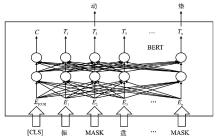
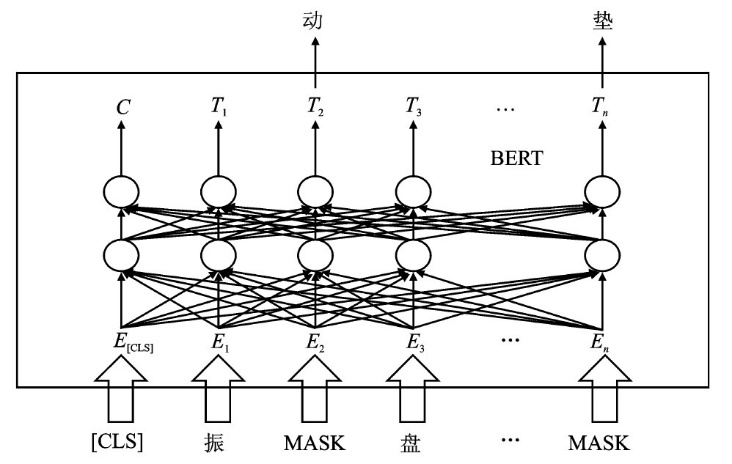
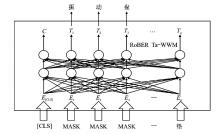
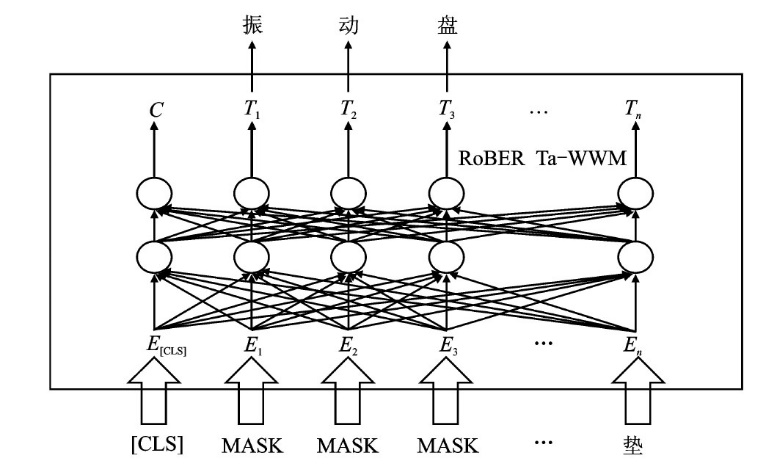
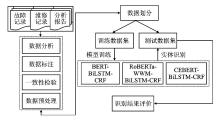
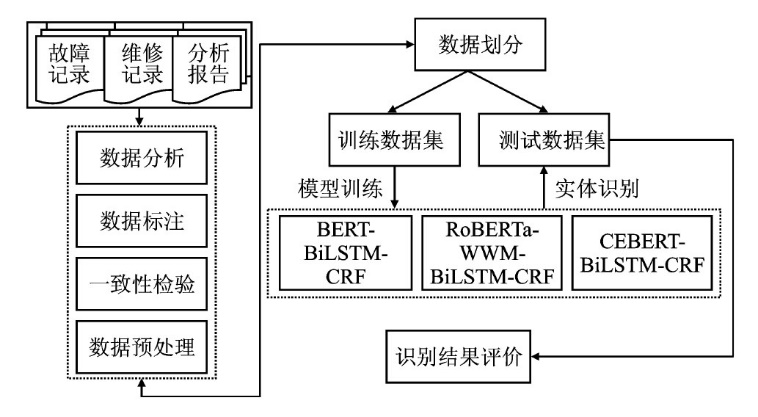
| [1] |
王骏东, 杨军, 裴洋舟, 等. 基于知识图谱的配电网故障辅助决策研究[J]. 电网技术, 2021, 45(6):2101-2112.
|
|
Wang Jundong, Yang Jun, Pei Yangzhou, et al. Distribution network fault assistant decision-making based on knowledge graph[J]. Power System Technology, 2021, 45(6):2101-2112.
|
| [2] |
Martinez-Gil J, Buchgeher G, Gabauer D, et al. Root cause analysis in the industrial domain using knowledge graphs:A case study on power transformers[J]. Procedia Computer Science, 2022, 20(8):944-953.
|
| [3] |
Zhang Y, Kang J, Dai W. Non-functional requirements e-licitation based on domain knowledge graph for automatic code generation of industrial cyber-physical systems[C]. Toronto: IECON the Forty-seventh Annual Conference of the IEEE Industrial Electronics Society,2021:1-6.
|
| [4] |
Chen X, Ouyang C, Liu Y, et al. Improving the named e-ntity recognition of Chinese electronic medical records by combining domain dictionary and rules[J]. International Journal of Environmental Research and Public Health, 2020, 17(8):2687-2703.
|
| [5] |
Feng X, Li Y, Hang Z, et al. TBR-NER:Research on CO-VID-19 text information extraction based on joint learning of topic recognition and named entity recognition[J]. Journal of Sensors, 2022, 20(22):1-15.
|
| [6] |
杨鹤, 于红, 刘巨升, 等. 基于BERT+BiLSTM+CRF深度学习模型和多元组合数据增广的渔业标准命名实体识别[J]. 大连海洋大学学报, 2021, 36(4):661-669.
|
|
Yang He, Yu Hong, Liu Jusheng, et al. Fishery standard named entity recognition based on BERT+BiLSTM+C-RF deep learning model and multivariate combined data augmentation[J]. Journal of Dalian Fisheries University, 2021, 36(4):661-669.
|
| [7] |
Ćeović H, Kurdija A S, Delać G, et al. Named entity recognition for addresses:An empirical study[J]. IEEE Access, 2022(10):42108-42120.
|
| [8] |
孟昕. 基于深度学习的法律文书识别方法研究[J]. 电子科技, 2019, 32(12):84-86.
|
|
Meng Xin. Research on recognition method of legal documents based on deep learning[J]. Electronic Science and Technology, 2019, 32(12):84-86.
|
| [9] |
Zhang H, Wang X, Liu J, et al. Chinese named entity recognition method for the finance domain based on enhanced features and pretrained language models[J]. Information Sciences, 2023, 62(5):385-400.
|
| [10] |
Brandsen A, Verberne S, Lambers K, et al. Can BERT dig it?Named entity recognition for information retrieval in the archaeology domain[J]. Journal on Computing and Cultural Heritage, 2022, 15(3):1-18.
|
| [11] |
Zheng K, Sun L, Wang X, et al. Named entity recognition in electric power metering domain based on attention mechanism[J]. IEEE Access, 2021(9):152564-152573.
|
| [12] |
Ivanin V, Artemova E, Batura T, et al. RuREBus:A case study of joint named entity recognition and relation extraction from E-government domain[C]. Skolkovo:Analysis of Images, Social Networks and Texts: The Ninth International Conference,2020:19-27.
|
| [13] |
Li J, Sun A, Han J, et al. A survey on deep learning for named entity recognition[J]. IEEE Transactions on Knowledge and Data Engineering, 2020, 34(1):50-70.
|
| [14] |
Devlin J, Chang M, Lee K, et al. BERT:Pretraining of deep bidirectional transformers for language understanding[C]. Minneapolis:Proceedings of the Seventeenth Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,2019:4171-4186.
|
| [15] |
Hochreiter S, Schmidhuber J. Long shortterm memory[J]. Neural Computation, 1997, 9(8):1735-1780.
doi: 10.1162/neco.1997.9.8.1735
pmid: 9377276
|
| [16] |
Sa'a D A A, Tawalbeh S K, Al-Smadi M, et al. Using bidirectional long short-term memory and conditional random fields for labeling Arabic named entities:A comparative study[C]. Valencia: The Fifth International Conference on Social Networks Analysis,Management and Security,2018:135-140.
|
| [17] |
Liu W, Fu X, Zhang Y, et al. Lexicon enhanced Chinese sequence labeling using BERT adapter[C]. Online: Proceedings of the Fifty-ninth Annual Meeting of the Association for Computational Linguistics and the Eleventh International Joint Conference on Natural Language Processing,2021:5847-5858.
|
| [18] |
Cui Y, Che W, Liu T, et al. Pre-training with whole word masking for Chinese BERT[J]. IEEE/ACM Transactions on Audio,Speech and Language Processing, 2021, 29(9):3504-3514.
|
| [19] |
Xue N. Chinese word segmentation as character tagging[C]. Suzhou: International Journal of Computational Linguistics & Chinese Language Processing,2003:29-48.
|