Electronic Science and Technology ›› 2023, Vol. 36 ›› Issue (10): 39-55.doi: 10.16180/j.cnki.issn1007-7820.2023.10.006
Previous Articles Next Articles
LI Yueyang,TONG Guoxiang,ZHAO Yingzhi,LUO Qi
Received:2022-04-22
Online:2023-10-15
Published:2023-10-20
Supported by:CLC Number:
LI Yueyang,TONG Guoxiang,ZHAO Yingzhi,LUO Qi. A Survey of Text-to-Image Synthesis Based on Generative Adversarial Network[J].Electronic Science and Technology, 2023, 36(10): 39-55.
Table 1.
Summary of GANs based on attention enhancement"
| 模型 | 特点 | 局限性 |
|---|---|---|
| AttnGAN[ | 捕获细粒度的单词级别和子区域级别的信息 | 在捕捉全局相干结构方面还不够完善,从像 素级别来理解高层次语义比较困难 |
| Dualattn-GAN[ | 关注相关词和不同视觉区域的相关特征 | 缺少对图像的多样性约束 |
| ResFPA-GAN[ | 通过嵌入特征金字塔结构引入多尺度特征融合 | 不适用于复杂场景下的图像生成 |
| MirrorGAN[ | 提出了用于级联图像生成的全局-局部协作注意模块 | 模型中的模块没有通过端到端的联合优化 |
| DM-GAN[ | 设计存储写入门结构选择文本中的重要内容 | 过于依赖原始图像中多个对象的布局 |
| Obj-GAN[ | 提出对象驱动的注意力图像生成器 | 生成图像的分辨率有待改善 |
| SE-GAN[ | 引入语义一致性模块和注意力模块 | 缺少对文本对象的位置和形状添加额外约束 |
| ControlGAN[ | 研究词和图像子区域的关系来区分不同视觉属性 | 生成图像可能有高度随机性 |
| RpA-GAN[ | 在辅助边界框和词组之间添加额外的注意力机制 | 无法从不同语句中生成相似图像 |
| RiFeGAN[ | 使用自注意机制有效地提取文本特征 | 模型结构相对简单 |
| TVBi-GAN[ | 提出了基于语义增强的注意模块和批量规范化模块 | 模型的泛化能力有待改善 |
| KT-GAN[ | 引入交替注意转移机制和语义蒸馏机制 | SDM任务和T2I任务没有进行端到端的联合优化 |
| AGAN-CL[ | 应用上下文损失和循环一致损失来弥补多模态差异 | 不适用于复杂场景下的图像生成 |
| DT-GAN[ | 引入通道感知和像素感知的注意模块 | 视觉质量的改善伴随着生成图像的变化而减少 |
| SegAttnGAN[ | 利用附加的分割信息进行文本到图像的合成任务 | 在推理阶段需要输入语句片段 |
| XMC-GAN[ | 使用注意力自调制生成器,强制执行强文本-图像对应 | 缺少对图像的多样性约束 |
| SAM-GAN[ | 通过自注意力机制,生成融合语句和单词的视觉语义向量 | 更复杂场景的生成图像不够清晰 |
| DriverGAN[ | 引入条件自适应归一化,使语句能够灵活地操纵形状和纹理 | 缺少对生成图像的主观性评估 |
Table 2.
Summary of GANs based on multi-stage enhancement"
| 模型 | 特点 | 局限性 |
|---|---|---|
| StackGAN[ | 首次提出堆叠式生成对抗网络 | 没有用端到端的训练方法,且丢失了 细粒度的单词级别的信息 |
| StackGAN++[ | 将多个生成器和鉴别器以树状结构排列 | 没有用端到端的训练方法 |
| HDGAN[ | 提出可扩展的单流生成器结构 | 生成图像可能有高度随机性 |
| ChatPainter[ | 添加对话问答模式来描述场景 | 容易造成模式奔溃,且模型训练不稳定 |
| FusedGAN[ | 以非常高的保真度对各种图像进行可控采样 | 不适用于复杂场景下的图像生成 |
| LeicaGAN[ | 将文本生成图像分为先验学习阶段、想象阶段以及创建阶段 | 生成图像可能有高度随机性 |
| textStyleGAN[ | 提出了一个用于文本到图像生成和操作的单一管道 | 模型的泛化能力有待改善 |
| MTC-GAN[ | 基于全局约束的方法使生成图像多样化,改善模式崩溃问题 | 忽略了文本局部特征 |
Table 3.
Summary of GANs based on scene layout enhancement"
| 模型 | 特点 | 局限性 |
|---|---|---|
| SceneGraph[ | 从场景图生成图像,显式地推理对象及其关系 | 生成图像的质量有待改善 |
| InferringGAN[ | 从粗到精的方式逐步构建语义布局 | 生成图像中对象的位置预测不够精确 |
| Text2Scene[ | 关注文本的子区域和场景状态,随时间步生成对象及其属性 | 只适用于机器的描述和绘画 |
| IMEAA-GAN[ | 使用边框回归网络计算每个实例的类别和位置的布局 | 更复杂场景的生成图像不够清晰 |
| OP-GAN[ | 显式地为图像中的单个对象建模 | 缺乏对罕见物体的识别能力 |
| CSS-GAN[ | 利用稀疏语义映射来控制对象的形状和类别以及 文本描述或属性来控制局部和全局样式 | 无法区分同一类别的实例,也不能获取位置信息 |
| EndtoEnd[ | 将文本语义和空间信息融合到合成模块中, 与多尺度语义布局联合微调 | |
| C4Synth[ | 联合多文本生成图像 | 忽略了文本局部特征 |
| SD-GAN[ | 隐含地理解语义,实现高阶语义一致性和低阶语义多样性 | 忽略了文本局部特征 |
Table 4.
Summary of GANs based on universality enhancement"
| 模型 | 特点 | 局限性 |
|---|---|---|
| Bridge-GAN[ | 设计三元互信息目标:优化过渡空间, 增强视觉真实性和内容一致性 | 缺乏对罕见物体的识别能力 |
| HfGAN[ | 充分利用来自网络的层次信息,并通过自适应 融合多层次的特征直接生成精细图像 | 缺少对图像的多样性约束 |
| CPGAN[ | 在文本编码期间探索词汇表中每个单词与其跨 相关图像的各种视觉上下文语义的对应关系 | 对跨度范围较大的对象效果有待改善 |
| NNT-GAN[ | 在多模态间进行转换而不需要微调 | 生成图像的泛化能力有待改善 |
| DF-GAN[ | 提出了匹配感知的梯度惩罚和单向输出的目标感知识别器 | 生成图像的质量有待改善 |
| MA-GAN[ | 提出了单句生成和多句判别模块 | 忽略了视觉信息和语义信息之间的不平衡 |
| ICSD-GAN[ | 采用极间跨样本相似性蒸馏模块 | 模型评估不够全面 |
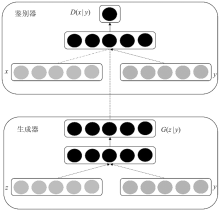
Figure 1.
Architecture of CGAN"
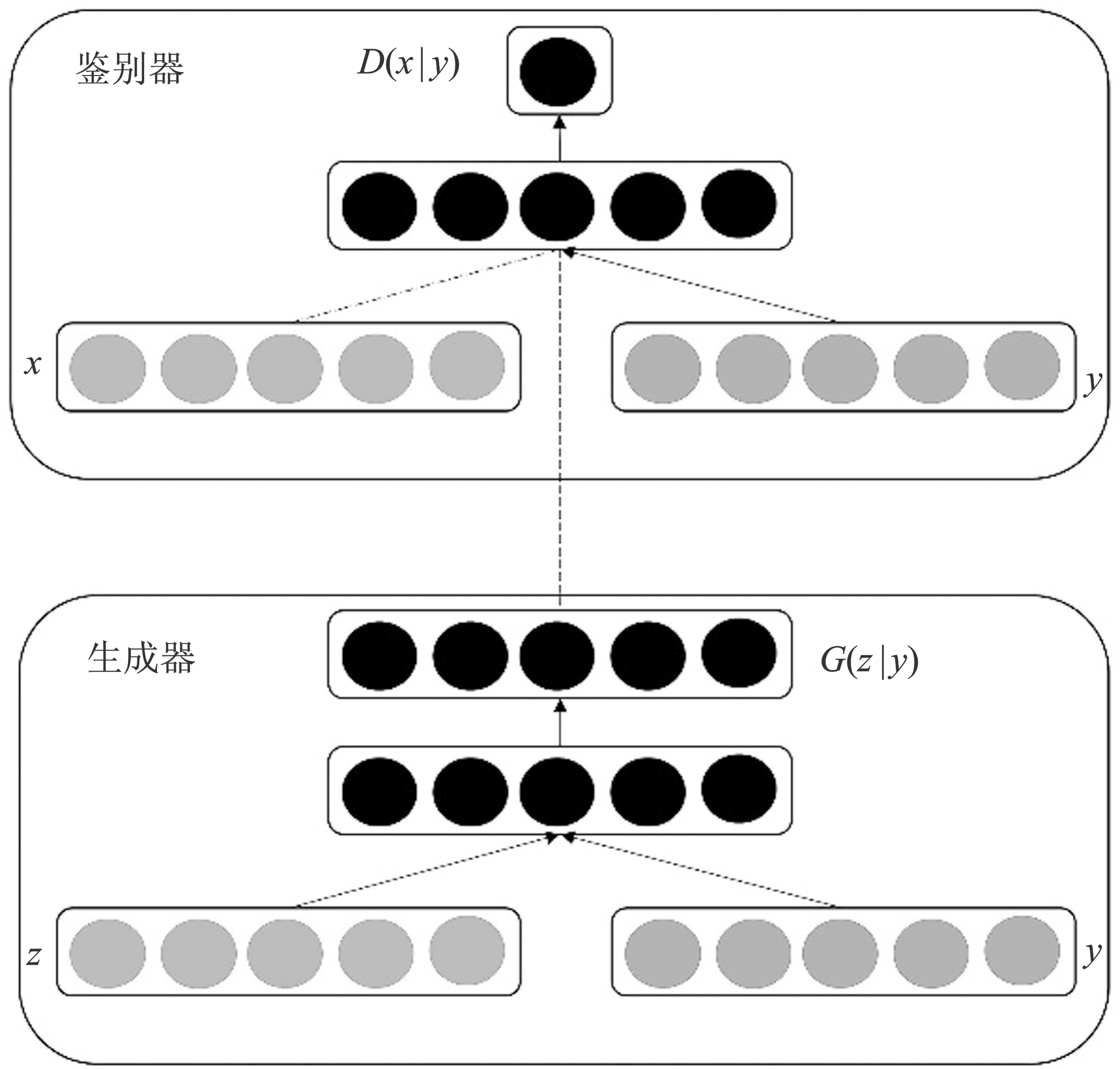
Figure 2.
Architecture of DCGAN"
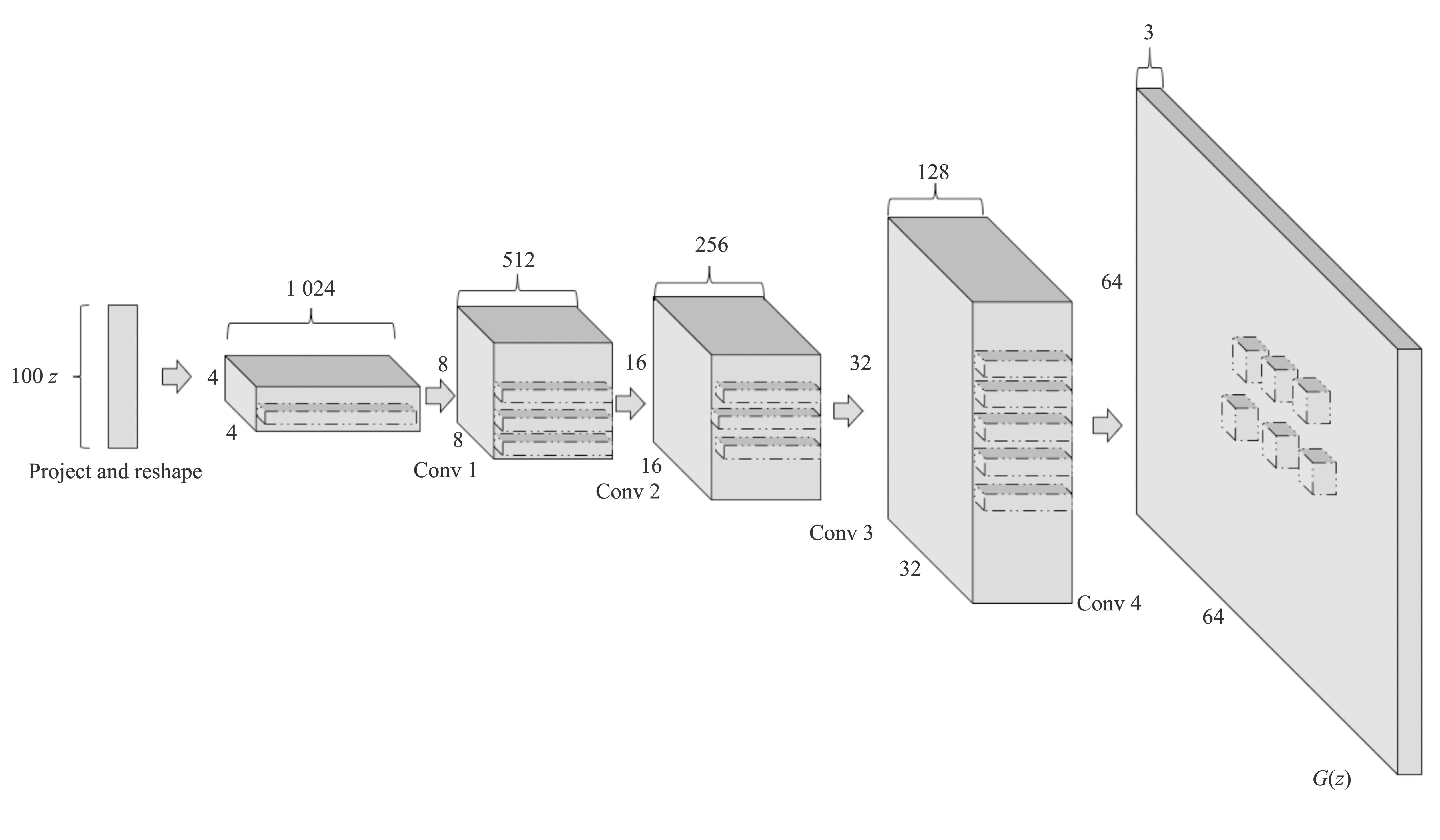
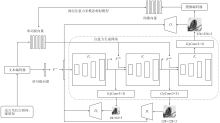
Figure 3.
Architecture of AttnGAN"
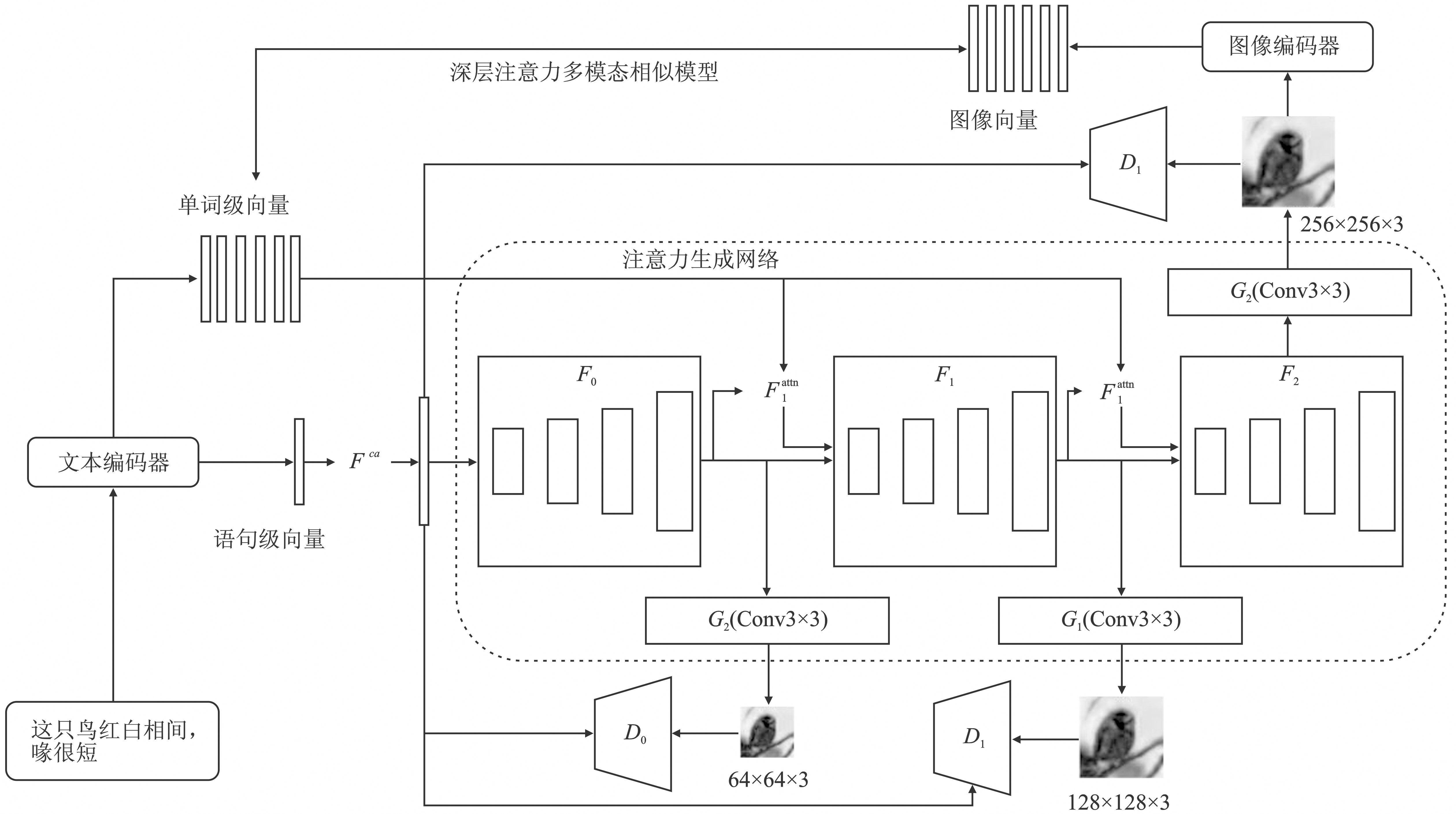
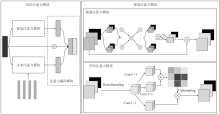
Figure 4.
Architecture of DualAttn-GAN"
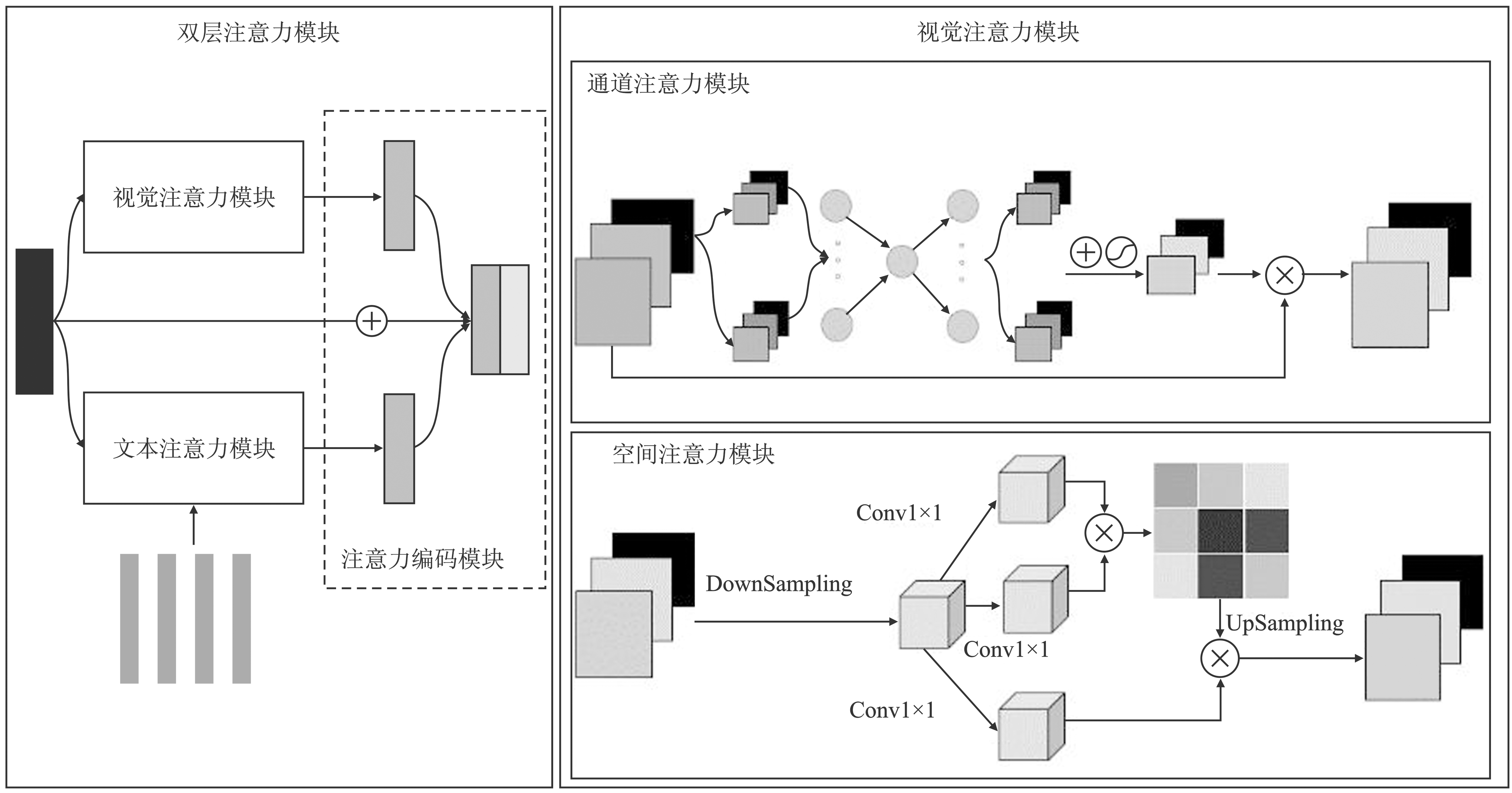
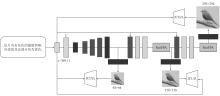
Figure 5.
Architecture of FesFPA-GAN"

Table 5.
Comparison of IS of typical attention enhancement methods"
| 模型 | CUB | Oxford | COCO | 数据来源 |
|---|---|---|---|---|
| AttnGAN | 4.39 | 3.79 | 26.36 | 文献[ |
| Dualattn-GAN | 4.59 | 4.06 | 28.16 | 文献[ |
| ResFPA-GAN | 4.27 | 3.65 | - | 文献[ |
| MirrorGAN | 4.61 | - | 26.88 | 文献[ |
| DM-GAN | 4.82 | 3.96 | 31.06 | 文献[ |
| Obj-GAN | 4.77 | - | 30.11 | 文献[ |
| SE-GAN | 4.67 | - | - | 文献[ |
| ControlGAN | 4.58 | - | 24.06 | 文献[ |
| RpA-GAN | - | - | 26.92 | 文献[ |
| RiFeGAN | 5.23 | 4.53 | - | 文献[ |
| TVBi-GAN | 5.03 | - | 31.01 | 文献[ |
| KT-GAN | 4.85 | 3.72 | 31.67 | 文献[ |
| AGAN-CL | 4.97 | 4.72 | 29.87 | 文献[ |
| DT-GAN | 4.88 | 3.77 | - | 文献[ |
| SegAttnGAN | 4.82 | 3.52 | - | 文献[ |
| XMC-GAN | 4.88 | - | 30.45 | 文献[ |
| SAM-GAN | 4.61 | 4.13 | 27.31 | 文献[ |
| DriverGAN | 4.98 | 3.99 | - | 文献[ |
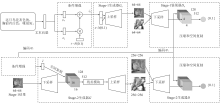
Figure 6.
Architecture of AttnGAN"
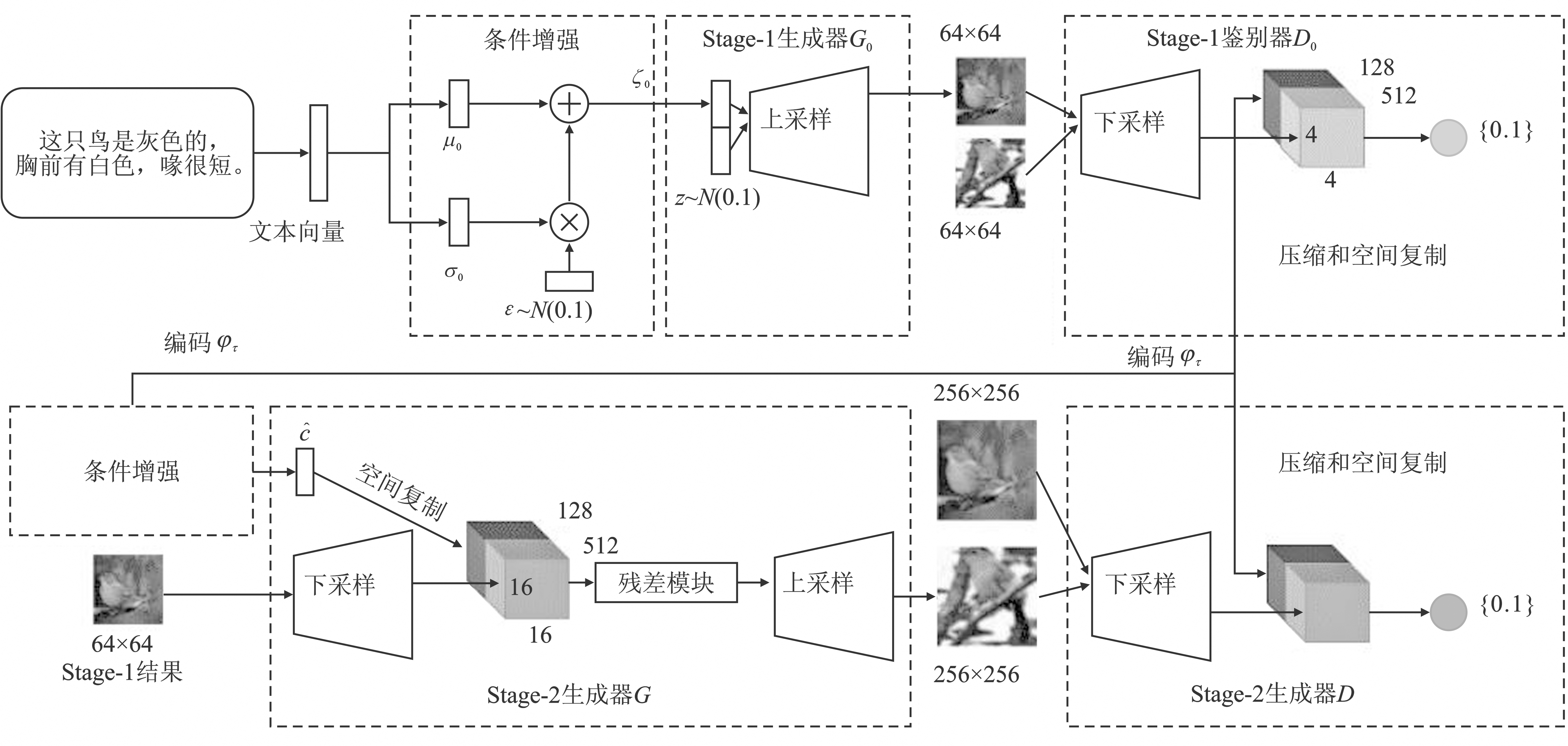
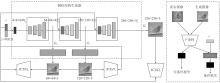
Figure 7.
Architecture of StackGAN++"

Table 6.
Comparison of IS of typical multi-stage enhancement methods"
| 模型 | CUB | Oxford | COCO | 数据来源 |
|---|---|---|---|---|
| StackGAN | 3.74 | 3.21 | 8.60 | 文献[ |
| StackGAN++ | 4.09 | 3.27 | 8.40 | 文献[ |
| HDGAN | 4.20 | 3.45 | 31.06 | 文献[ |
| ChatPainter | - | - | 9.74 | 文献[ |
| FusedGAN | 3.92 | - | - | 文献[ |
| LeicaGAN | 4.62 | 3.92 | - | 文献[ |
| textStyleGAN | 4.78 | - | 33.00 | 文献[ |
| MTC-GAN | 4.16 | 3.53 | 28.43 | 文献[ |
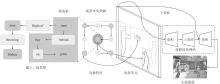
Figure 8.
Architecture of Scene Graph"
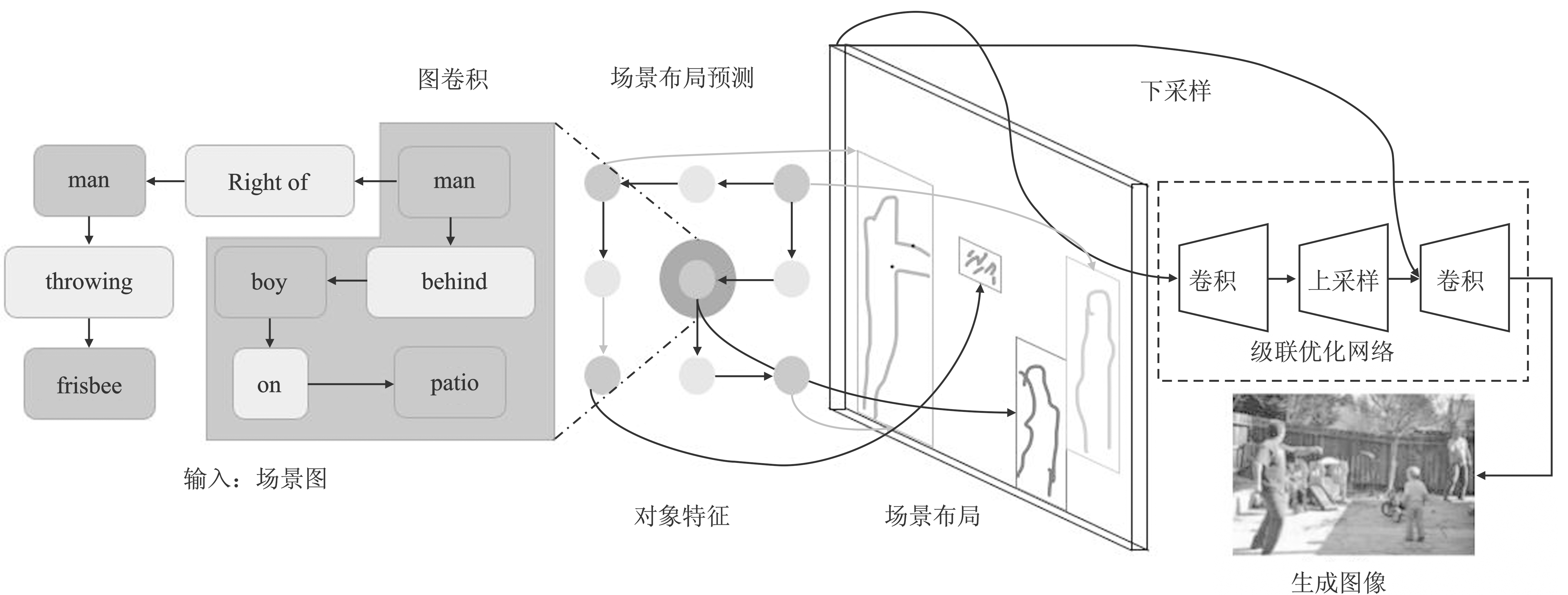
Figure 9.
Architecture of InferringGAN"
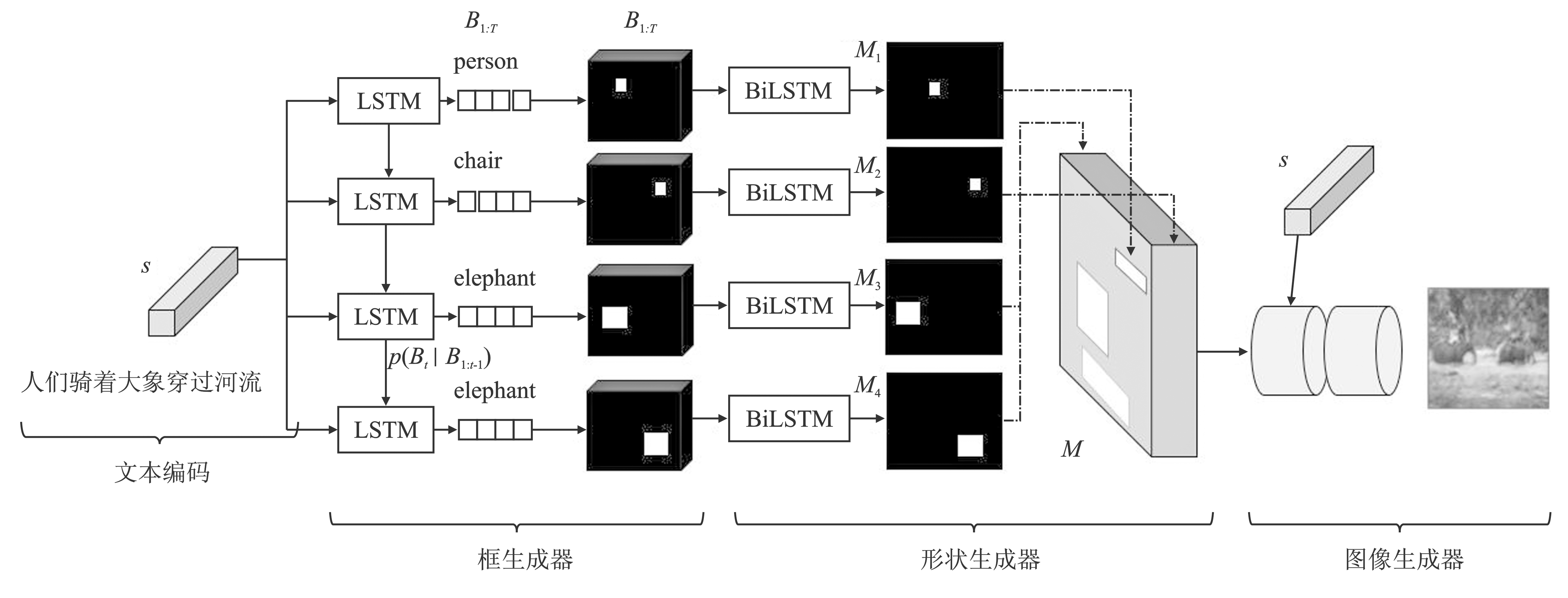
Table 7.
Comparison of IS of typical scene layout enhancement methods"
| 模型 | CUB | Oxford | COCO | 数据来源 |
|---|---|---|---|---|
| SceneGraph | 3.54 | 3.77 | 7.40 | 文献[ |
| InferringGAN | 3.61 | - | 11.46 | 文献[ |
| Text2Scene | - | - | 24.77 | 文献[ |
| IMEAA-GAN | 4.75 | - | 30.49 | 文献[ |
| OP-GAN | - | - | 27.88 | 文献[ |
| CSS-GAN | - | - | 19.65 | 文献[ |
| EndtoEnd | 5.06 | - | 29.03 | 文献[ |
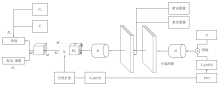
Figure 10.
Architecture of TAC-GAN"
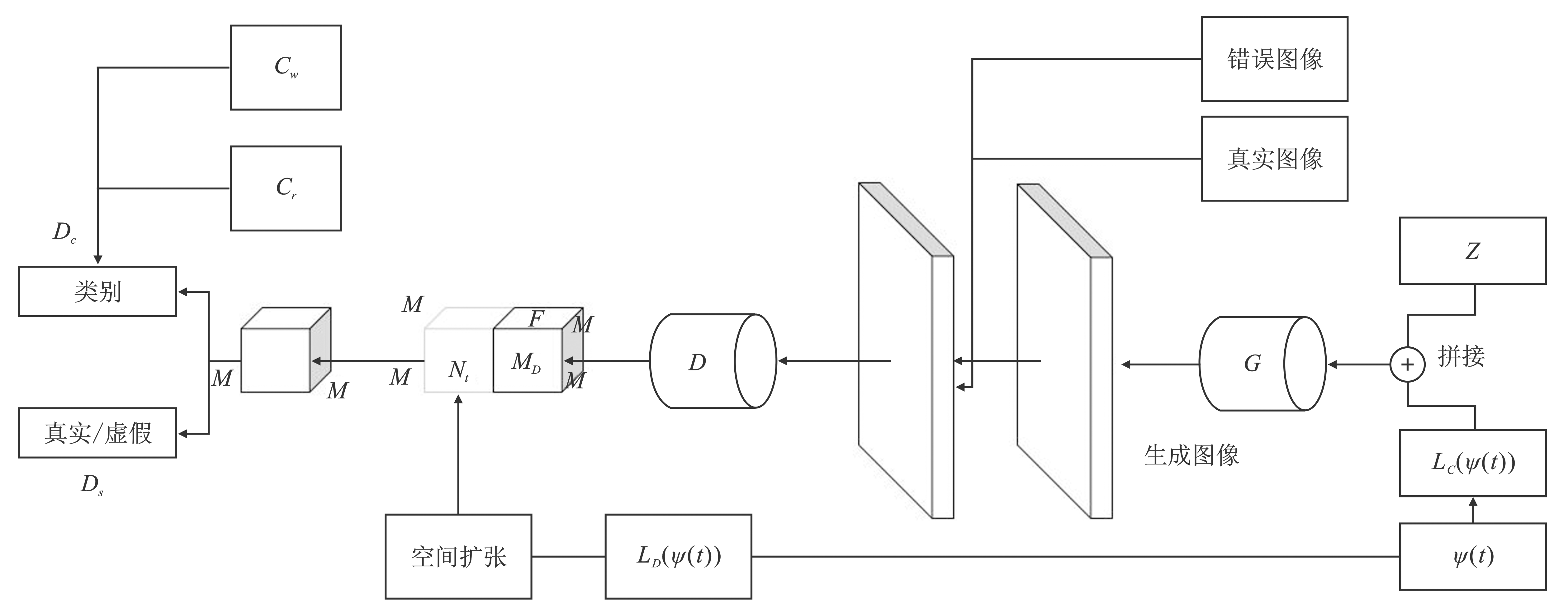
Figure 11.
Architecture of MA-GAN"
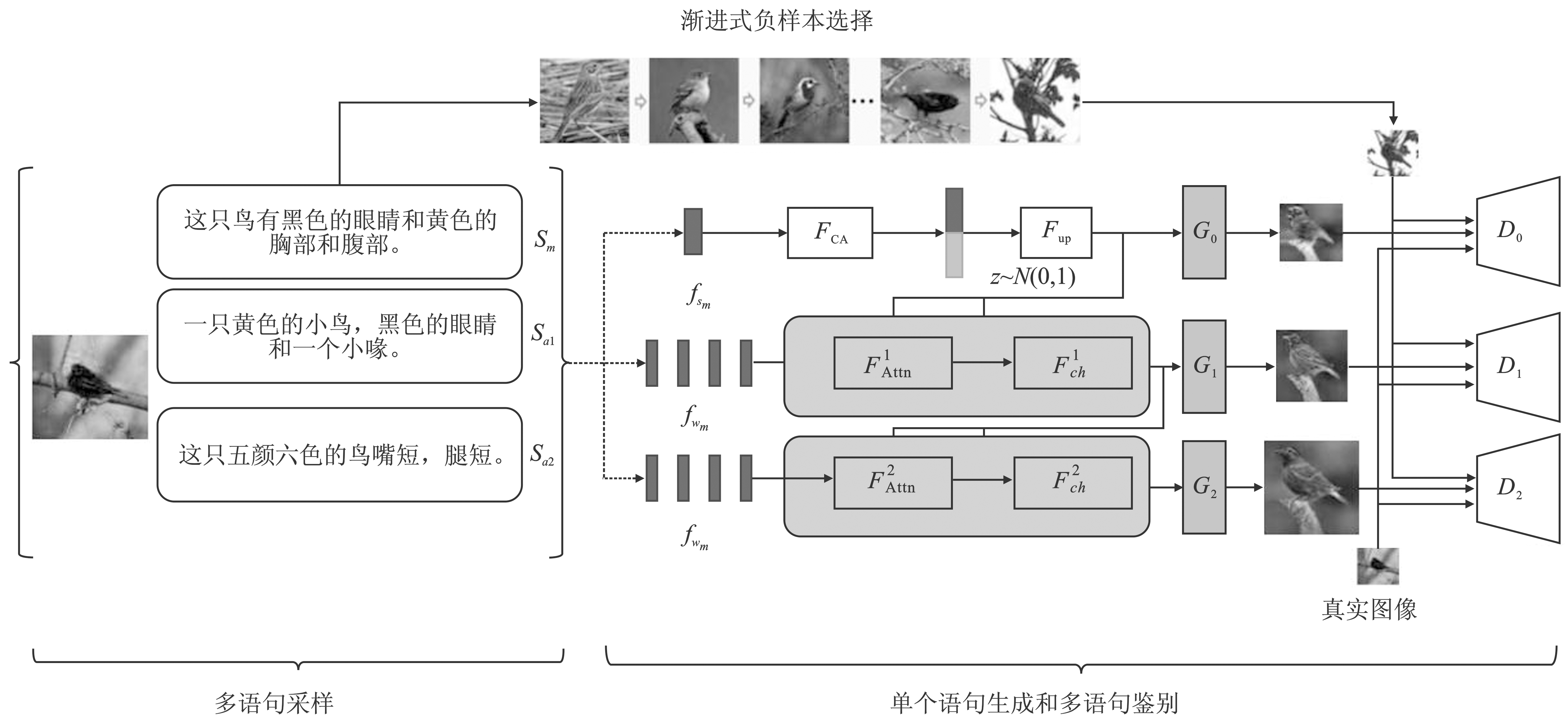
Table 8.
Comparison of IS of typical universality enhancement methods"
| 模型 | CUB | Oxford | COCO | 数据来源 |
|---|---|---|---|---|
| C4Synth | 4.07 | 3.52 | - | 文献[ |
| CVAEGAN | 4.97 | 4.21 | - | 文献[ |
| SD-GAN | 4.67 | - | 35.69 | 文献[ |
| Bridge-GAN | 4.74 | - | 16.40 | 文献[ |
| HfGAN | 4.48 | 3.57 | 27.53 | 文献[ |
| CPGAN | - | - | 52.73 | 文献[ |
| NNT-GAN | - | - | 34.7 | 文献[ |
| DF-GAN | 5.10 | - | - | 文献[ |
| MA-GAN | 4.76 | 4.09 | - | 文献[ |
Table 9.
Several typical semantic consistency evaluation metric"
| 指标 | 特点 |
|---|---|
| LPIPS metric[ | 相同字幕的两组生成图像的多样性得分 |
| VS similarity[ | 训练一个视觉语义嵌入模型,来测量合成图像和 输入文本之间的距离 |
| HE[ | 若干名用户对生成图像做客观性评估 |
| RP[ | 提取图像和文本特征的检索结果进行排序 |
| BLEU[ | 基于精确度的相似性度量 |
| METEOR[ | 测量单精度的加权调和平均数及单字召回率 |
| CIDEr[ | 通过度量待评测语句与其他大部分人工描述语句 之间的相似性来评价文本图像相似性 |
| SOA[ | 基于对象检测器来评估文本描述中的单个对象 |
| [1] | Yeh R A, Chen C, Yian Lim T, et al. Semantic image i-npainting with deep generative models[C]. Honolulu: IEEE Conference on Computer Vision and Pattern Recognition, 2017:5485-5493. |
| [2] | Isola P, Zhu J Y, Zhou T, et al. Image-to-image translation with conditional adversarial networks[C]. Honolulu: I-EEE Conference on Computer Vision and Pattern Recognition, 2017:1125-1134. |
| [3] | Bodla N, Hua G, Chellappa R. Semi-supervised Fused G-AN for conditional image generation[C]. Munich: The European Conference on Computer Vision, 2018:669-683. |
| [4] | Ledig C, Theis L, Huszár F, et al. Photo-realistic single image super-resolution using a generative adversarial network[C]. Honolulu: IEEE Conference on Computer Vision and Pattern Recognition, 2017:4681-4690. |
| [5] |
Frid Adar M, Diamant I, Klang E, et al. GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification[J]. Neurocomputing, 2018, 321(10):321-331.
doi: 10.1016/j.neucom.2018.09.013 |
| [6] | Bengio Y, Courville A, Vincent P. Representation learning:A review and new perspectives[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2013, 35(8):1798-1828. |
| [7] | Zhu X, Goldberg A B, Eldawy M, et al. A text-to-picture synthesis system for augmenting communication[C]. Vancouver: Proceedings of the Sixth International Conference on Learning Representations, 2018:1710-1735. |
| [8] | Kingma D P, Welling M. Auto-encoding variational Bayes[J]. IEEE Computer Society, 2021, 43(12):4217-4228. |
| [9] | Gregor K, Danihelka I, Graves A, et al. Draw:A recurrentneural network for image generation[C]. Lille: Internati-onal Conference on Machine Learning, 2015:1462-1471. |
| [10] | Goodfellow I J, Pouget Abadie J, Mirza M, et al. Genera-tive adversarial networks[J]. Advances in Neural Info-rmation Processing Systems, 2014(3):2672-2680. |
| [11] | Reed S, Akata Z, Yan X, et al. Generative adversarial text to image synthesis[C]. New York: International Conference on Machine Learning, 2016:1060-1069. |
| [12] | Reed S E, Akata Z, Mohan S, et al. Learning what and where to draw[J]. Advances in Neural Information Processing Systems, 2016, 30(8):217-225. |
| [13] | Xu T, Zhang P, Huang Q, et al. Attngan:Fine-grained textto image generation with attentional generative adversarial networks[C]. Salt Lake City: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018:1316-1324. |
| [14] | Dash A, Gamboa J C B, Ahmed S, et al. Tac-gan-text conditioned auxiliary classifier generative adversarial network[J]. Journal of Image and Graphics, 2021, 26(3):594-604. |
| [15] | Zhang H, Xu T, Li H, et al. Stackgan:Text to photo-reali-stic image synthesis with stacked generative adversarial networks[C]. Venice: Proceedings of the IEEE International Conference on Computer Vision, 2017:5907-5915. |
| [16] | Johnson J, Gupta A, Li F F. Image generation from scene graphs[C]. Salt Lake City: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018:1219-1228. |
| [17] | Qiao T, Zhang J, Xu D, et al. Mirrorgan:Learning text-to-image generation by redescription[C]. Long Beach: IEE-E/CVF Conference on Computer Vision and Pattern Recognition, 2019:1505-1514. |
| [18] |
Yang Y, Wang L, Xie D, et al. Multi-sentence auxiliary adversarial networks for fine-grained text-to-image synthesis[J]. IEEE Transactions on Image Processing, 2021, 30(2):2798-2809.
doi: 10.1109/TIP.83 |
| [19] |
Wu X, Xu K, Hall P. A survey of image synthesis and editing with generative adversarial networks[J]. Tsinghua Science and Technology, 2017, 22(6):660-674.
doi: 10.23919/TST.2017.8195348 |
| [20] | Huang H, Yu P S, Wang C. An introduction to image synthesis with generative adversarial nets[J]. Journal of Image and Graphics, 2021, 26(3):670-689. |
| [21] | Agnese J, Herrera J, Tao H, et al. A survey and taxonomy of adversarial neural networks for text-to-image synthesis[J]. Wiley Interdisciplinary Reviews:Data Mining and Knowledge Discovery, 2020, 10(4):1345. |
| [22] | Zhou R, Jiang C, Xu Q. A survey on generative adversarial network-based text-to-image synthesis[J]. Neuroco-mputing, 2021, 45(1):316-336. |
| [23] | Frolov S, Hinz T, Raue F, et al. Adversarial text-to-imagesynthesis:A review[J]. Neural Networks, 2021, 14(4):187-209. |
| [24] | Cai Y, Wang X, Yu Z, et al. Dualattn-GAN:Text to imag-e synthesis with dual attentional generative adversarial network[J]. IEEE Access, 2019(7):183706-183716. |
| [25] | Sun J, Zhou Y, Zhang B. ResFPA-GAN:Text-to-image synthesis with generative adversarial network based on residual block feature pyramid attention[C]. Beijing: IEEE International Conference on Advanced Robotics and its Social Impacts, 2019:317-322. |
| [26] | Zhu M, Pan P, Chen W, et al. Dm-gan:Dynamic memory generative adversarial networks for text-to-image synt-hesis[C]. Long Beach: IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019:5802-5810. |
| [27] | Cheng J, Wu F, Tian Y, et al. RiFeGAN:Rich feature ge-neration for text-to-image synthesis from prior knowl-edge[C]. Seattle: IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020:10911-10920. |
| [28] |
Zhang M, Li C, Zhou Z. Text to image synthesis using multi-generator text conditioned generative adversarial networks[J]. Multimedia Tools and Applications, 2021, 80(5):7789-7803.
doi: 10.1007/s11042-020-09965-5 |
| [29] | Tan F, Feng S, Ordonez V. Text2scene:Generating comp-ositional scenes from textual descriptions[C]. Long Be-ach: IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019:6710-6719. |
| [30] | Zhang Z, Xie Y, Yang L. Photographic text-to-image sy-nthesis with a hierarchically-nested adversarial network[C]. Salt Lake City: IEEE Conference on Computer Vision and Pattern Recognition, 2018:6199-6208. |
| [31] | Wang M, Lang C, Liang L, et al. End-to-end text-to-image synthesis with spatial constrains[J]. ACM Transactions on Intelligent Systems and Technology, 2020, 11(4):1-19. |
| [32] | Sharma S, Suhubdy D, Michalski V, et al. Chatpainter:Im-proving text to image generation using dialogue[J]. Journal of Chinese Computer Systems, 2021, 42(1):201-207. |
| [33] | Radford A, Metz L, Chintala S. Unsupervised representa-tion learning with deep convolutional generative adversarial networks[J]. Journal of Chinese Computer Systems, 2021, 42(1):241-257. |
| [34] | Xu B, Wang N, Chen T, et al. Empirical evaluation of rectified activations in convolutional network[J]. Journal of Chinese Computer Systems, 2021, 42(1):958-969. |
| [35] |
Lecun Y, Bottou L. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11):2278-2324.
doi: 10.1109/5.726791 |
| [36] |
Zhang H, Xu T, Li H, et al. Stackgan++:Realistic image synthesis with stacked generative adversarial networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 41(8):1947-1962.
doi: 10.1109/TPAMI.34 |
| [37] | Tan H, Liu X, Li X, et al. Semantics-enhanced adversari-al nets for text-to-image synthesis[C]. Seoul: IEEE/CVF International Conference on Computer Vision, 2019:10501-10510. |
| [38] | Huang W, Da Xu R Y, Oppermann I. Realistic image generation using region-phrase attention[C]. Nagoya: Asian Conference on Machine Learning, 2019:284-299. |
| [39] | Wang Z, Quan Z, Wang Z J, et al. Text to image synthesis with bidirectional generative adversarial network[C]. London: IEEE International Conference on Multimedia and Expo, 2020:1-6. |
| [40] |
Tan H, Liu X, Liu M, et al. KT-GAN:Knowledge-transfer generative adversarial network for text-to-image synthesis[J]. IEEE Transactions on Image Processing, 2020, 30(7):1275-1290.
doi: 10.1109/TIP.83 |
| [41] | Wang M, Lang C, Liang L, et al. Attentive generative a-dversarial network to bridge multi-domain gap for image synthesis[C]. London: IEEE International Conference on Multimedia and Expo, 2020:1-6. |
| [42] | Zhang Z, Schomaker L. DTGAN:Dual attention generative adversarial networks for text-to-image generation[C]. Shenzhen: International Joint Conference on Neural Networks, 2021:1-8. |
| [43] | Gou Y, Wu Q, Li M, et al. SegAttnGAN:Text to image generation with segmentation attention[J]. Electronic Science and Technology, 2020, 33(4):28-34. |
| [44] | Zhang H, Koh J Y, Baldridge J, et al. Cross-modal contr-astive learning for text-to-image generation[C]. Online: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021:833-842. |
| [45] | Zhang Z, Schomaker L. DiverGAN:An efficient and effective single-stage framework for diverse text-to-image generation[J]. Neurocomputing, 2022, 47(3):182-198. |
| [46] | 林潮威, 李菲菲, 陈虬. 基于深度卷积特征的场景全局与局部表示方法[J]. 电子科技, 2022, 35(4):20-27. |
| Lin Chaowei, Li Feifei, Chen Qiu. Globaland local scene representation method based on deep convolutional features[J]. Electronic Science and Technology, 2022, 35(4):20-27. | |
| [47] | 伞红军, 王汪林, 陈久朋, 等. 面向室内动态场景的VSLAM[J]. 电子科技, 2022, 35(4):14-19. |
| San Hongjun, Wang Wanglin, Chen Jiupeng, et al. VSL-AM for indoor dynamic scenes[J]. Electronic Science and Technology, 2022, 35(4):14-19. | |
| [48] | Qiao T, Zhang J, Xu D, et al. Learn,imagine and create: Text-to-image generation from prior knowledge[J]. Advances in Neural Information Processing Systems, 2019(3):885-895. |
| [49] | Stap D, Bleeker M, Ibrahimi S, et al. Conditional image generation and manipulation for user-specified content[EB/OL].(2020-05-11) [2022-01-17] http://arxiv.org.abs/2005.04909. |
| [50] | Hong S, Yang D, Choi J, et al. Inferring semantic layout for hierarchical text-to-image synthesis[C]. Salt Lake City: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018:7986-7994. |
| [51] | Liang J, Pei W, Lu F. Cpgan:Content-parsing generative adversarial networks for text-to-image synthesis[C]. Online: European Conference on Computer Vision, 2020:491-508. |
| [52] | Joseph K J, Pal A, Rajanala S, et al. C4synth:Cross-caption cycle-consistent text-to-image synthesis[C]. Honolulu: IEEE Winter Conference on Applications of Computer Vision, 2019:358-366. |
| [53] | Zhang C, Peng Y. Stacking vae and gan for context-aware text-to-image generation[C]. Xi'an: IEEE the Fourth International Conference on Multimedia Big Data, 2018:1-5. |
| [54] | Yin G, Liu B, Sheng L, et al. Semantics disentangling for text-to-image generation[C]. Long Beach: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019:2327-2336. |
| [55] | Yuan M, Peng Y. Bridge-GAN:Interpretable representati-on learning for text-to-image synthesis[J]. IEEE Trans-actions on Circuits and Systems for Video Technology, 2019, 30(11):4258-4268. |
| [56] | Rombach R, Esser P, Ommer B. Network-to-network translation with conditional invertible neural networks[J]. Advances in Neural Information Processing Systems, 2020, 33(1):2784-2797. |
| [57] | Tao M, Tang H, Wu S, et al. Df-gan:Deep fusion generative adversarial networks for text-to-image synthesis[J]. Electronic Science and Technology, 2020, 33(4):156-174. |
| [58] | Salimans T, Goodfellow I, Zaremba W, et al. Improved t-echniques for training gans[J]. Advances in Neural Information Processing Systems, 2016, 29(4):10-13. |
| [59] | Szegedy C, Vanhoucke V, Ioffe S, et al. Rethinking the i-nception Architecture for Computer Vision[C]. Las Ve-gas: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016:2818-2826. |
| [60] | Heusel M, Ramsauer H, Unterthiner T, et al. Gans trained by a two time-scale update rule converge to a local nash equilibrium[J]. Advances in Neural Information Processing Systems, 2017(2):6626-6637. |
| [61] |
Wang Z, Bovik A C, Sheikh H R, et al. Image quality assessment:From error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4):600-612.
doi: 10.1109/TIP.2003.819861 |
| [62] | Sylvain T, Zhang P, Bengio Y, et al. Object-centric imagegeneration from layouts[EB/OL].(2020-03-16) [2022-01-18] http://arxiv.org.abs/2003.07449. |
| [63] | Ravuri S, Vinyals O. Classification accuracy score for conditional generative models[J]. Advances in Neural Information Processing Systems, 2019(6):12268-12279. |
| [64] | Kynkäänniemi T, Karras T, Laine S, et al. Improved prec-ision and recall metric for assessing generative models[J]. Advances in Neural Information Processing Systems, 2019(8):3927-3936. |
| [65] | Naeem M F, Oh S J, Uh Y, et al. Reliable fidelity and diversity metrics for generative models[C]. Vienna: International Conference on Machine Learning, 2020:7176-7185. |
| [66] | Zhang R, Isola P, Efros A A, et al. The unreasonable ef-fectiveness of deep features as a perceptual metric[C]. Salt Lake City: IEEE Conference on Computer Vision and Pattern Recognition, 2018:586-595. |
| [67] | Zhou S, Gordon M, Krishna R, et al. Hype:A benchmark for human eye perceptual evaluation of generative models[J]. Advances in Neural Information Processing Systems, 2019(3):3449-3461. |
| [68] | Papineni K, Roukos S, Ward T, et al. Bleu:A method for automatic evaluation of machine translation[C]. Philadelphia: The Fourtieth Annual Meeting of the Association for Computational Linguistics, 2002:311-318. |
| [69] | Nilsback M E, Zisserman A. Automated flower classification over a large number of classes[C]. New York: The Sixth Indian Conference on Computer Vision,Graphics & Image Processing, 2008:722-729. |
| [70] | Lin T Y, Maire M, Belongie S, et al. Microsoft coco:Co-mmon objects in context[C]. Zurich: European Confere-nce on Computer Vision, 2014:740-755. |
| [1] | SUN Hong,ZHAO Yingzhi. Lightweight Generative Adversarial Networks Based on Multi-Scale Gradient [J]. Electronic Science and Technology, 2023, 36(7): 32-38. |
| [2] | ZHAO Jin,LI Feifei. A GAN-Based Lightweight Style Transfer Model for Ink Painting [J]. Electronic Science and Technology, 2023, 36(2): 81-86. |
| [3] | SUN Kang,XUAN Xuyang,LIU Penghui,ZHAO Laijun,LONG Jie. Partial Discharge Pattern Recognition of Cable Based on CNN-DCGAN under Small Data [J]. Electronic Science and Technology, 2022, 35(7): 7-13. |
| [4] | LIU Jianlong,HAO Zhenghang. Comparative Study of Wind Power System Simulation Based on Back-to-Back Converters [J]. Electronic Science and Technology, 2022, 35(2): 67-73. |
| [5] | REN Xinrui,MA Lixin. Research on Main Steam Temperature Control System Based on Fuzzy PID Load Tracking [J]. Electronic Science and Technology, 2021, 34(5): 18-23. |
| [6] | LI Cheng,LIU Hao,JIANG Xifeng,WU Junfa,HAN Wengang,GAO Jianguo. Intelligent Diagnosis Algorithm of Generator Stator and Rotor Based on VGG Network [J]. Electronic Science and Technology, 2021, 34(11): 62-66. |
| [7] | TONG Bo,LIU Tao,LIU Chang. Research on Bearing Failure Signal Generation Based on Generative Adversarial Networks [J]. Electronic Science and Technology, 2020, 33(4): 28-34. |
| [8] | LIU Hanzi,SHI Yu,ZHANG Wei. Design of a Comb Generator Based on PLL [J]. Electronic Science and Technology, 2020, 33(3): 21-25. |
| [9] | ZHANG Darui,WANG Ding,WANG Xianying. Fabrication and Properties of GaN Energy Conversion Devices [J]. Electronic Science and Technology, 2020, 33(3): 62-65. |
| [10] | LIU Zhenxuan,YI Yingping,SHI Wei. Research on the Power Control of Grid-connected Inverter Based on VSG [J]. Electronic Science and Technology, 2020, 33(10): 6-14. |
| [11] | DENG Yapeng,DUAN Jundong,ZHANG Xiaofang,ZHANG Bin. Based on Thevenin Equivalence Static Analysis of Excitation Control for Synchronous Generator [J]. Electronic Science and Technology, 2019, 32(6): 1-6. |
| [12] | CHEN Wei,WANG Yagang. Semi-physical Modeling of Steam Generator Based on LabVIEW and Modbus [J]. Electronic Science and Technology, 2019, 32(2): 75-79. |
| [13] | PAN Linlin 1,LI Hongda 2,3 ,JIANG Jing 1,CHE Long 3,YIN Bo 1. Static Characteristic Research of ±60 kV Three Electrode Field Distortion Gas Switch [J]. , 2017, 30(4): 1-. |
| [14] | WANG Haiyan,QIN Jian,WANG Xujia. An Improved MPPT Algorithm Based on SG/Simulink [J]. , 2017, 30(4): 103-. |
| [15] | LI Shiqi. Design of Intermediate Frequency Signal Generator for Radar Signal Simulator [J]. , 2016, 29(5): 58-. |
|
