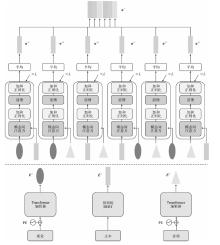
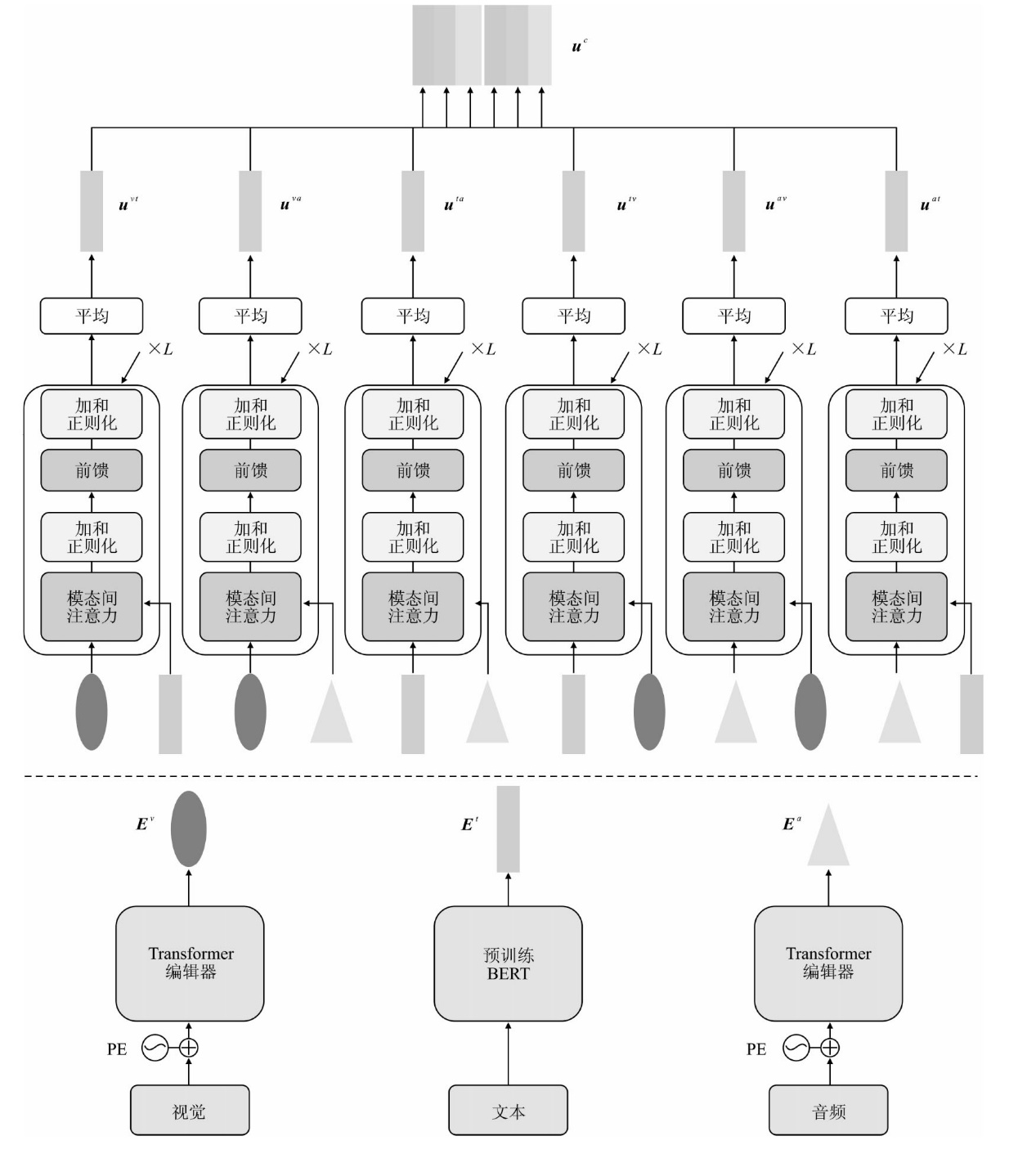
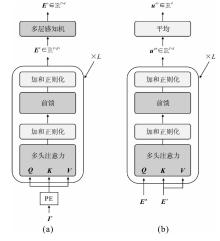
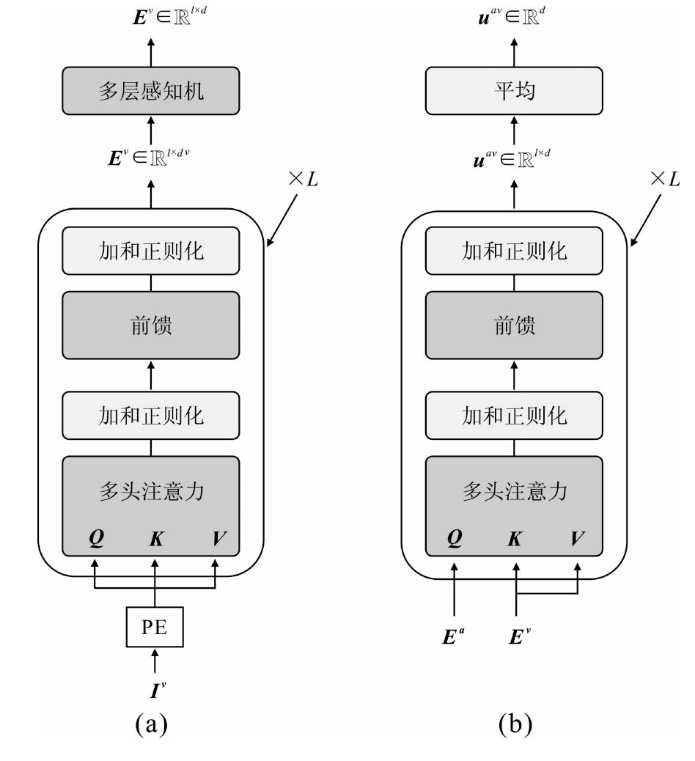
| [1] |
左斌, 李菲菲. 基于注意力机制和Inf-Net的新冠肺炎图像分割方法[J]. 电子科技, 2023, 36(2):22-28.
|
|
Zuo Bin, Li Feifei. An effective segmentation method for COVID-19 CT image based on attention mechanism and Inf-Net[J]. Electronic Science and Technology, 2023, 36(2):22-28.
|
| [2] |
林潮威, 李菲菲, 陈虬. 基于深度卷积特征的场景全局与局部表示方法[J]. 电子科技, 2022, 35(4):20-27.
|
|
Lin Chaowei, Li Feifei, Chen Qiu. Globaland local scene representation method based on deep convolutional features[J]. Electronic Science and Technology, 2022, 35(4):20-27.
|
| [3] |
Mittal T, Bhattacharya U, Chandra R, et al. M3ER:Multi-plicative multimodal emotion recognition using facial,textual,and speech cues[C]. New York: Proceedings of the AAAI Conference on Artificial Intelligence,2020:51359-1367.
|
| [4] |
Liu K, Li Y, Xu N, et al. Learn to combine modalities in multimodal deep learning[EB/OL].(2018-05-29)[2023-03-10].
|
| [5] |
Tzirakis P, Chen J, Zafeiriou S, et al. End-to-end multimodal affect recognition in real-world environments[J]. Information Fusion, 2021, 68(1):46-53.
|
| [6] |
Lyu H, Sha N, Qin S, et al. Manifold denoising by nonlinear robust principal component analysis[J]. Advances in Neural Information Processing Systems, 2019, 32(1):2-12.
|
| [7] |
Lee J, Toutanova K. BERT:Pretraining of deep bidirectional transformers for language understanding[EB/OL].(2019-05-24)[2023-03-09]https://arxiv.53yu.com/abs/1810.04805. .
|
| [8] |
Yang K, Xu H, Gao K. CM-BERT:Cross-modal BERT f-or text-audio sentiment analysis[C]. Beijing: Proceedings of the Twenty-eighth ACM International Conference on Multimedia,2020:521-528.
|
| [9] |
Rahman W, Hasan M K, Lee S, et al. Integrating multi-modal information in large pretrained transformers[C]. Online: Proceedings of the Conference on Association for Computational Linguistics,2020:2359-2371.
|
| [10] |
Kim K, Park S. AOBERT:All-modalities-in-one BERT for multimodal sentiment analysis[J]. Information Fusion, 2023, 92(6):37-45.
|
| [11] |
Zadeh A, Liang P P, Poria S, et al. Multi-attention recur-rent network for human communication comprehension[C]. New Orleans: Proceedings of the AAAI Conference on Artificial Intelligence,2018:1145-1156.
|
| [12] |
Wu Y, Schuster M, Chen Z, et al. Google's neural machine translation system:Bridging the gap between human and machine translation[EB/OL].(2016-09-26)[2023-03-09]https://arxiv.53yu.com/abs/1609.08144.
|
| [13] |
Ba J L, Kiros J R, Hinton G E. Layer normalization[EB/OL].(2016-07-21)[2023-03-09]https://arxiv.53yu.com/abs/1607.06450. .
|
| [14] |
Zadeh A, Zellers R, Pincus E, et al. MOSI:Multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos[EB/OL].(2016-06-20)[2023-03-09]https://arxiv.53yu.com/abs/1606.06259. .
|
| [15] |
Zadeh A A B, Liang P P, Poria S, et al. Multimodal lan-guage analysis in the wild:CMU-MOSEI dataset and interpretable dynamic fusion graph[C]. Melbourne: Proceedings of the Fifty-sixth Annual Meeting of the Association for Computational Linguistics,2018:2236-2246.
|
| [16] |
Ekman P, Freisen W V, Ancoli S. Facial signs of emotional experience[J]. Journal of Personality and Social Psychology, 1980, 39(6):1125-1132.
|
| [17] |
Yang B, Wu L, Zhu J, et al. Multimodal sentiment analysis with two-phase multitask learning[J]. IEEE/ACM Transactions on Audio,Speech,and Language Processing, 2022, 30(10):2015-2024.
|
| [18] |
Degottex G, Kane J, Drugman T, et al. COVAREPA collaborative voice analysis repository for speech technologies[C]. Florence: Proceedings of IEEE International Conference on Acoustics,Speech and Signal Processing,2014:960-964.
|
| [19] |
Drugman T, Alwan A. Joint robust voicing detection and pitch estimation based on residual harmonics[EB/OL].(2019-12-28)[2023-03-10]https://arxiv.53yu.com/abs/2001.00459. .
|
| [20] |
Alku P, Bäckström T, Vilkman E. Normalized amplitude quotient for parametrization of the glottal flow[J]. Journal of the Acoustical Society of America,Acoustical Society of America, 2002, 112(2):701-710.
|
| [21] |
Kane J, Gobl C. Wavelet maxima dispersion for breathy to tense voice discrimination[J]. IEEE Transactions on Audio,Speech,and Language Processing, 2013, 21(6):1170-1179.
|
| [22] |
Pennington J, Socher R, Manning C D. GloVe:Global vectors for word representation[C]. Doha: Proceedings of the Conference on Empirical Methods in Natural Language Processing,2014:1532-1543.
|
| [23] |
Zadeh A, Chen M, Poria S, et al. Tensor fusion network for multimodal sentiment analysis[EB/OL].(2017-07-23)[2023-03-09]https://arxiv.53yu.com/abs/1707.07250.
|
| [24] |
Liu Z, Shen Y, Lakshminarasimhan V B, et al. Efficient low-rank multimodal fusion with modality-specific factors[EB/OL].(2018-05-31)[2023-03-09]https://arxiv.53yu.com/abs/1806.00064.
|
| [25] |
Tsai Y H H, Liang P P, Zadeh A, et al. Learning factorized multimodal representations[EB/OL].(2019-05-14)[2023-03-08]https://arxiv.53yu.com/abs/1806.06176.
|
| [26] |
Sun Z, Sarma P, Sethares W, et al. Learning relationshipsbetween text,audio,and video via deep canonical correlation for multimodal language analysis[C]. New York: Proceedings of the AAAI Conference on Artificial Intelligence,2020:8992-8999.
|
| [27] |
Tsai Y H H, Bai S, Liang P P, et al. Multimodal transformer for unaligned multimodal language sequences[C]. Florence: Proceedings of the Conference on Association for Computational Linguistics,2019:6558-6562.
|
| [28] |
Hazarika D, Zimmermann R, Poria S. Misa:Modality-inv-ariant and-specific representations for multimodal sentiment analysis[C]. Beijing: Proceedings of the Twenty-eighth ACM International Conference on Multimedia,2020:1122-1131.
|
| [29] |
Han W, Chen H, Poria S. Improving multimodal fusion with hierarchical mutual information maximization formultimodal sentiment analysis[EB/OL].(2021-09-16)[2023-03-09]https://arxiv.53yu.com/abs/2109.00412.
|
| [30] |
Wang Y, Shen Y, Liu Z, et al. Words can shift:Dynamically adjusting word representations using nonverbal behaviors[C]. Honolulu: Proceedings of the AAAI Conference on Artificial Intelligence,2019:7216-7223.
|
| [31] |
Chauhan D S, Akhtar M S, Ekbal A, et al. Context-aware interactive attention for multi-modal sentiment and emotion analysis[C]. Hong Kong: Proceedings of the Conference on Empirical Methods in Natural Language Processing and the Ninth International Joint Conference on Natural Language Processing,2019:5647-5657.
|