学技术大学, 2015.
|
|
Zhang Wenkai . Research on density-based hierarchical clustering algorithm[D]. Hefei:University of Science and Technology of China, 2015.
|
| [15] |
马春来, 单洪, 马涛 , 等. 一种基于CFSFDP改进算法的重要地点识别方法研究[J]. 计算机应用研究, 2017, 34(1):136-140.
|
|
Ma Chunlai, Shan Hong, Ma Tao , et al. Research on important places identification method based on improved CFSFDP algorithm[J]. Application Research of Computers, 2017,34(1):136-140.
|
| [16] |
Rong C . Using mahout for clustering wikipedia's latest articles:a comparison between K-means and fuzzy C-means in the cloud[C]. Athens:IEEE Third International Conference on Cloud Computing Technology and Science, IEEE Computer Society, 2011.
|