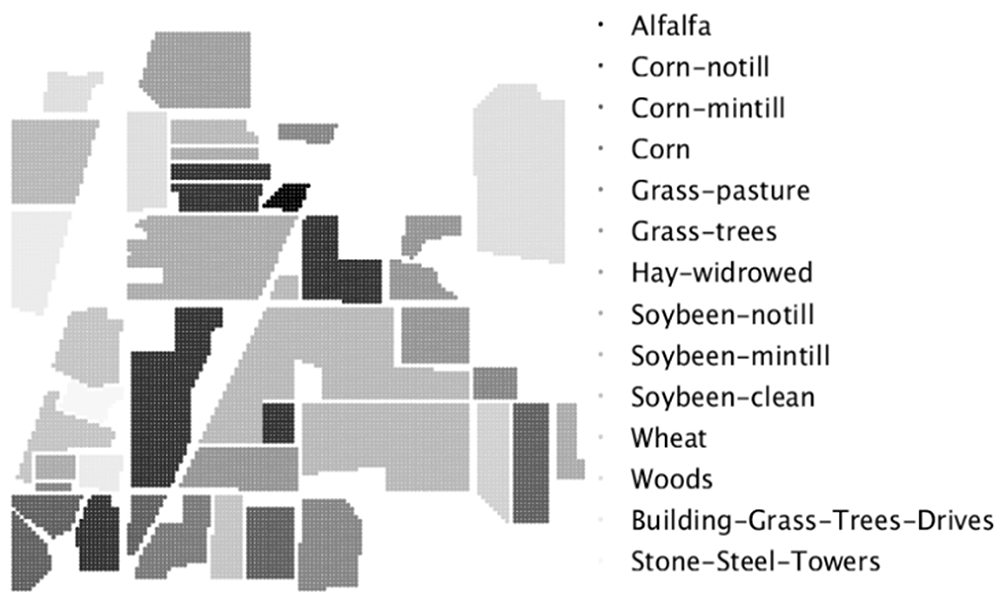
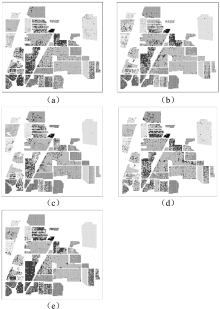
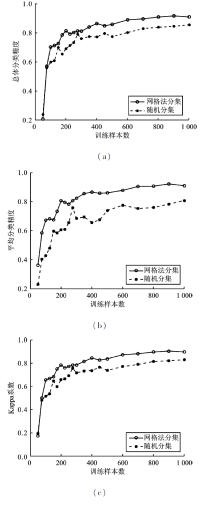
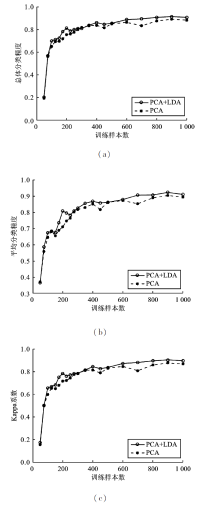
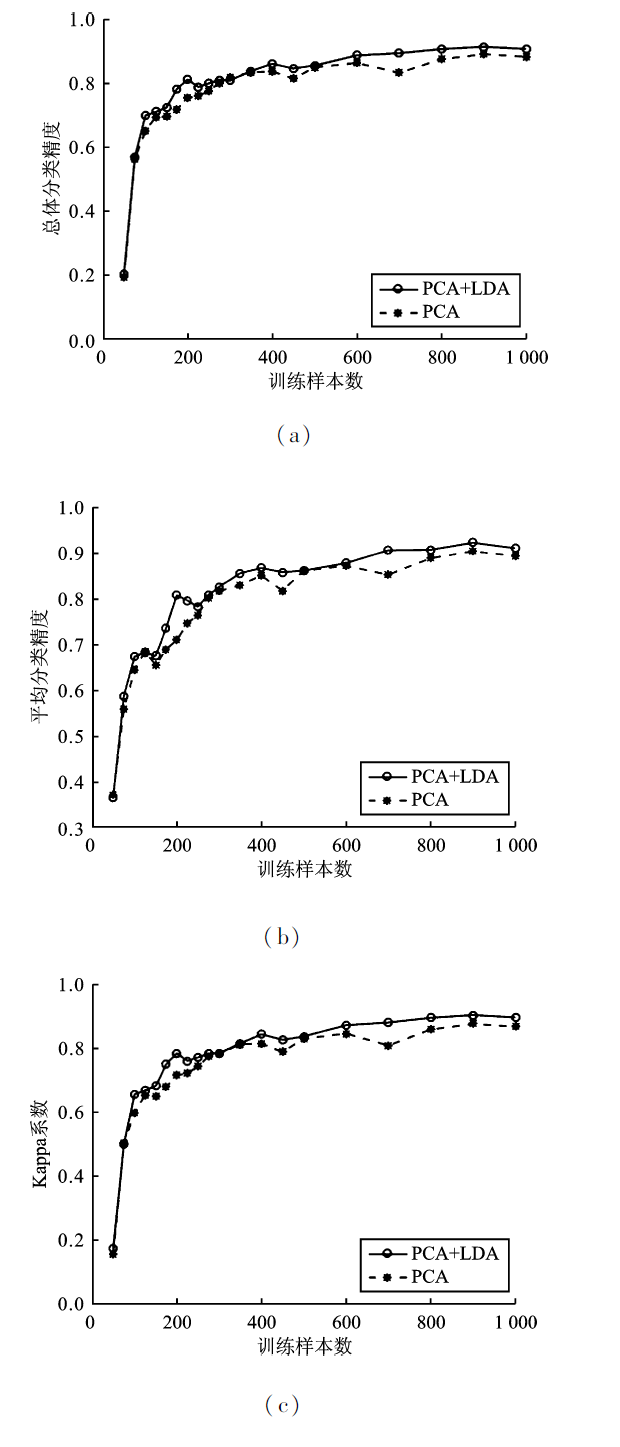
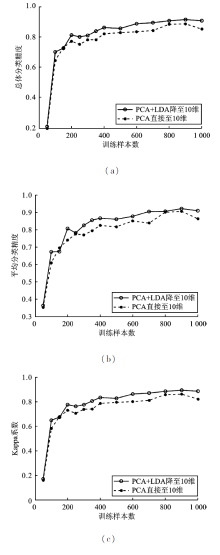
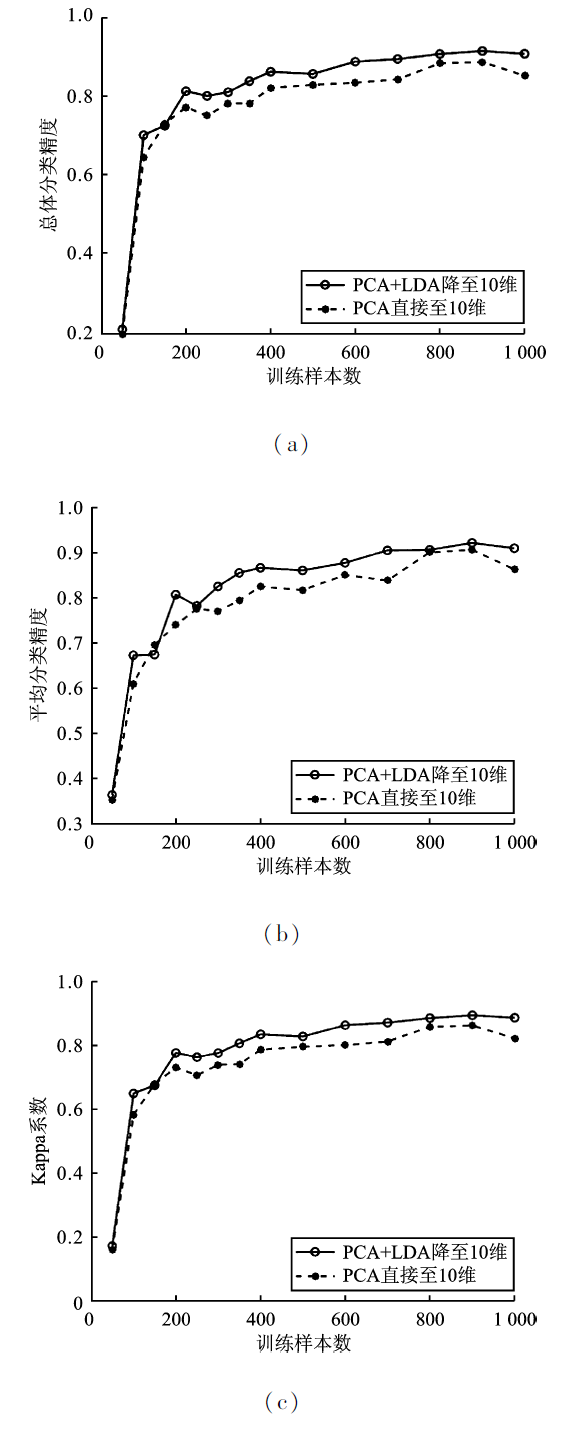
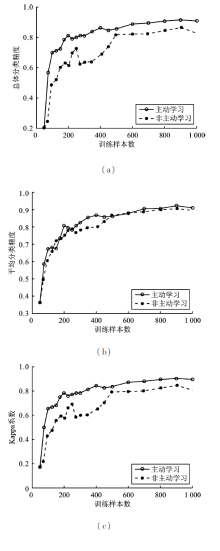
| [1] |
张兵. 光学遥感信息技术与应用研究综述[J]. 南京信息工程大学学报(自然科学版), 2018, 10(1):1-5.
|
|
Zhang Bing. A survey of developments on optical remote sensing information technology and applications[J]. Journal of Nanjing University of Information Science and Technology (Natural Science Edition), 2018, 10(1):1-5.
|
| [2] |
万东燕, 许桢英, 杨卿, 等. 基于PCA与SVM的焊缝缺陷信号分类方法[J]. 电子科技, 2020, 33(5):9-14.
|
|
Wan Dongyan, Xu Zhenying, Yang Qing, et al. A method of weld defect classification based on PCA and SVM[J]. Electronic Science and Technology, 2020, 33(5):9-14.
|
| [3] |
王瀛, 余岚旭, 王春喜, 等. 基于改进的IHS、PCA和小波变换的遥感图像融合算法[J]. 计算机与数字工程, 2021, 49(4):797-803.
|
|
Wang Ying, Yu Lanxu, Wang Chunxi, et al. Remote sensing image fusion algorithm based on improved IHS,PCA and wavelet transform[J]. Computer & Digital Engineering, 2021, 49(4):797-803.
|
| [4] |
Da Silva A C, Soares S F C, Insausti M, et al. Two-dimensional linear discriminant analysis for classification of three-way chemical data[J]. Analytica Chimica Acta, 2016, 93(8): 53-62.
doi: 10.1016/0003-2670(77)80006-8
|
| [5] |
王姗姗. 高光谱图像特征提取和分类算法研究[D]. 大连: 辽宁师范大学, 2020.
|
|
Wang Shanshan. Research on hyperspectral image feature extraction and classification algorithm[D]. Dalian: Liaoning Normal University, 2020.
|
| [6] |
张号逵, 李映, 姜晔楠. 深度学习在高光谱图像分类领域的研究现状与展望[J]. 自动化学报, 2018, 44(6):961-977.
|
|
Zhang Haokui, Li Ying, Jiang Yenan. Deep learning for hyperspectral imagery classification:The state of the art and prospects[J]. Acta Automatica Sinica, 2018, 44(6):961-977.
|
| [7] |
李响, 吕勇. 结合拉普拉斯特征映射的权重朴素贝叶斯高光谱分类算法[J]. 分析测试学报, 2020, 39(10):1293-1298.
|
|
Li Xiang, Lü Yong. A weighted naive Bayes hyperspectral classification algorithm combined with Laplacian eigen mapping[J]. Journal of Instrumental Analysis, 2020, 39(10):1293-1298.
|
| [8] |
Zhang H, Li Y, Zhang Y, et al. Spectral-spatial classification of hyperspectral imagery using a dual-channel convolutional neural network[J]. Remote Sensing Letters, 2017, 8(5):438-447.
doi: 10.1080/2150704X.2017.1280200
|
| [9] |
李秉璇, 周冰, 贺宣, 等. 针对高光谱图像的目标分类方法现状与展望[J]. 激光与红外, 2020, 50(3):259-265.
|
|
Li Bingxuan, Zhou Bing, He Xuan, et al. Status and prospects of target classification methods based on hyperspectral images[J]. Laser & Infrared, 2020, 50(3):259-265.
|
| [10] |
杜培军, 夏俊士, 薛朝辉, 等. 高光谱遥感影像分类研究进展[J]. 遥感学报, 2016, 20(2):236-256.
|
|
Du Peijun, Xia Junshi, Xue Zhaohui, et al. Review of hyperspectral remote sensing image classification[J]. Journal of Remote Sensing, 2016, 20(2):236-256.
|
| [11] |
杨承文, 李吉明, 杨东勇. 基于深度贝叶斯主动学习的高光谱图像分类[J]. 计算机工程与应用, 2019, 55(18):166-172.
doi: 10.3778/j.issn.1002-8331.1805-0427
|
|
Yang Chengwen, Li Jiming, Yang Dongyong. Active learning for hyperspectral image classification with deep Bayesian[J]. Computer Engineering and Applications, 2019, 55(18):166-172.
doi: 10.3778/j.issn.1002-8331.1805-0427
|
| [12] |
Yuan J, Hou X X, Xiao Y Q, et al. Multi-criteria active deep learning for image classification[J]. Knowledge-Based Systems, 2019, 17(2):86-94.
|
| [13] |
王立国, 商卉, 石瑶. 结合主动学习与标签传递算法的高光谱图像分类[J]. 哈尔滨工程大学学报, 2020, 41(5):731-737.
|
|
Wang Liguo, Shang Hui, Shi Yao. Hyperspectral imagery classification based on active learning and label propagation[J]. Journal of Harbin Engineering University, 2020, 41(5):731-737.
|
| [14] |
宋晗, 杨炜暾, 耿修瑞, 等. 基于卷积神经网络与主动学习的高光谱图像分类[J]. 中国科学院大学学报, 2020, 37(2):169-176.
doi: 10.7523/j.issn.2095-6134.2020.02.004
|
|
Song Han, Yang Weitun, Geng Xiurui, et al. Hyperspectral image classification based on convolutional neural network and active learning algorithm[J]. Journal of University of Chinese Academy of Sciences, 2020, 37(2) :169-176.
doi: 10.7523/j.issn.2095-6134.2020.02.004
|
| [15] |
侯超群. 主动学习策略研究及其在图像分类中的应用[D]. 厦门: 厦门大学, 2019.
|
|
Hou Chaoqun. Research on strategies of active learning and its application to image classification[D]. Xiamen: Xiamen University, 2019.
|
| [16] |
崔颖, 徐凯, 陆忠军, 等. 主动学习策略融合算法在高光谱图像分类中的应用[J]. 通信学报, 2018, 39(4):91-99.
|
|
Cui Ying, Xu Kai, Lu Zhongjun, et al. Combination strategy of active learning for hyperspectral images classification[J]. Journal on Communications, 2018, 39(4):91-99.
|
| [17] |
肖博林. 基于支持向量机的高光谱遥感影像分类[J]. 科技创新与应用, 2020(4):22-24.
|
|
Xiao Bolin. Hyperspectral remote sensing image classification based on support vector machine[J]. Technology Innovation and Application, 2020(4):22-24.
|
| [18] |
孙丽萍, 张希萌, 何睿, 等. 基于SVM的近红外黑木耳多糖含量分类[J]. 电子科技, 2019, 32(8):16-21.
|
|
Sun Liping, Zhang Ximeng, He Rui, et al. Near-infrared scanning polysaccharide content classification of auricularia auricular based on SVM[J]. Electronic Science and Technology, 2019, 32(8):16-21.
|
| [19] |
刘方园, 王水花, 张煜东. 支持向量机模型与应用综述[J]. 计算机系统应用, 2018, 27(4):1-9.
|
|
Liu Fangyuan, Wang Shuihua, Zhang Yudong. Overview on models and applications of support vector machine[J]. Computer Systems & Applications, 2018, 27(4):1-9.
|