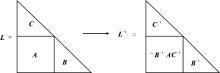
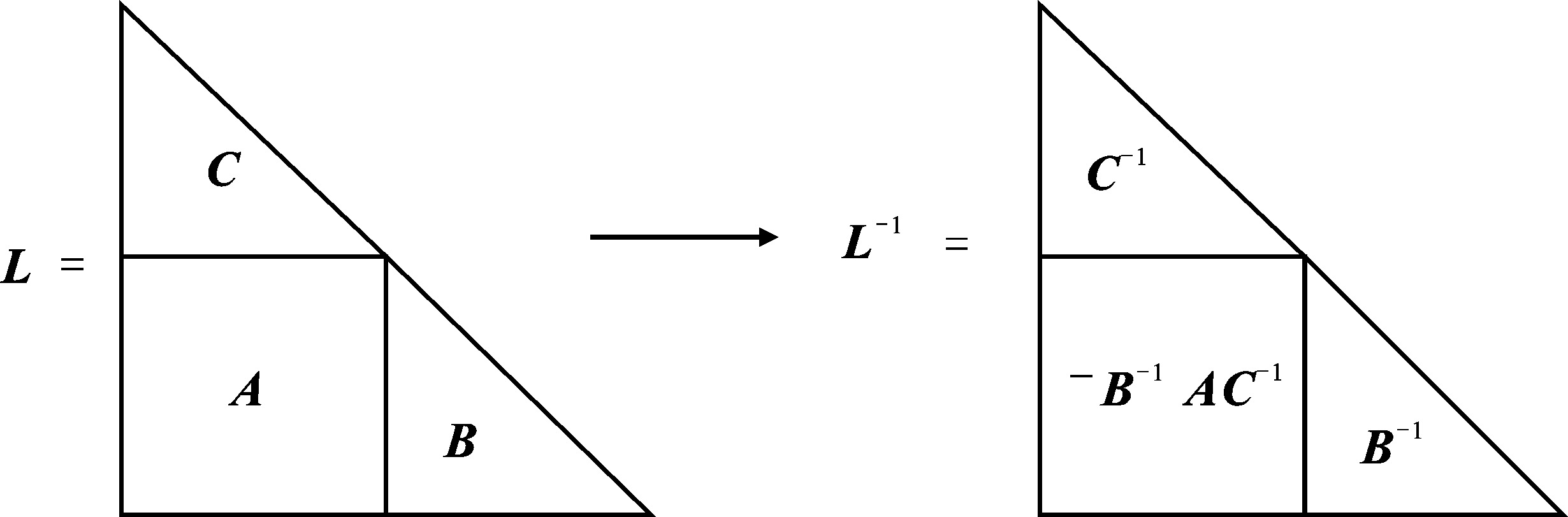
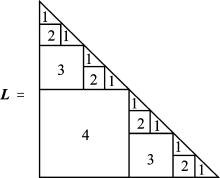
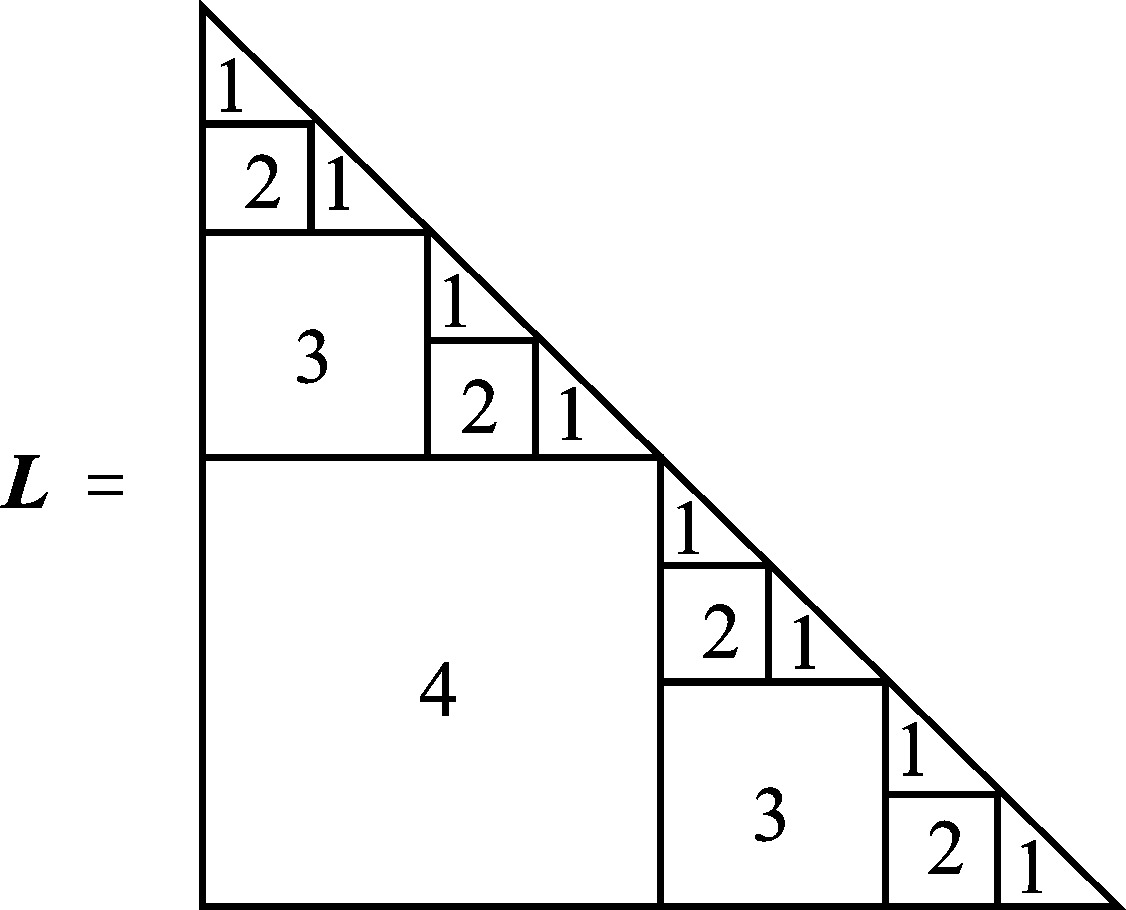
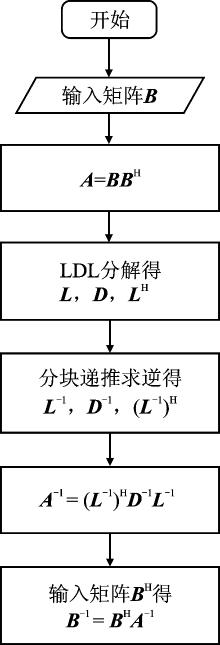
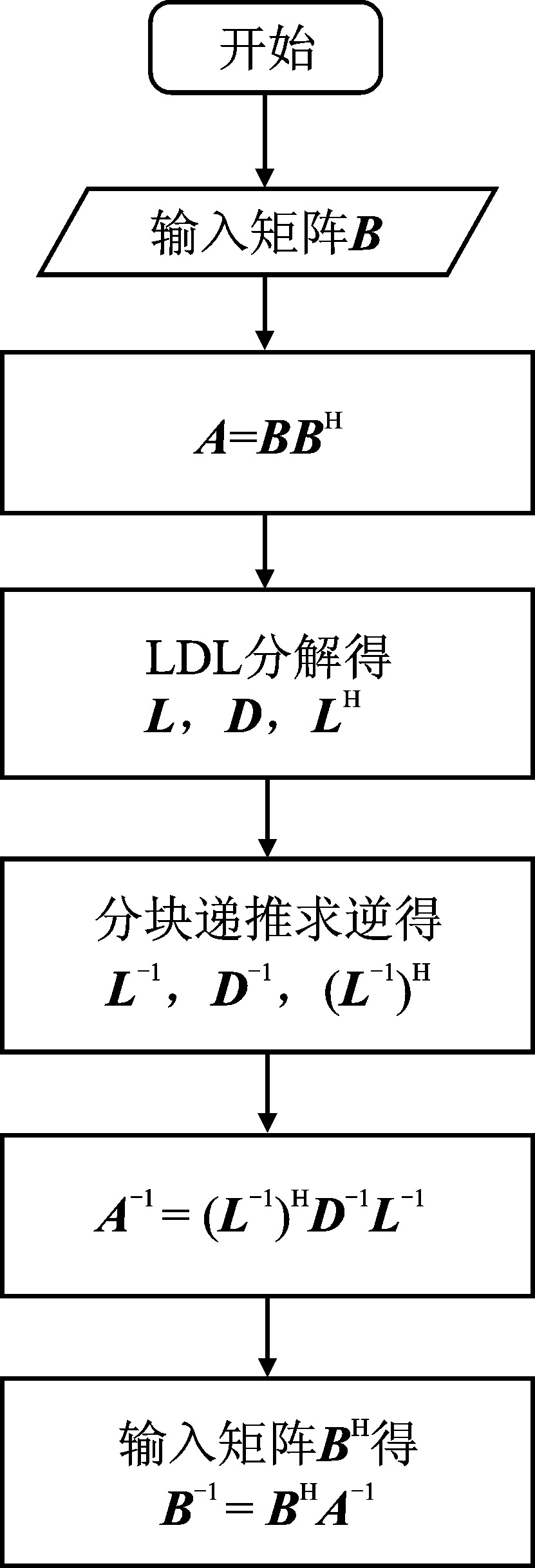
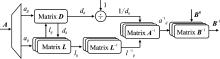
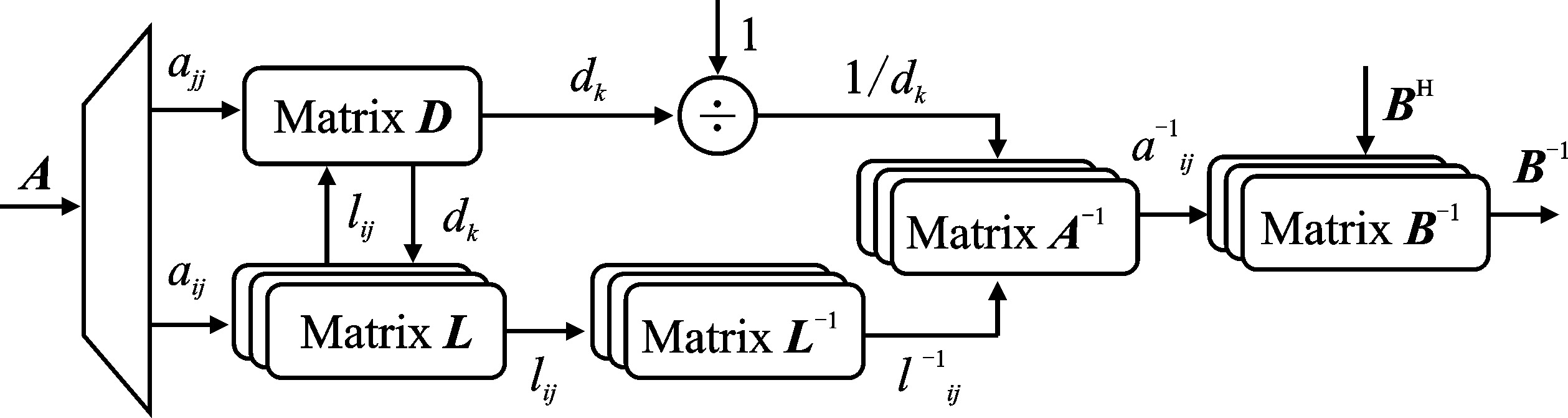
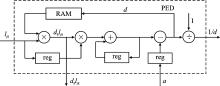
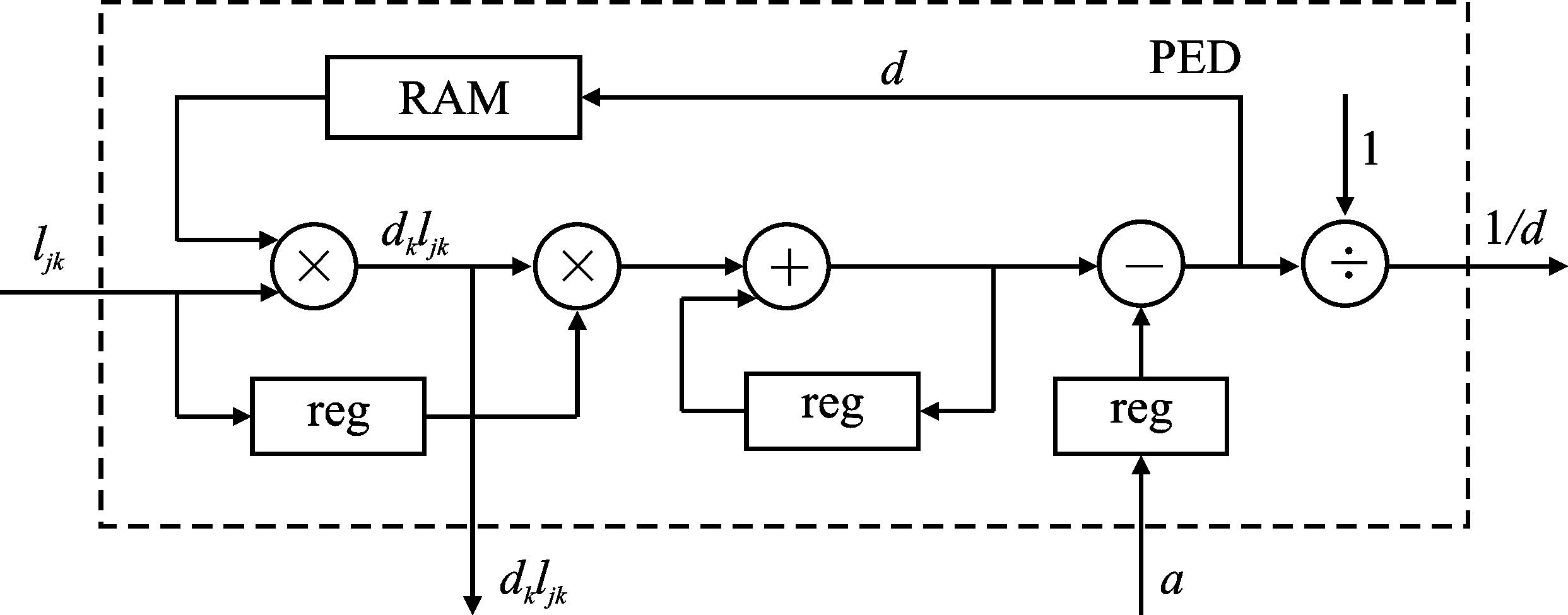
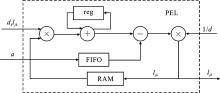
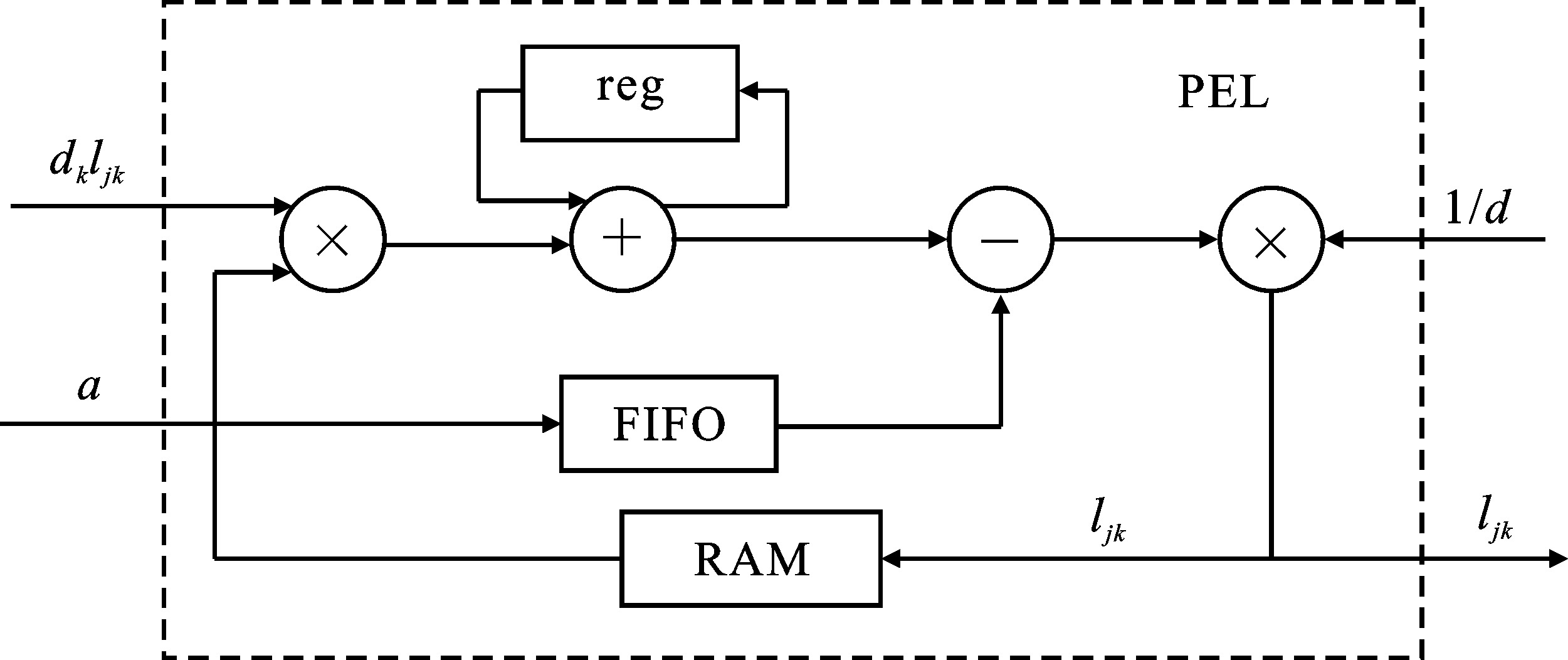
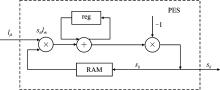
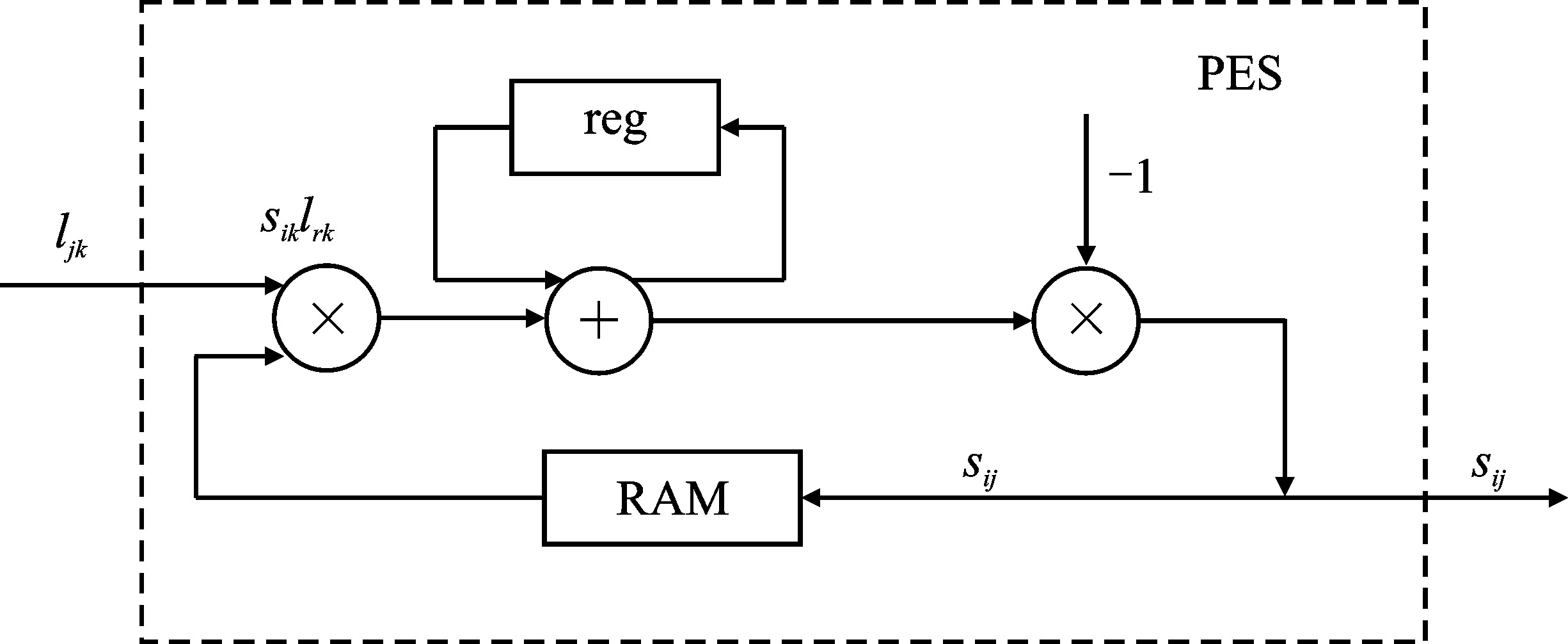
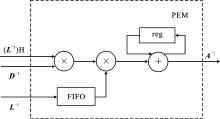
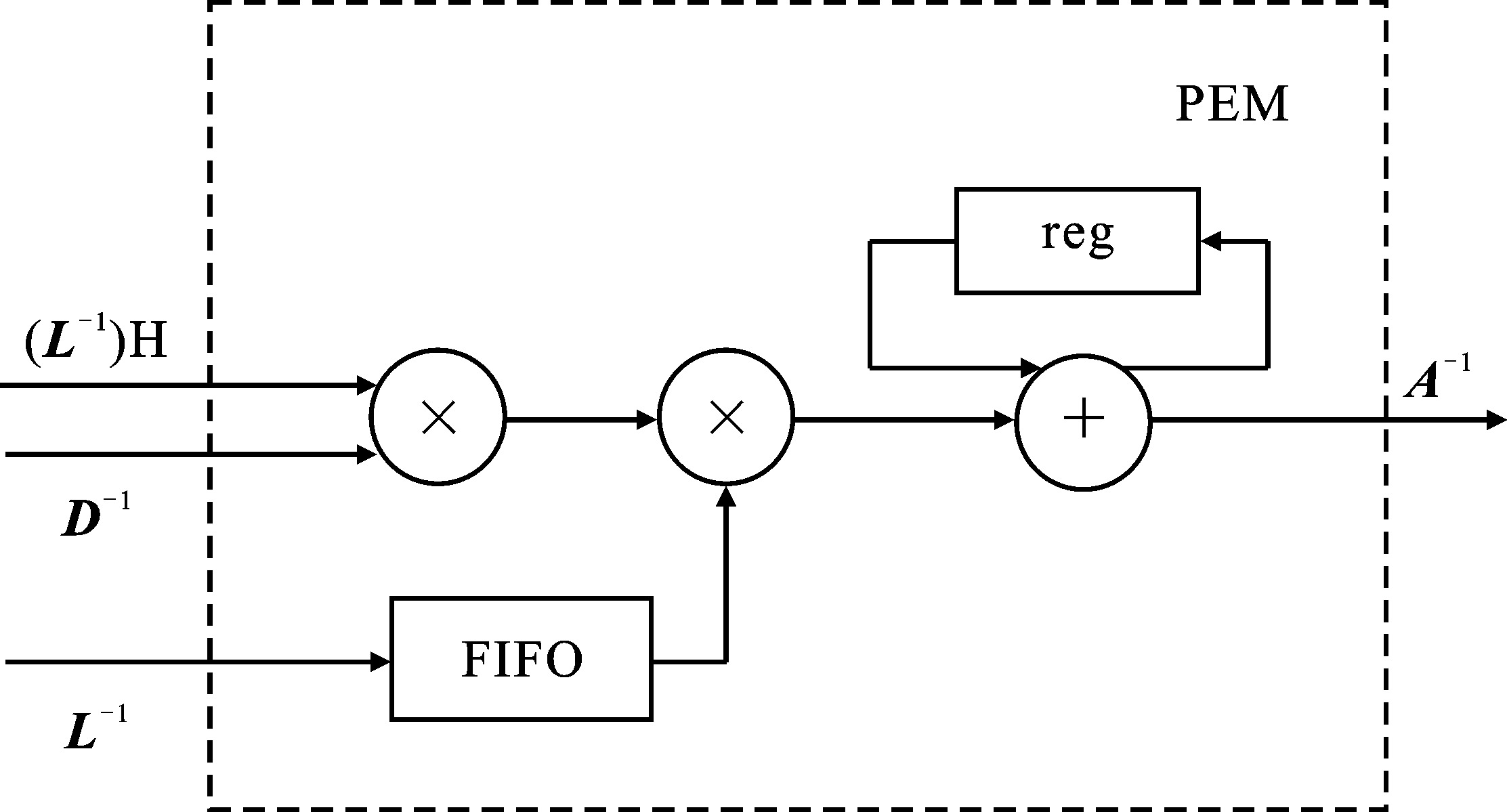
| [1] |
Liu Q, Qin S, Yu B, et al. π-BA:Bundle adjustment hardware accelerator based on distribution of 3D-point observations[J]. IEEE Transactions on Computers, 2020, 69(7):1083-1095.
|
| [2] |
Hyukyeon L, Kyungmook O, Minjeong C, et al. Efficient low-latency implementation of CORDIC-based sorted QR decomposition for multi-gbps MIMO systems[J]. IEEE Transactions on Circuits and Systems II: Express Briefs, 2018, 65(10):1375-1379.
doi: 10.1109/TCSII.2018.2853099
|
| [3] |
汪杨, 王晓蕾, 袁子昂, 等. 一种基于NoC多核系统的矩阵乘法映射技术[J]. 电子科技, 2021, 34(5):54-60.
|
|
Wang Yang, Wang Xiaolei, Yuan Ziang, et al. A matrix multiplication mapping technology based on NOC multi- core system[J]. Electronic Science and Technology, 2021, 34(5):54-60.
|
| [4] |
Liu H, Wang K, Dong P, et al. Curve-driven-based acoustic inversion for photoacoustic tomography[J]. IEEE Transactions on Medical Imaging, 2016, 35(12):2546-2557.
pmid: 27352391
|
| [5] |
Lutzweiler C, Tzoumas S, Rosenthal A, et al. High- throughput sparsity-based inversion scheme for optoacoustic tomography[J]. IEEE Transactions on Medical Imaging, 2016, 35(2):674-684.
doi: 10.1109/TMI.2015.2490799
pmid: 26469127
|
| [6] |
Ding L, Deán-Ben X L, Razansky D. Real-time model -based inversion in cross-sectional optoacoustic tomography[J]. IEEE Transactions on Medical Imaging, 2016, 35(8):1883-1891.
doi: 10.1109/TMI.2016.2536779
pmid: 26955023
|
| [7] |
刘璐, 张洪艳, 张良培. 基于光谱加权低秩矩阵分解的高光谱影像去噪方法[J]. 电子科技, 2020, 33(5):21-27.
|
|
Liu Lu, Zhang Hongyan, Zhang Liangpei. Hyperspectral image denoising via spectral weighted low rank matrix approximation[J]. Electronic Science and Technology, 2020, 33(5):21-27.
|
| [8] |
Wang S S, Tien Y C, Hwang Y T, et al. MVDR based adaptive beamformer design and its FPGA implementation for ultrasonic imaging[C]. Jeju: IEEE Asia Pacific Conference on Circuits and Systems.IEEE, 2016:143-145.
|
| [9] |
Munoz S D, Hormigo J. High-throughput FPGA implementation of QR decomposition[J]. IEEE Transactions on Circuits & Systems II Express Briefs, 2015, 62(9):861-865.
|
| [10] |
Chen J, Liang X, Chen Z. Online algorithm-based fault tolerance for cholesky decomposition on heterogeneous systems with GPUs[C]. Chicago:IEEE International Parallel and Distributed Processing Symposium, 2016:993-1002.
|
| [11] |
Gangarajaiah R, Prabhu H, Edfors O, et al. A cholesky decomposition based massive MIMO uplink detector with adaptive interpolation[C]. Baltimore: IEEE International Symposium on Circuits and Systems, 2017:1-4.
|
| [12] |
Mahajan Y, Obla S, Namboothiripad M K, et al. FPGA -based acceleration of LU decomposition for analog and RF circuit simulation[C]. Pune:Proceedings of the Thirty-third International Conference on VLSI Design and Nineteenth International Conference on Embedded Systems, 2020:131-136.
|
| [13] |
Hashemian R. UaL Decomposition an Alternative to the LU factorization of MNA matrices[J]. IEEE Transactions on Circuits and Systems II:Express Briefs, 2020, 67(4):630-634.
doi: 10.1109/TCSII.8920
|
| [14] |
Xu Y, D Li, Xi Y, et al. Improved predictive controller on FPGA by hardware matrix inversion[J]. IEEE Transactions on Industrial Electronics, 2018, 65(9):7395-7405.
doi: 10.1109/TIE.41
|
| [15] |
Vosvrda M S. Discrete random signals and statistical signal processing: Charles W.Therrien[J]. Automatica, 1993, 29(6):1617-1623.
|
| [16] |
黄廷祝, 钟守铭, 李正良. 矩阵理论[M]. 北京: 高等教育出版社, 2003:23-67.
|
|
Huang Tingzhu, Zhong Shouming, Li Zhengliang. Matrix theory[M]. Beijing: Higher Education Press, 2003:23-67.
|
| [17] |
陈宗泽. 大规模矩阵求逆运算电路设计与优化[D]. 南京: 东南大学, 2019:49-56.
|
|
Chen Zongze. Design and optimization of large-scale matrix inverse operation circuit[D]. Nanjing: Southeast University, 2019:49-56.
|
| [18] |
Gaithuru J N, Salleh M, Mohamad I. NTRU inverse polynomial algorithm based on the LU decomposition method of matrix inversion[C]. Miri:IEEE Conference on Application, Information and Network Security, 2017:1-6.
|
| [19] |
李丽, 张巍. 改进Cholesky分解算法的设计与FPGA实现[J]. 电讯技术, 2020, 60(7):845-849.
|
|
Li Li, Zhang Wei. Improved Cholesky decomposition algorithm design and FPGA implementation[J]. Telecommunications Technology, 2020, 60(7):845-849.
|