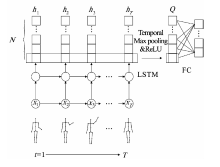
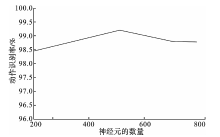
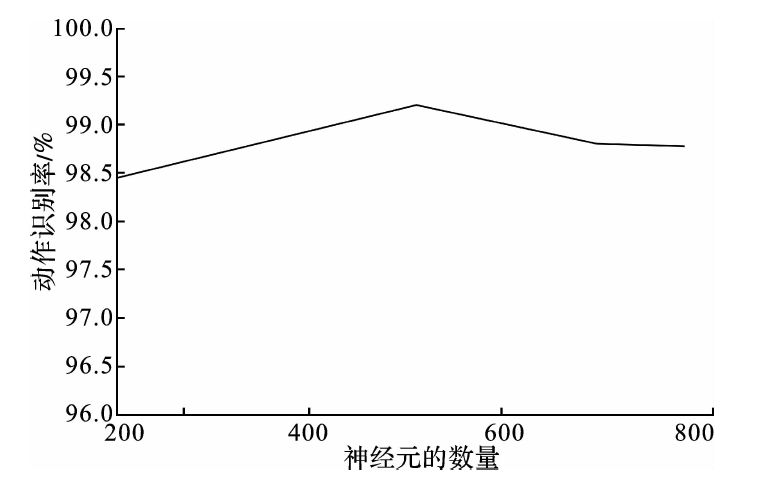
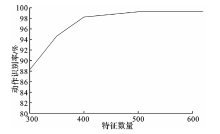
| [1] |
Shotton J, Sharp T, Kipman A, et al. Real-time human pose recognition in parts from single depth images[J]. Communications of the ACM, 2013,56(1):116-124.
|
| [2] |
Chen C, Zhuang Y, Nie F, et al. Learning a 3D human pose distance metric from geometric pose descriptor[J]. IEEE Transactions on Visualization & Computer Graphics, 2011,17(11):1676-1689.
doi: 10.1109/TVCG.2010.272
pmid: 21173458
|
| [3] |
Vemulapalli R, Arrate F, Chellappa R. Human action recognition by representing 3D skeletons as points in a Lie group[C]. Columbus:IEEE Conference on Computer Vision and Pattern Recognition, 2014.
|
| [4] |
Shao Z, Li Y. Integral invariants for space motion trajectory matching and recognition[J]. Pattern Recognit, 2015,48(8):2418-2432.
|
| [5] |
陈胜娣, 魏维, 何冰倩, 等. 基于改进的深度卷积神经网络的人体动作识别方法[J]. 计算机应用研究, 2019,36(4):1-7.
|
|
Chen Shengdi, Wei Wei, He Bingqian, et al. Action recognition base on improved deep convolutional neural network[J]. Application Research of Computers, 2019,36(4):1-7.
|
| [6] |
梁玉强, 陈劲杰, 叶其含. 基于AdaBoost和BP网络的机器人动作理解[J]. 电子科技, 2017,30(8):63-66.
|
|
Liang Yuqiang, Cheng Jinjie, Ye Qihan. Robot motion understanding based on AdaBoost and BP networks[J]. Electronic Science and Technology, 2017,30(8):63-66.
|
| [7] |
Veeriah V, Zhuang N, Qi G J. Differential recurrent neural networks for action recognition[C]. Santiago:IEEE International Conference on Computer Vision, 2015.
|
| [8] |
Liu J, Shahroudy A, Xu D, et al. Spatio-temporal LSTM with trust gates for 3D human action recognition[C]. Amsterdam:The Fourteenth European Conference on Computer Vision (ECCV), 2016.
|
| [9] |
Song S, Lan C, Xing J, et al. An end-to-end spatio-temporal attention model for human action recognition from skeleton data[C]. San Francisco:The Thirty-first AAAI Conference on Artificial Intelligence, 2017.
|
| [10] |
Zhang S, Yang Y, Xiao J, et al. Fusing geometric features for skeleton-based action recognition using multilayer LSTM networks[J]. IEEE Transactions on Multimedia, 2018,20(9):2330-2343.
|
| [11] |
Liu J, Wang G, Hu P, et al. Global context-aware attention LSTM networks for 3D action recognition[C]. Hawaii: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
|
| [12] |
Bengio Y, Simard P, Frasconi P. Learning long-term dependencies with gradient descent is difficult[J]. IEEE Transactions on Neural Networks, 1994,5(2):157-166.
doi: 10.1109/72.279181
pmid: 18267787
|
| [13] |
Yun K, Honorio J, Chattopadhyay D, et al. Two-person interaction detection using body-pose features and multiple instance learning[C]. Rhode Island:IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, 2012.
|
| [14] |
Xia L, Chen C C, Aggarwal J K. View invariant human action recognition using histograms of 3D joints[C]. Rhode Island:IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, 2012.
|
| [15] |
Ji Y, Ye G, Cheng H. Interactive body part contrast mining for human interaction recognition[C]. Chengdu:IEEE International Conference on Multimedia and Expo Workshops, 2014.
|
| [16] |
Li W, Wen L, Chuah M C, et al. Category-blind human action recognition: a practical recognition system[C]. Santiago:IEEE International Conference on Computer Vision, 2015.
|
| [17] |
Du Y, Wang W, Wang L. Hierarchical recurrent neural network for skeleton based action recognition[C]. Boston: IEEE Conference on Computer Vision and Pattern Recognition, 2015.
|
| [18] |
Zhu W, Lan C, Xing J, et al. Cooccurrence feature learning for skeleton based action recognition using regularized deep LSTM networks[C]. Phoenix:The Thirtieth AAAI Conference on Artificial Intelligence, 2016.
|
| [19] |
Zhu Y, Chen W, Guo G. Fusing spatiotemporal features and joints for 3D action recognition[C]. Portland:IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2013.
|
| [20] |
Anirudh R, Turaga P, Su J, et al. Elastic functional coding of human actions: from vector-fields to latent variables[C]. Boston:IEEE Conference on Computer Vision and Pattern Recognition, 2015.
|