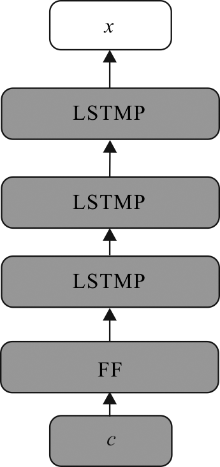
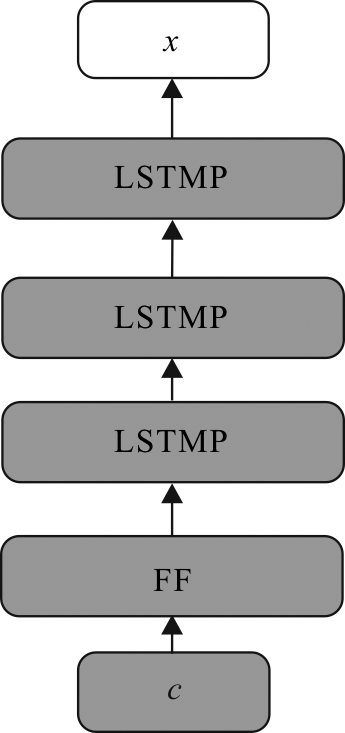
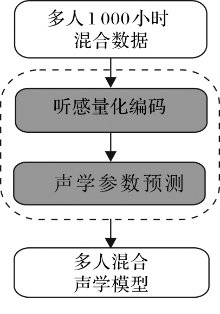
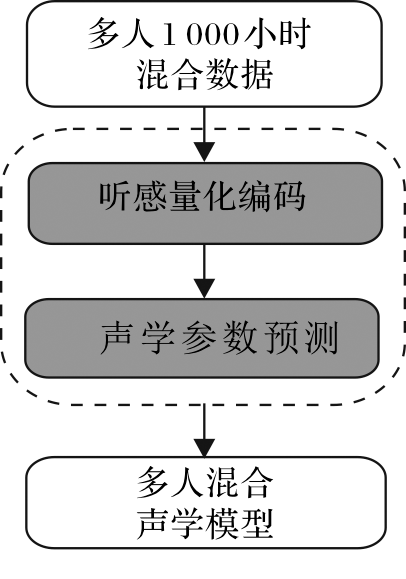
| [1] |
Yoshimura T, Tokuda K, Masuko T, et al. Simultaneous modeling of spectrum, pitch and duration in HMM-based speech synconfproc [C].Budapest:Sixth European Conference on Speech Communication and Technology, EUROSPEECH, 1999.
|
| [2] |
Tokuda K, Masuko T, Miyazaki N , et al. Hidden Markov models based on multi-space probability distribution for pitch pattern modeling[C].Phoenix:International Conference on Acoustics, Speech and Signal Processing(ICASSP), 1999.
|
| [3] |
Tokuda K, Yoshimura T, Masuko T , et al. Speech parameter generation algorithms for HMM-based speech synconfproc[C].Istanbul:International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2000.
|
| [4] |
Ling Z H, Deng L, Yu D . Modeling spectral envelopes using restricted Boltzmann machines and deep belief networks for statistical parametric speech synjournal[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2013,21(10):2129-2139.
|
| [5] |
Zen H . Deep learning in speech synconfproc[C].Guangzhou:Keynote Speech Given at Isca Speech Synconfproc Workshop (SSW8), 2013.
|
| [6] |
Fan Y, Qian Y, Xie F L , et al. TTS synconfproc with bidirectional LSTM based recurrent neural networks[C].Minneapolis:Fifteenth Annual Conference of the International Speech Communication Association(ISCA), 2014.
|
| [7] |
Zen H, Sak H. Unidirectional long short-term memory recurrent neural network with recurrent output layer for low-latency speech synconfproc [C].South Brisbane: International Conference on Acoustics,Speech and Signal Processing (ICASSP),IEEE, 2015.
|
| [8] |
Ling Z H, Kang S Y, Zen H , et al. Deep learning for acoustic modeling in parametric speech generation: A systematic review of existing techniques and future trends[J]. IEEE Signal Processing Magazine, 2015,32(3):35-52.
|
| [9] |
Takaki S, Yamagishi J . A deep auto-encoder based low-dimensional feature extraction from FFT spectral envelopes for statistical parametric speech synconfproc [C]. Shanghai:International Conference on Acoustics, Speech and Signal Processing (ICASSP),IEEE, 2016.
|
| [10] |
Chen L H, Raitio T, Valentini-Botinhao C , et al. DNN-based stochastic postfilter for HMM-based speech synconfproc [C]. Singapore:15 th Annual Conference of the International Speech Communication Association,INTERSPEECH , 2014.
|
| [11] |
Kaneko T, Kameoka H, Hojo N , et al. Generative adversarial network-based postfilter for statistical parametric speech synconfproc [C].New Orleans:International Conference on Acoustics, Speech and Signal Processing (ICASSP),IEEE, 2017.
|
| [12] |
刘庆峰 . 基于听感量化理论的语音合成系统研究[D]. 合肥:中国科学技术大学, 2003.
|
|
Liu Qingfeng . Research on perception quantification-based speech synthesis system[D]. Hefei:University of Science and Technology of China, 2003.
|
| [13] |
Hu Y J, Ling Z H . DBN-based spectral feature representation for statistical parametric speech synjournal[J]. IEEE Signal Processing Letters, 2016,23(3):321-325.
|
| [14] |
Liu L J, Ding C, Jiang Y, et al. The IFLYTEK system for blizzard challenge [C].Stockholm:The Blizzard ChallengeWorkshop, 2017.
|
| [15] |
An S, Ling Z, Dai L. Emotional statistical parametric speech synconfproc using LSTM-RNNs [C].Kuala Lumpur : Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC),IEEE, 2017.
|
| [16] |
Hu Y J, Ling Z H . Extracting spectral features using deep autoencoders with binary distributed hidden units for statistical parametric speech synjournal[J]. IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), 2018,26(4):713-724.
|