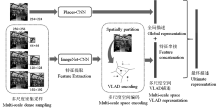
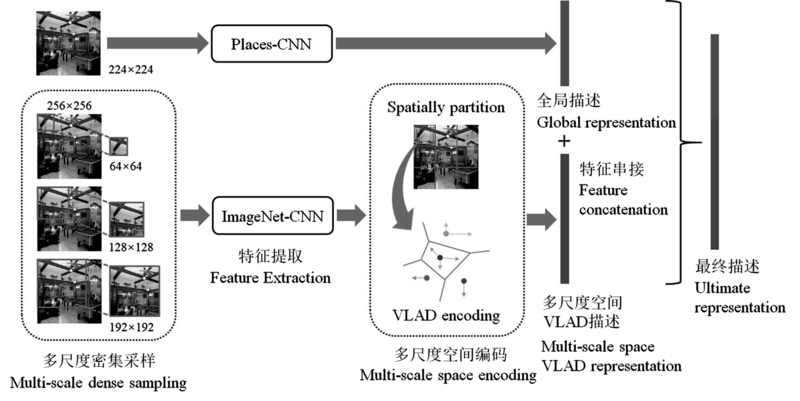
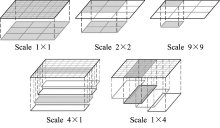
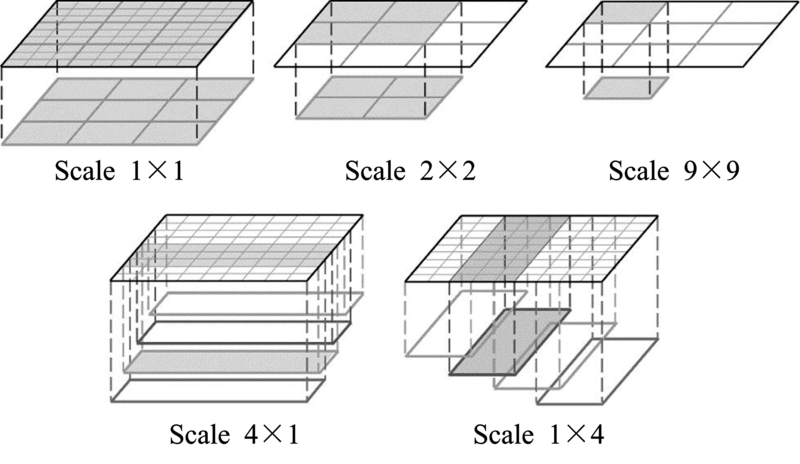
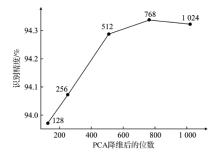
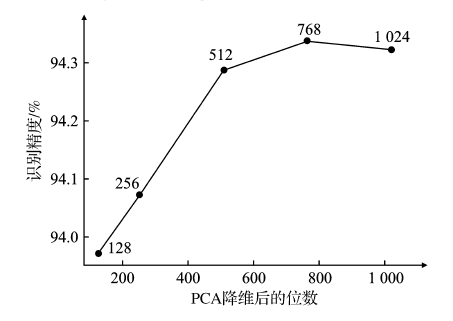
| [1] |
Lowe D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004,60(2):91-110.
|
| [2] |
Dalal N, Triggs B. Histograms of origented gradients for human detection[C]. San Diego:Computer Vision and Pattern Recognition, 2005.
|
| [3] |
Bay H, Ess A, Tuytelaars T, et al. Speeded-Up Robust Features (SURF)[J]. Computer Vision and Image Understanding, 2008,110(3):346-359.
|
| [4] |
Sivic J, Zisserman A. Video Google:A text retrieval approach to object matching in videos[C]. Nice:International Conference on Computer Vision, 2003.
|
| [5] |
Sánchez J, Perronnin F, Mensink T, et al. Image classification with the fisher vector: theory and practice[J]. International Journal of Computer Vision, 2013,105(3):222-245.
|
| [6] |
Jégou H, Douze M, Schmid C, et al. Aggregating local descriptors into a compact image representation[C]. San Francisco:Computer Vision and Pattern Recognition, 2010.
|
| [7] |
Lazebnik S, Schmid C, Ponce J. Beyond bags of features: spatial pyramid matching for recognizing natural scene categories[C]. New York:Computer Vision and Pattern Recognition, 2006.
|
| [8] |
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[C]. San Diego:International Conference on Learning Representations, 2015.
|
| [9] |
Szegedy C, Liu Wei, Jia Yangqing, et al. Going deeper with convolutions[C]. Boston:Computer Vision and Pattern Recognition, 2015.
|
| [10] |
He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]. Las Vegas:Computer Vision and Pattern Recognition, 2016.
|
| [11] |
Deng J, Dong W, Socher R, et al. ImageNet: A large-scale hierarchical image database[C]. Miami:Computer Vision and Pattern Recognition, 2009.
|
| [12] |
ZhouBolei, Lapedriza A, Khosla A, et al. Places:a 10 million image database for scene recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017,40(6):1452-1464.
pmid: 28692961
|
| [13] |
Arandjelovic R, Zisserman A. All about VLAD[C]. Portland:Computer Vision and Pattern Recognition, 2013.
|
| [14] |
Jégou H, Douze M, Schmid C. On the burstiness of visual elements[C]. Miami:Computer Vision and Pattern Recognition, 2009.
|
| [15] |
Jégou H, Perronnin F, Douze M, et al. Aggregating local image descriptors into compact codes[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012,34(9):1704-1716.
pmid: 22156101
|
| [16] |
Xie L, Li F F, Liu L, et al. Improved spatial pyramid matching for scene recognition[J]. Pattern Recognition, 2018,82(3):118-129.
|
| [17] |
Li L J, Su H, Xing E P, et al. Object bank: A high-level image representation for scene classification & semantic feature sparsification[C]. Vancouver:Neural Informatino Processing Systems, 2010.
|
| [18] |
谢林, 李菲菲, 陈虬. 基于稀疏自动编码机的场景识别算法[J]. 电子科技, 2019,32(1):38-41.
|
|
Xie Lin, Li Feifei, Chen Qiu. Scene recognition algorithm based on sparse autoencoder[J]. Electronic Science and Technology, 2019,32(1):38-41.
|
| [19] |
Wu J X, Rehg J M. CENTRIST:a visual descriptor for scene categorization[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2010,33(8):1489-501.
|
| [20] |
Lin D, Lu C W, Liao R J, et al. Learning important spatial pooling regions for scene classification[C]. Columbus:Conference on Computer Vision and Pattern Recognition,IEEE Computer Society,2014.[21] Xie Lin,Lee Feifei,Yan Yan,et al.Sparse decomposition of convolutional features for scene recognition[C].Beijing: International Conference on Computational Intelligence and Applications, 2017.
|
| [22] |
Weng Chaoqun, Wang Hongxing, Yuan Jundong, et al. Discovering class-specific spatial layouts for scene recognition[J]. IEEE Signal Processing Letters, 2017,24(8):1143-1147.
|
| [23] |
KhanS, Hayat M, Bennamoun M, et al. A discriminative representation of convolutional features for indoor scene recognition[J]. IEEE Transactions on Image Processing, 2016,25(7):3372-3383.
pmid: 28113718
|