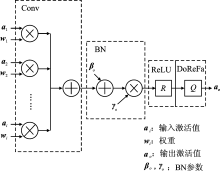
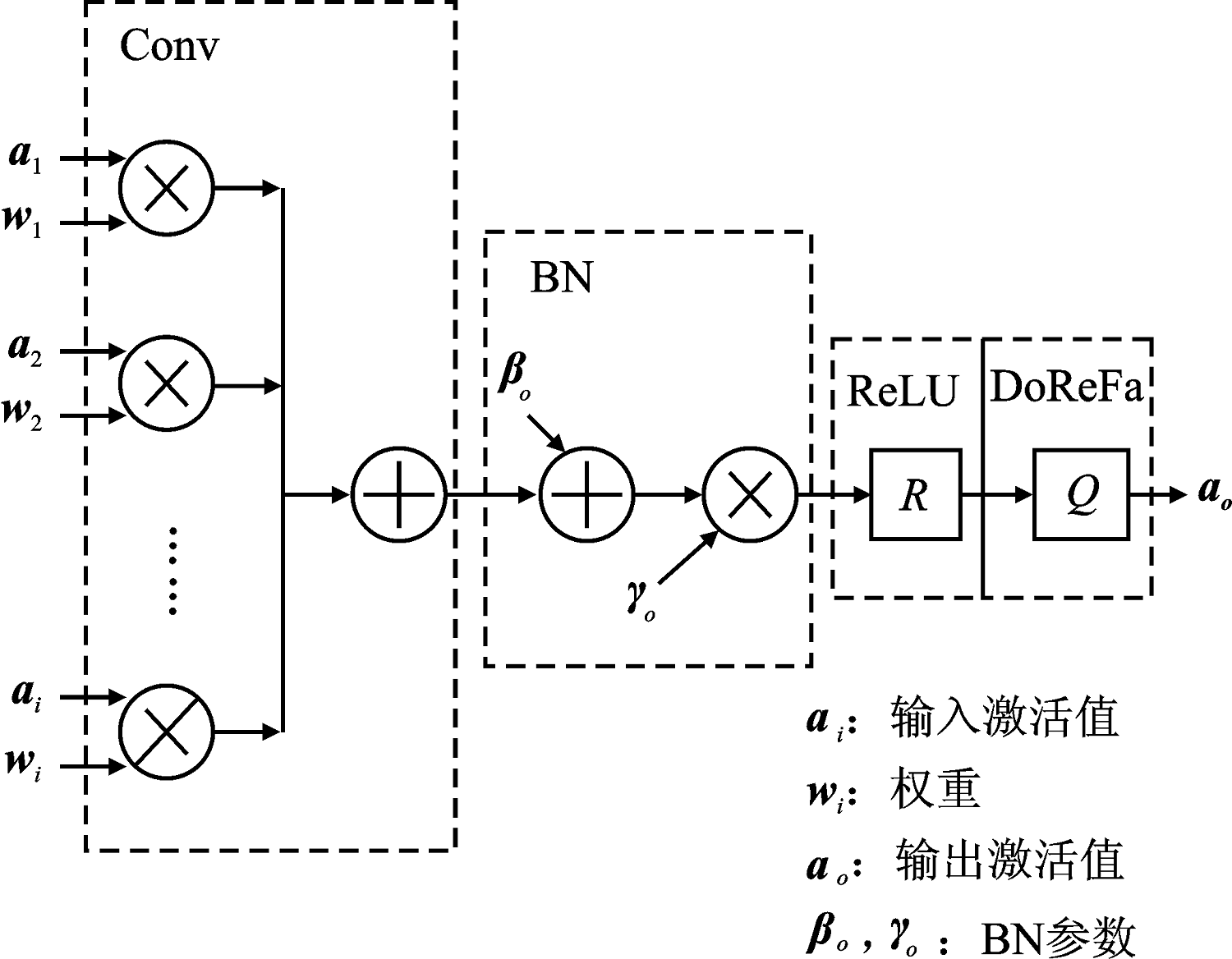
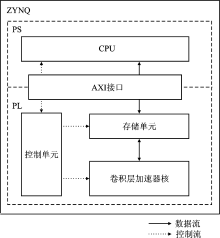
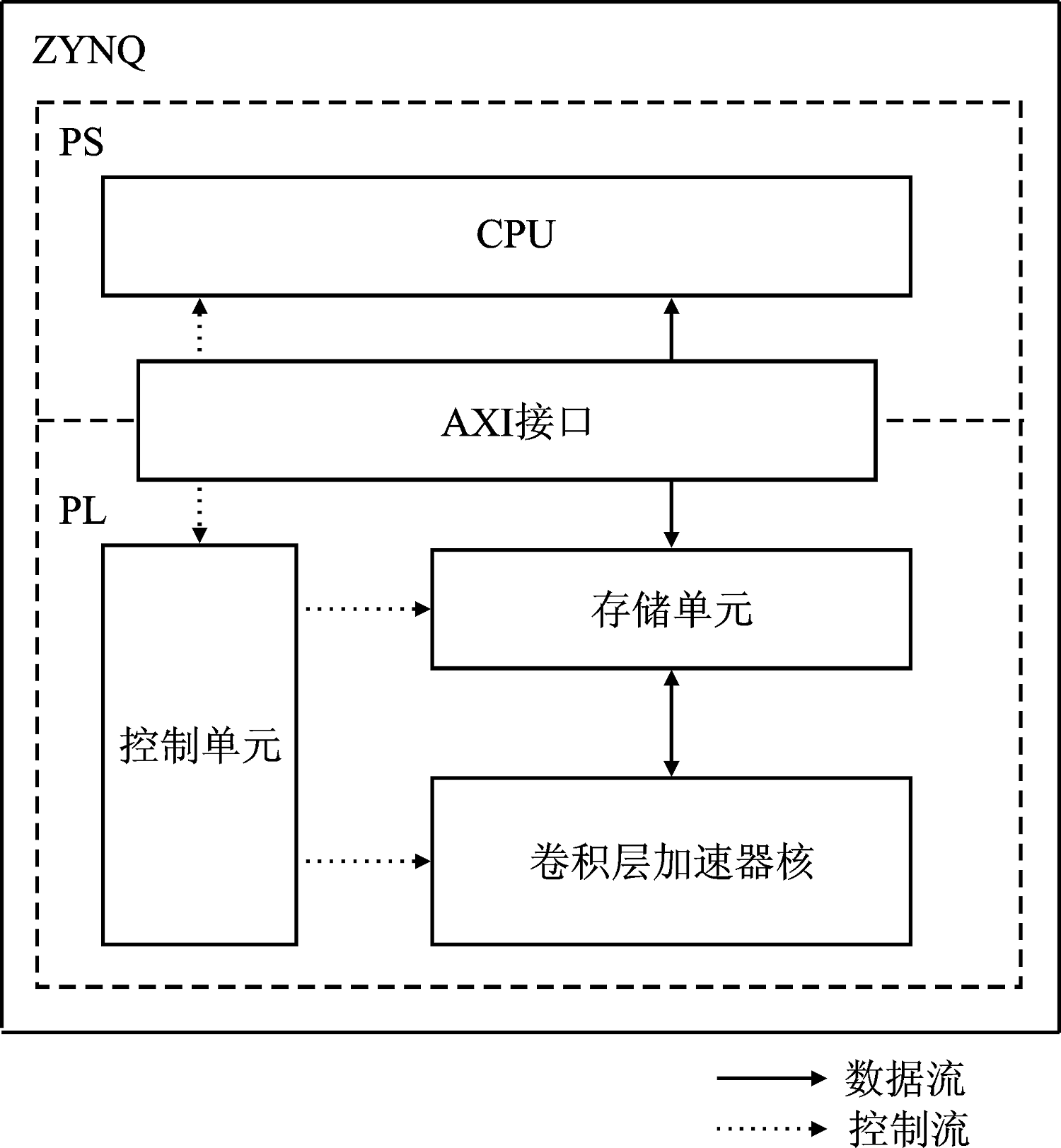
| [1] |
Li L, Bao J, Zhang T, et al. Face X-ray for more general face forgery detection[C]. Seattle: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020:5001-5010.
|
| [2] |
叶飞, 刘子龙. 基于改进YOLOv3算法的行人检测研究[J]. 电子科技, 2021, 34(1):5-9.
|
|
Ye Fei, Liu Zilong. Pedestrian detection based on improved YOLOv3 algorithm[J]. Electronic Science and Technology, 2021, 34(1):5-9.
|
| [3] |
张莹, 刘子龙, 万伟. 基于Faster R-CNN的无人机车辆目标检测[J]. 电子科技, 2021, 34(11):11-20.
|
|
Zhang Ying, Liu Zilong, Wan Wei. UAV vehicle target detection based on Faster R-CNN[J]. Electronic Science and Technology, 2021, 34(11):11-20.
|
| [4] |
梁月翔, 冯辉, 徐海祥. 基于YOLOv3-tiny的船舶可见光图像细粒度检测[J]. 武汉理工大学学报(交通科学与工程版), 2020, 44(6):1041-1051.
|
|
Liang Yuexiang, Feng Hui, Xu Haixiang. Fine-grained detection of ship visible images based on YOLOv3-tiny[J]. Journal of Wuhan Univerisity of Technology (Transportation Science & Engineering), 2020, 44(6):1041-1051.
|
| [5] |
Ren S, He K, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6):1137-1149.
|
| [6] |
Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]. Las Vegas: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016:779-788.
|
| [7] |
Jiao Z T, Zhang Y M, Mu L X, et al. A YOLOv3-based learning strategy for realtime UAV based forest fire detection[C]. Hefei: The Thirty-second Conference on Control and Decision Making in China, 2020:729-733.
|
| [8] |
Liu N, Ma X, Xu Z, et al. AutoCompress: An automatic DNN structured pruning framework for ultra-high compression rates[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(4):4876-4883.
doi: 10.1609/aaai.v34i04.5924
|
| [9] |
Wen W, Xu C, Wu C, et al. Coordinating filters for faster deep neural networks[C]. Shenzhen: IEEE International Conference on Computer Vision, 2017:658-666.
|
| [10] |
Sangil J, Changyong S, Seohyung L, et al. Learning to quantize deep networks by optimizing quantization intervals with task loss[C]. Long Beach: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019:4345-4354.
|
| [11] |
Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network[J]. Computer Science, 2015, 14(7):38-39.
|
| [12] |
Moss D J M, Leong P H W, Krishnan S, et al. A customizable matrix multiplication framework for the intel HARPv2 Xeon+FPGA platform: A deep learning case study[C]. Monterey: Proceedings of the ACM/SIGDA International Symposium, 2018:107-116.
|
| [13] |
Deng C H, Sun F X, Qian X H, et al. TIE: Energy-efficient tensor train-based inference engine for deep neural network[C]. New York: Proceedings of the Forty-sixth Annual International Symposium on Computer Architecture, 2019:264-277.
|
| [14] |
郭文旭, 苏远歧, 刘跃虎. 基于ZYNQ平台的YOLOv3压缩和加速[J]. 计算机应用, 2021, 41(3):669-676.
doi: 10.11772/j.issn.1001-9081.2020060994
|
|
Guo Wenxu, Su Yuanqi, Liu Yuehu. YOLOv3 compression and acceleration based on ZYNQ platform[J]. Journal of Computer Applications, 2021, 41(3):669-676.
doi: 10.11772/j.issn.1001-9081.2020060994
|
| [15] |
Sergey I, Christian S. Batch normalization: Accelerating deep network training by reducing internal covariate shift[C]. Lille: Proceedings of the Thirty-second International Conference on International Conference on Machine Learning, 2015:448-456.
|
| [16] |
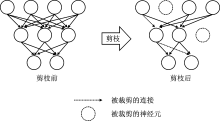
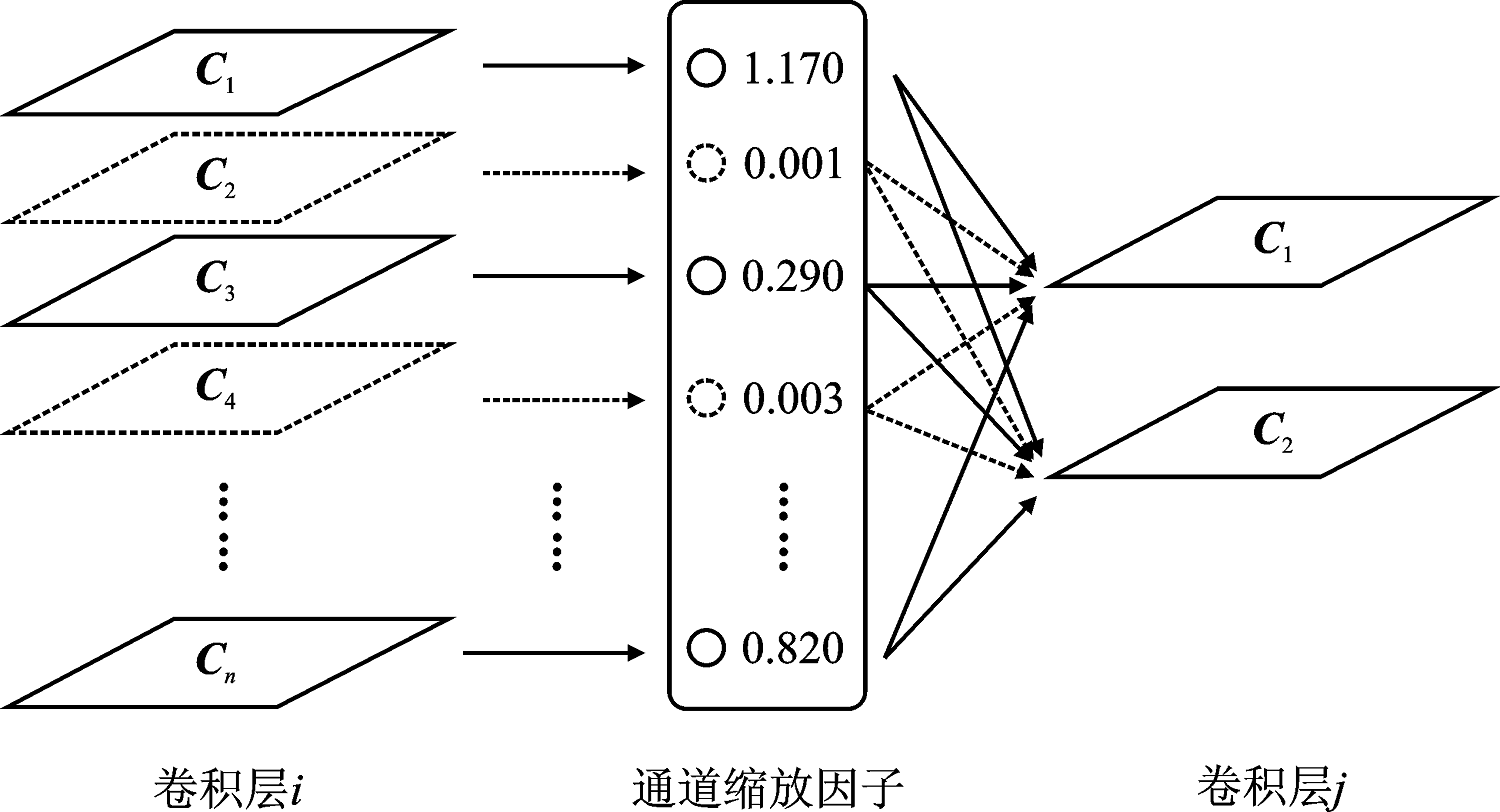
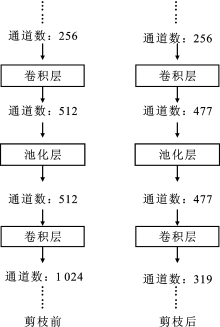
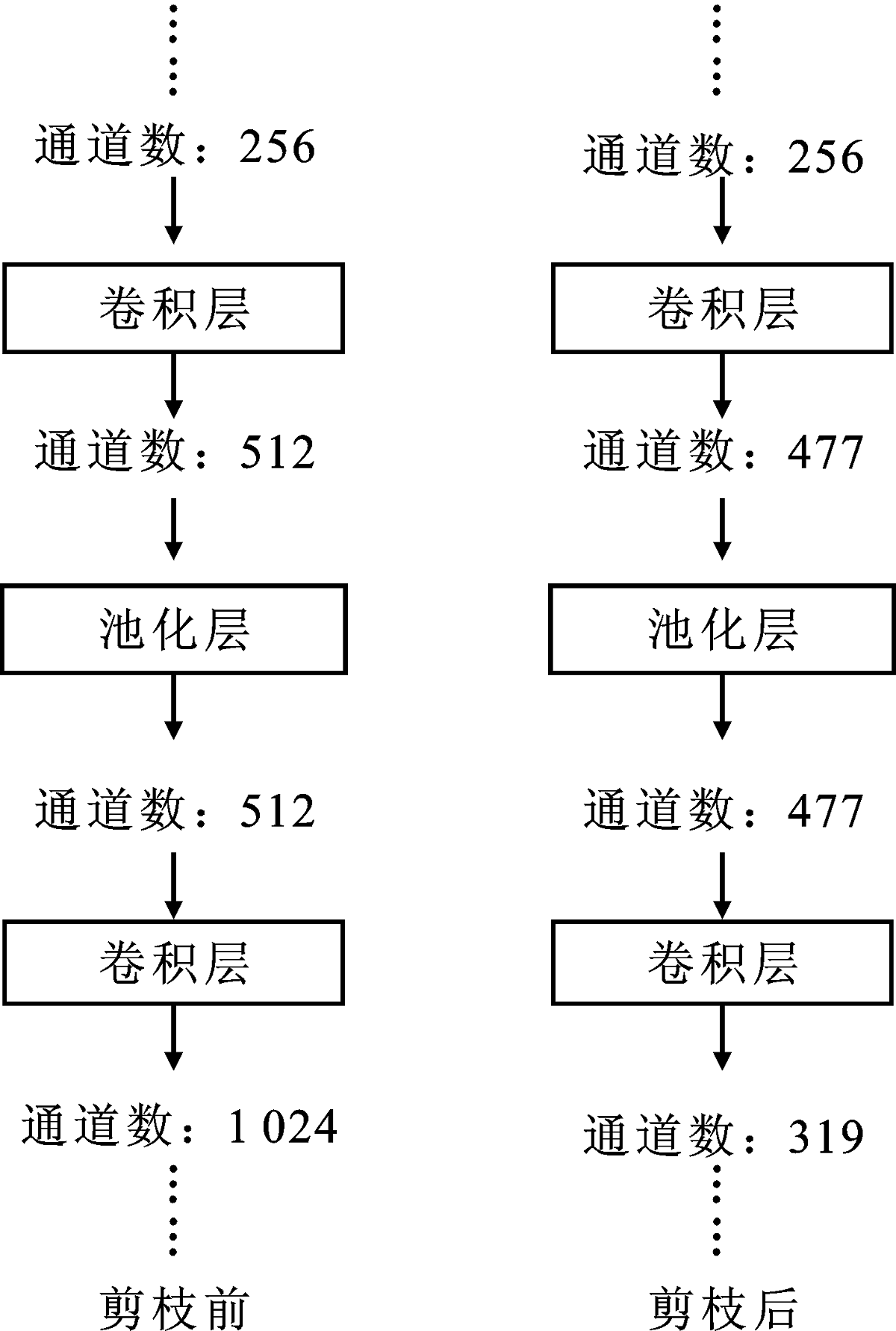
Zhuang L, Li J, Shen Z, et al. Learning efficient convolutional networks through network slimming[C]. Venice: Proceedings of the IEEE International Conference on Computer Vision, 2017: 2755-2763.
|
| [17] |
饶川, 陈靓影, 徐如意, 等. 一种基于动态量化编码的深度神经网络压缩方法[J]. 自动化学报, 2019, 45(10):1960-1968.
|
|
Rao Chuan, Chen Jingying, Xu Ruyi, et al. A dynamic quantization coding based deep neural network compression method[J]. Acta Automatica sinica, 2019, 45(10):1960-1968.
|
| [18] |
张文烨, 尚方信, 郭浩. 基于Octave卷积的混合精度神经网络量化方法[J]. 计算机应用, 2021, 41(5):1299-1304.
doi: 10.11772/j.issn.1001-9081.2020071106
|
|
Zhang Wenye, Shang Fangxin, Guo Hao. Mixed precision neural network quantization method based on Octave convolution[J]. Journal of Computer Applications, 2021, 41(5):1299-1304.
doi: 10.11772/j.issn.1001-9081.2020071106
|