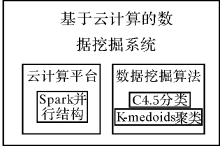
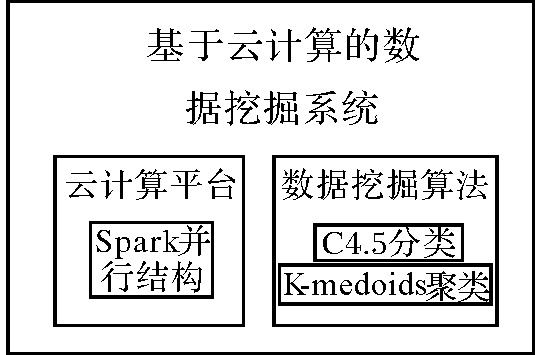
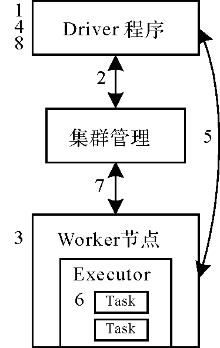
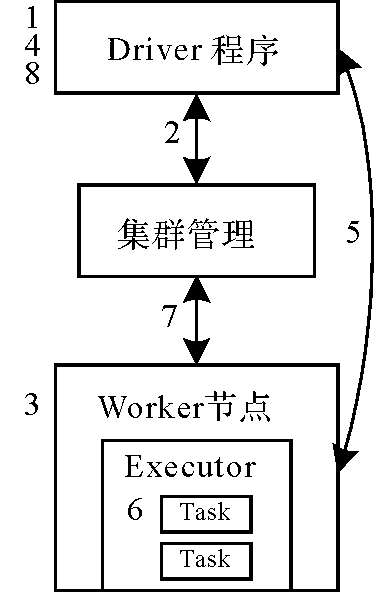
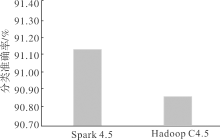
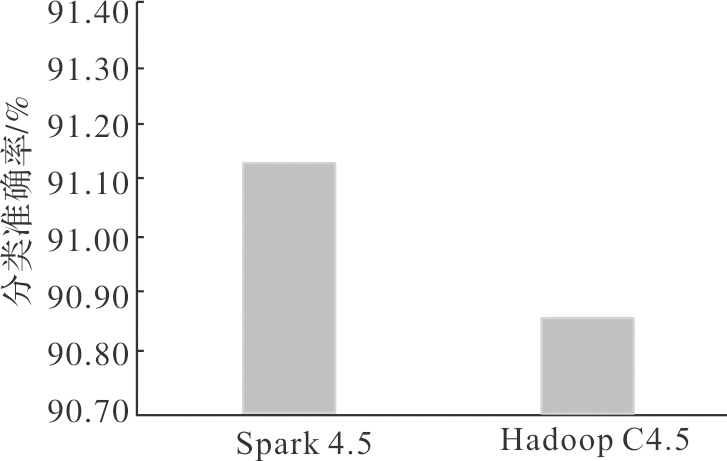
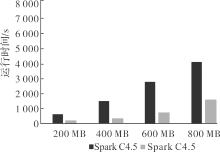
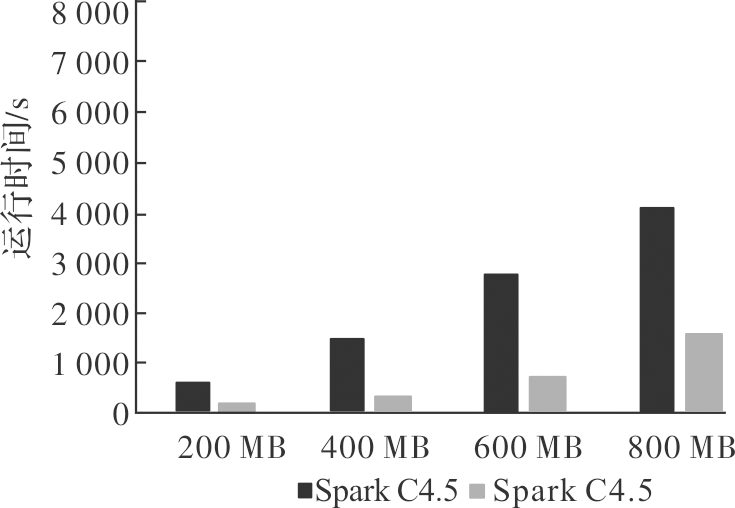
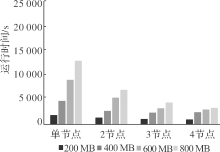
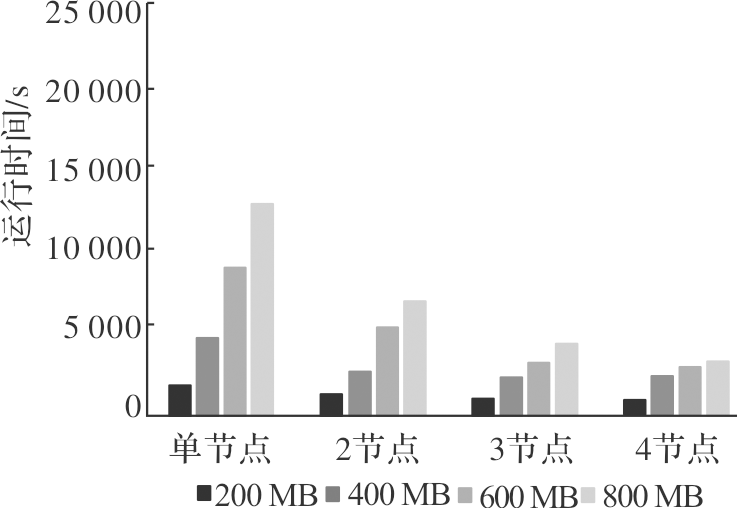
| [1] |
于连城, 张译, 张广德 , 等. 基于Canopy-k-means算法的电网数据挖掘算法的研究[J]. 国外电子测量技术, 2018,37(7):35-39.
|
|
Yu Liancheng, Zhang Yin, Zhang Guangde , et al. Research on data mining algorithm of power grid based on Canopy-K-means algorithm[J]. Foreign Electronic Measurement Technology, 2018,37(7):35-39.
|
| [2] |
胡莹石, 陈家晨, 徐菱 . 云计算下数据挖掘平台架构及技术探究[J]. 无线互联科技, 2018,15(12):60-61,64.
|
|
Hu Yingshi, Chen Jiachen, Xu Ling . Architecture and technology exploration of data mining platform under cloud computing[J]. Wireless Interconnection Technology, 2018,15(12):60-61,64.
|
| [3] |
毛典辉 . 基于Map Reduce的Canopy-Kmeans改进算法[J]. 计算机工程与应用, 2012,48(27):22-26,68.
|
|
Mao Dianhui . An improved Canopy-Kmeans algorithm based on Map Reduce[J]. Computer Engineering and Applications, 2012,48(27):22-26,68.
|
| [4] |
张雪萍, 龚康莉, 赵广才 . 基于Map Reduce的K-Medoids并行算法[J]. 计算机应用, 2013,33(4):1023-1025,1035.
doi: 10.3724/SP.J.1087.2013.01023
|
|
Zhang Xueping, Gong Kangli, Zhao Guangcai . K-Medoids parallel algorithms based on MapReduce[J]. Computer Applications, 2013,33(4):1023-1025,1035.
doi: 10.3724/SP.J.1087.2013.01023
|
| [5] |
王诏远, 王宏杰, 邢焕来 , 等. 基于Spark的蚁群优化算法[J]. 计算机应用, 2015(10):2777-2780,2797.
|
|
Wang Zhaoyuan, Wang Hongjie, Xing Huanlai , et al. Ant colony optimization based on Spark[J]. Computer Applications, 2015(10):2777-2780,2797.
|
| [6] |
牛海玲, 鲁慧民, 刘振杰 . 基于Spark的Apriori算法的改进[J]. 东北师大学报:自然科学版, 2016(1):84-89.
|
|
Niu Hailing, Lu Huimin, Liu Zhenjie . Improvement of Apriori algorithm based on Spark[J]. Northeast Normal University Journal:Natural Science Edition, 2016(1):84-89.
|
| [7] |
陈光平, 王文鹏, 黄俊 . 一种改进初始聚类中心选择的K-means算法[J]. 小型微型计算机系统, 2012,33(6):1320-1323.
|
|
Chen Guangping, Wang Wenpeng, Huang Jun . A K-means algorithm for improving initial clustering center selection[J]. Minicomputer System, 2012,33(6):1320-1323.
|
| [8] |
赖向阳, 宫秀军, 韩来明 . 一种Map Reduce架构下基于遗传算法的K-Medoids聚类[J]. 计算机科学, 2017,44(3):23-26,58.
|
|
Lai Xiangyang, Gong Xiujun, Han Laiming . K-Medoids clustering based on genetic algorithms in Map Reduce architecture[J]. Computer Science, 2017,44(3):23-26,58.
|
| [9] |
许晓燕 . 基于云计算的数据挖掘云服务模式研究[J]. 电脑知识与技术, 2018,14(19):16-17.
|
|
Xu Xiaoyan . Research on cloud service model of data mining based on cloud computing[J]. Computer Knowledge and Technology, 2018,14(19):16-17.
|
| [10] |
张菁 . 云计算技术下海量数据挖掘的实现机制[J]. 安徽水利水电职业技术学院学报, 2018,18(1):62-64.
|
|
Zhang Jing . Implementation mechanism of massive data mining under cloud computing technology[J]. Journal of Anhui Vocational and Technical College of Water Resources and Hydropower, 2018,18(1):62-64.
|
| [11] |
孙亮 . 数据挖掘服务模式应用云计算的优化策略探究[J]. 黑河学院学报, 2018,9(1):211-212.
|
|
Sun Liang . Research on the optimization strategy of cloud computing in data mining service mode[J]. Journal of Heihe University, 2018,9(1):211-212.
|
| [12] |
刘飞, 唐雅娟, 刘瑶 . K-means聚类算法中聚类个数的方法研究[J]. 电子设计工程, 2017,25(15):9-13.
|
|
Liu Fei, Tang Yajuan, Liu Yao . K-means clustering algorithms for the number of clustering methods[J]. Electronic Design Engineering, 2017,25(15):9-13.
|
| [13] |
李坤, 刘鹏, 吕雅洁 , 等. 基于Spark的LIBSVM参数优选并行化算法[J]. 南京大学学报:自然科学版, 2016(2):343-352.
|
|
Li Kun, Liu Peng, Lv Yajie , et al. LIBSVM parallelization algorithm for parameter optimization based on Spark[J]. Journal of Nanjing University: Natural Science Edition, 2016(2):343-352.
|