Electronic Science and Technology ›› 2024, Vol. 37 ›› Issue (7): 25-32.doi: 10.16180/j.cnki.issn1007-7820.2024.07.004
Previous Articles Next Articles
HAN Yinghao, LI Feifei
Received:2023-02-03
Online:2024-07-15
Published:2024-07-17
Supported by:CLC Number:
HAN Yinghao, LI Feifei. Scene Recognition Algorithm Based on Discriminative Patch Extraction and Two-Stage Classification[J].Electronic Science and Technology, 2024, 37(7): 25-32.
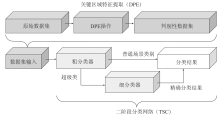
Figure 1.
DPE-TSC structure"
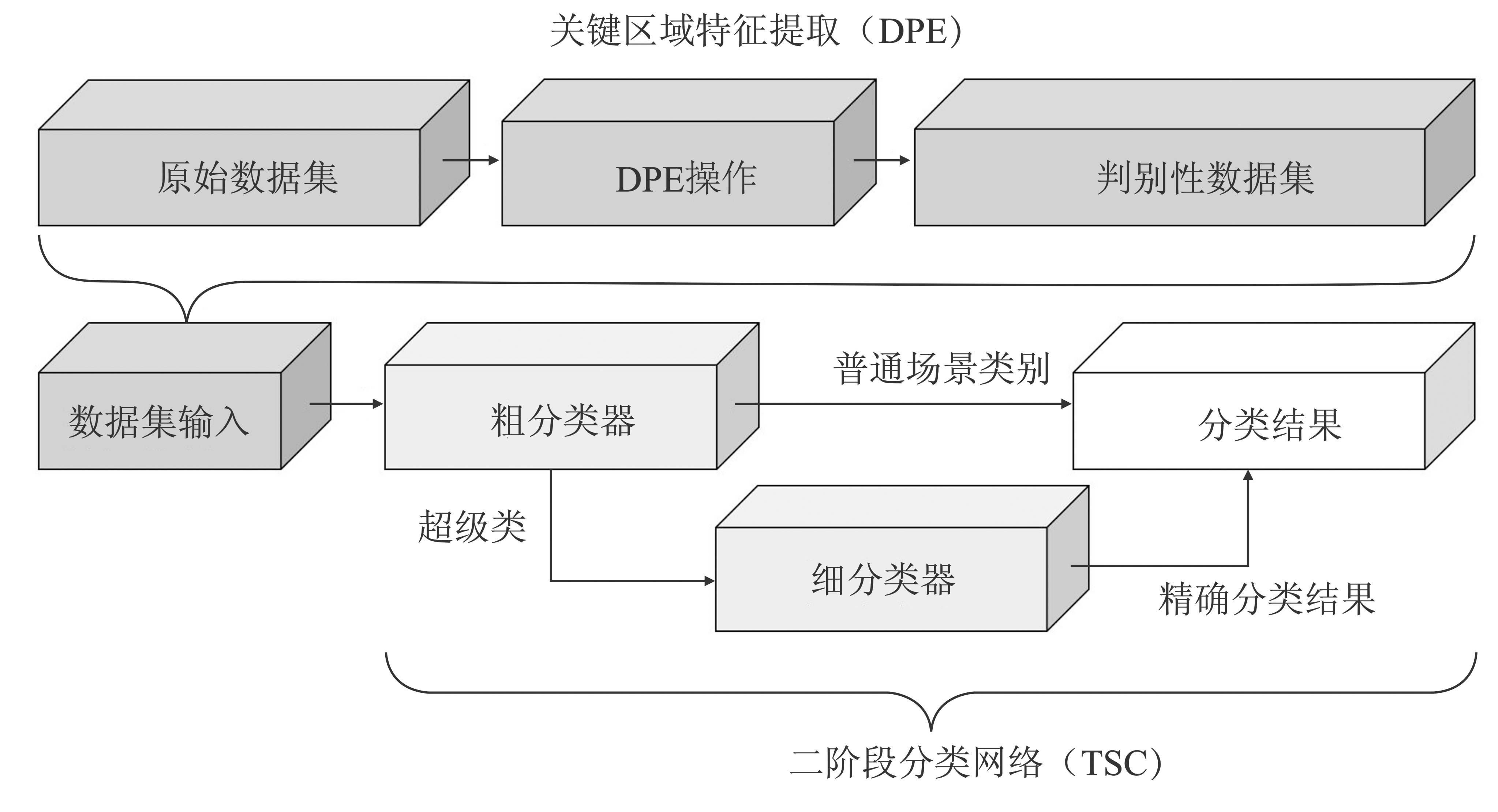

Figure 2.
Extraction of the weighted information of the key parts of the images from ResNet18"
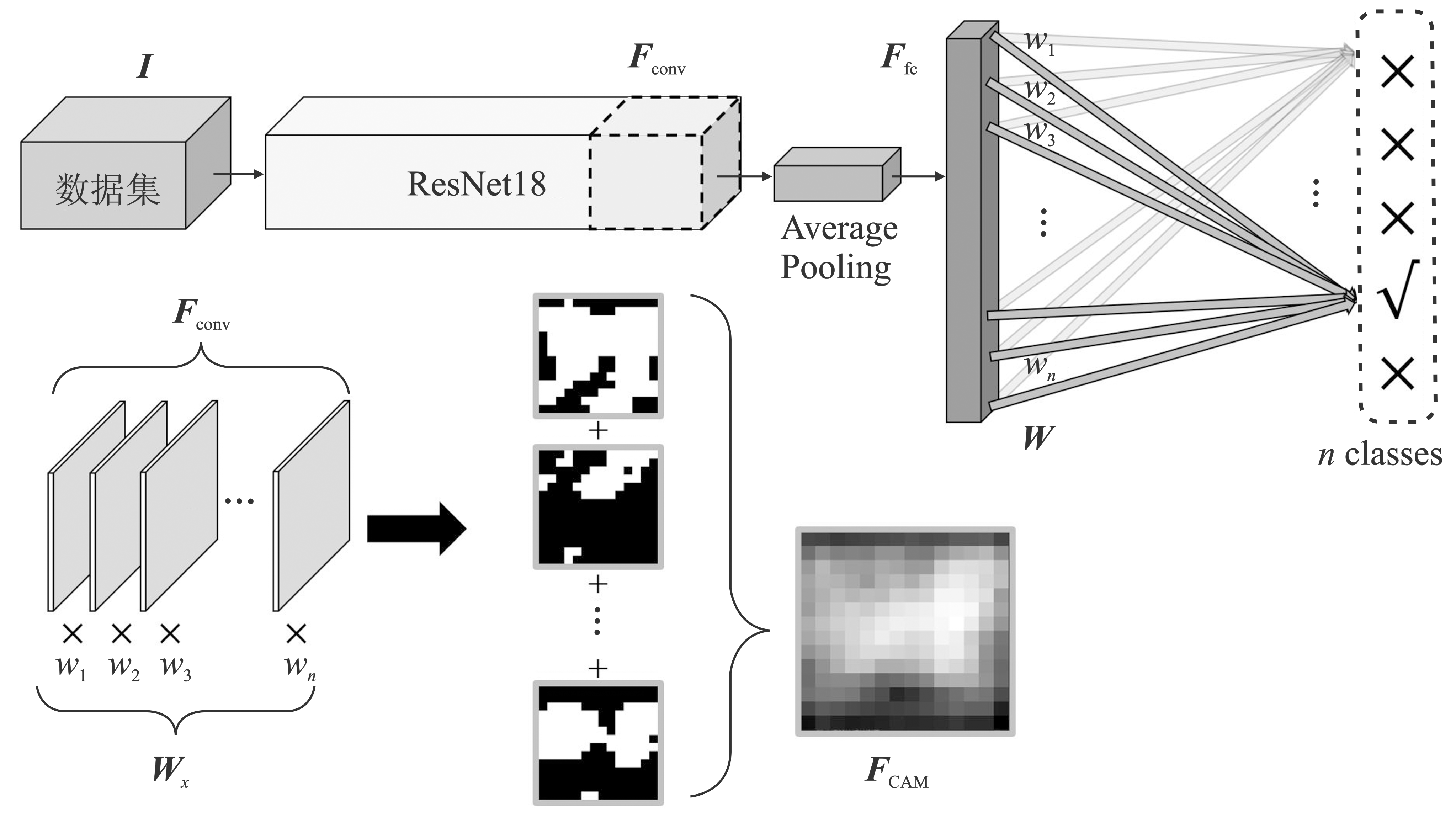
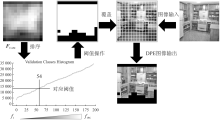
Figure 3.
The process of generating images through DPE"
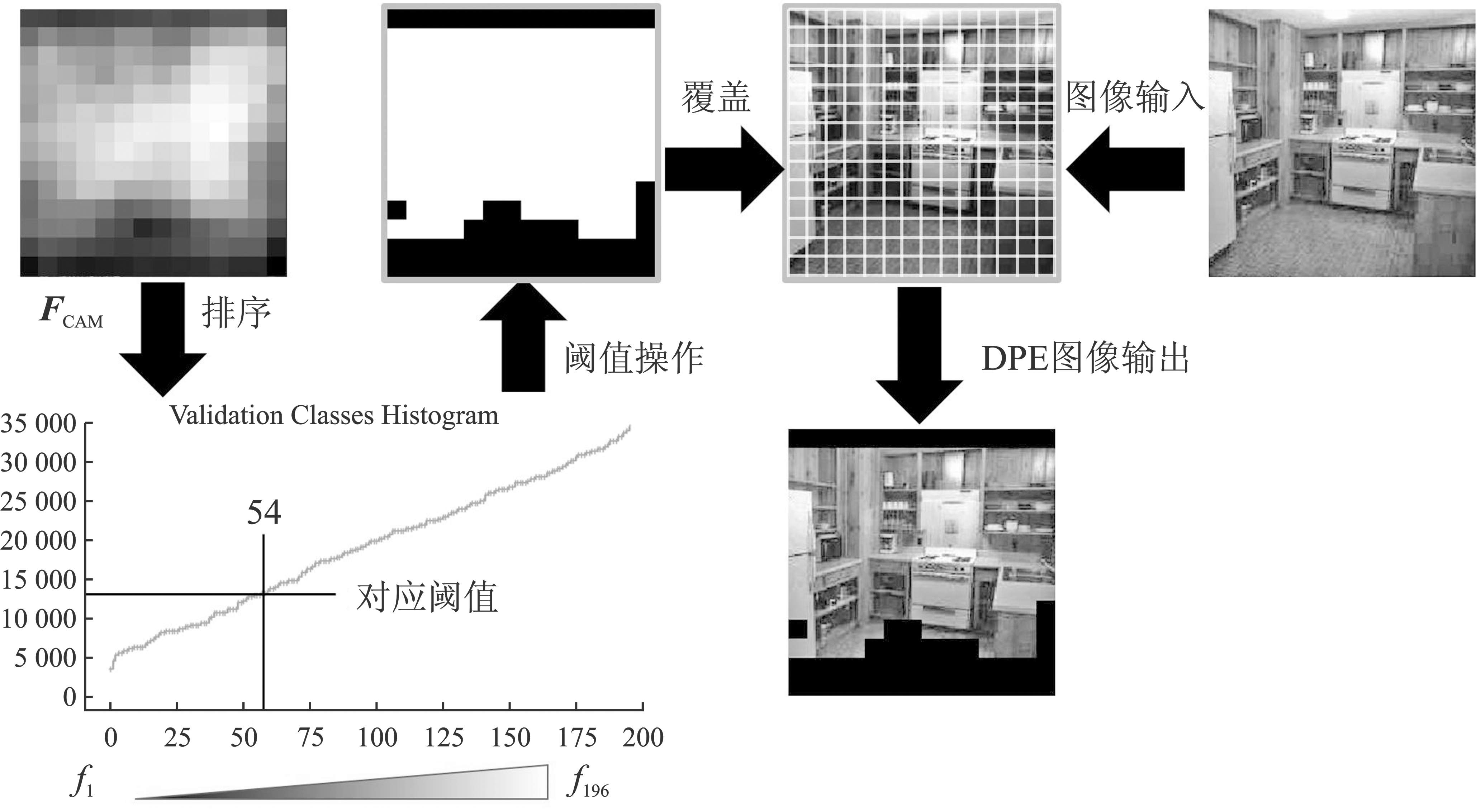
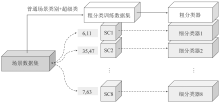
Figure 4.
The training process of two-stage classifier"
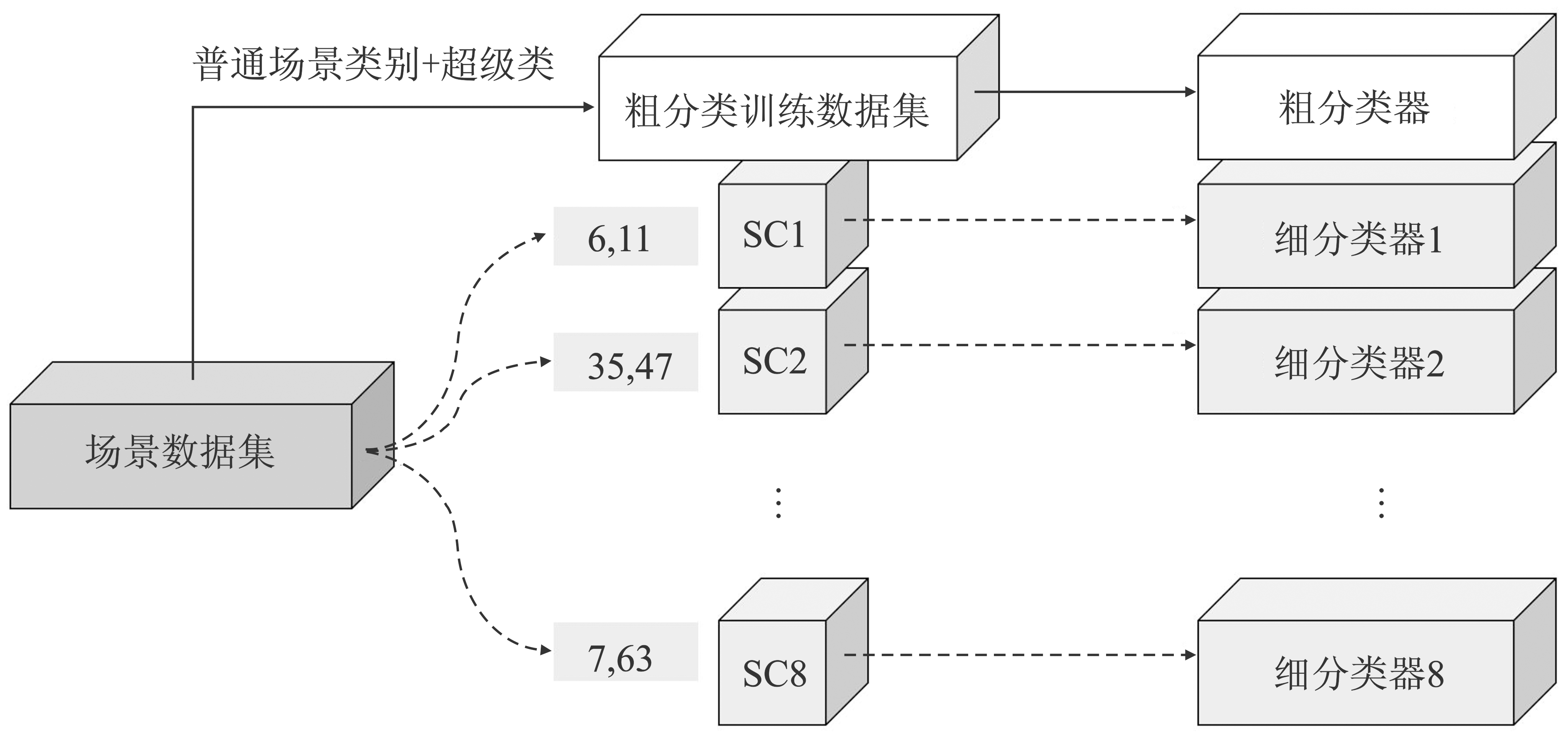
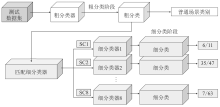
Figure 5.
The testing process of two-stage classifier"
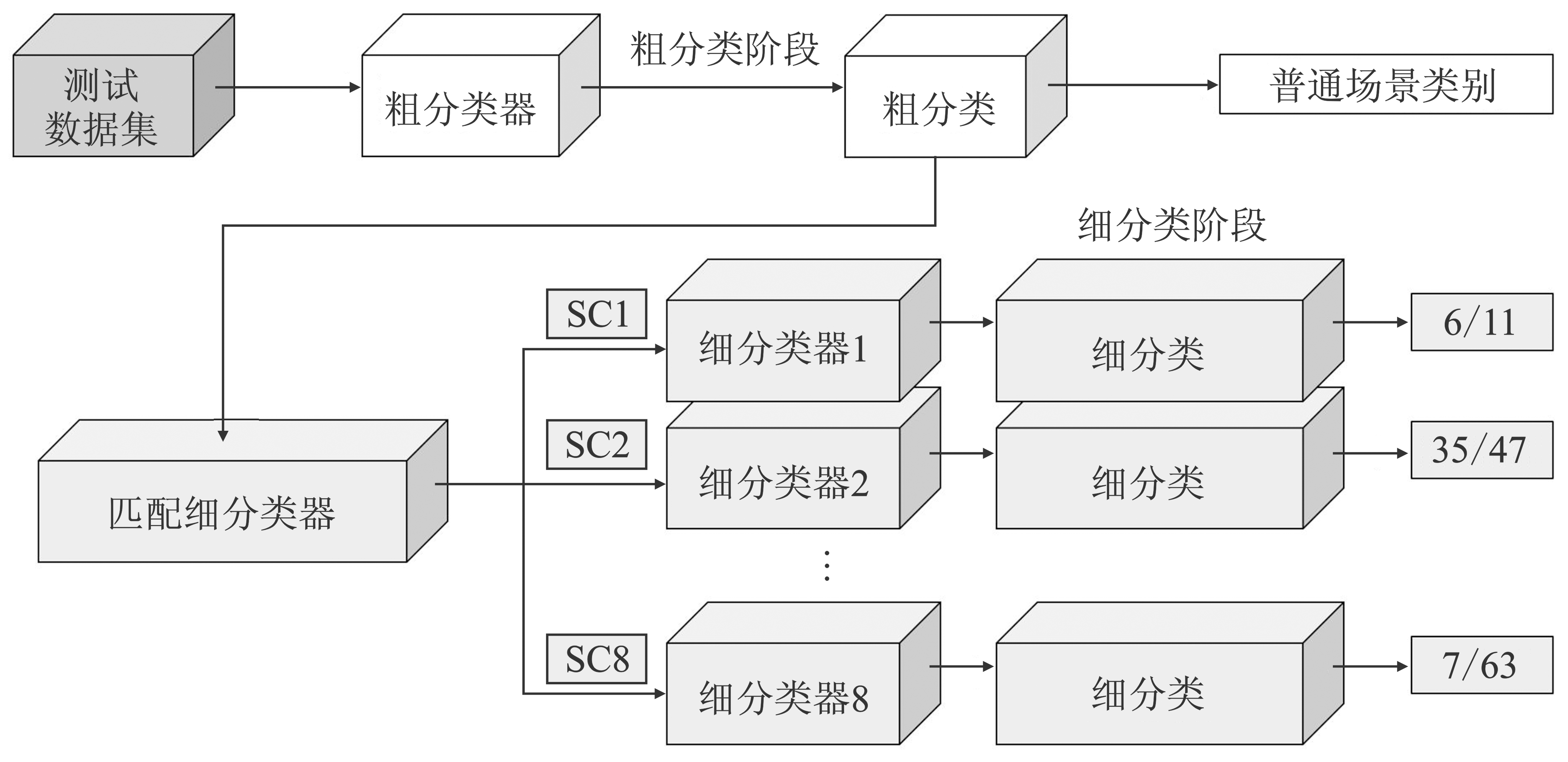
Table 1.
Accuracy comparison on MIT67 data set"
| 模型 | 准确率/% |
|---|---|
| DL-CNN[ | 86.40 |
| VSAD[ | 86.10 |
| G-MS2F[ | 79.60 |
| FTOTLM[ | 74.60 |
| SDO[ | 86.80 |
| LGN[ | 88.10 |
| MR CNN[ | 86.70 |
| ARG[ | 88.13 |
| Scene Essence[ | 83.92 |
| SaSR[ | 86.10 |
| ViT[ | 84.20 |
| DPE+TSC SaSR (本文) | 86.70 |
| DPE+TSC ViT (本文) | 88.40 |
Table 2.
Accuracy comparison on SUN397 data set"
| 模型 | 准确率/% |
|---|---|
| DL-CNN[ | 70.1 |
| VSAD[ | 72.0 |
| G-MS2F[ | 64.1 |
| FTOTLM[ | 65.5 |
| SDO[ | 73.4 |
| LGN[ | 74.1 |
| MR CNN[ | 72.0 |
| ARG[ | 75.0 |
| Scene Essence[ | 68.3 |
| SaSR[ | 74.0 |
| ViT[ | 75.0 |
| DPE+TSC SaSR(本文) | 74.7 |
| DPE+TSC ViT (本文) | 76.0 |
Table 3.
Accuracy comparison on Scene15 data set"
| 模型 | 准确率/% |
|---|---|
| HOG + SPM 3[ | 88.3 |
| DL-CNN[ | 96.0 |
| NNSD[ | 94.7 |
| G-MS2F[ | 93.2 |
| FTOTLM[ | 94.0 |
| SDO[ | 95.9 |
| S2ICA[ | 93.1 |
| DAG CNN[ | 92.9 |
| Multi-Scale Space VLAD[ | 94.7 |
| CKSL[ | 94.4 |
| VAED[ | 88.1 |
| ViT[ | 94.7 |
| DPE+ViT (本文) | 96.4 |
| DPE+TSC ViT (本文) | 96.9 |
Table 4.
Accuracy comparison on Places365 data set"
| 模型 | 准确率/% |
|---|---|
| LGN[ | 56.5 |
| EMFS[ | 54.3 |
| SaSR[ | 56.5 |
| Scene Essence[ | 55.2 |
| MAE[ | 60.3 |
| Places365-VGG[ | 55.2 |
| Places365- ResNet50[ | 54.7 |
| DPE+ResNet50 (本文) | 54.9 |
| DPE+TSC ResNet50 (本文) | 55.1 |
| DPE+ViT (本文) | 58.5 |
| DPE+TSC ViT (本文) | 60.5 |
Table 5.
Ablation experiment"
| 基线网络 (“√”表示选择该网络) | 消融模块 (“√”表示引入该模块) | 准确度/% | ||||||
|---|---|---|---|---|---|---|---|---|
| ResNet50 | SaSR | ViT | DPE | TSC | Scene15 | MIT 67 | SUN397 | Places365 |
| √ | - | - | - | - | 92.1 | 84.0 | 70.8 | 54.7 |
| √ | - | - | √ | - | 93.7 | 84.7 | 71.1 | 54.9 |
| √ | - | - | - | √ | 94.1 | 84.9 | 71.8 | 54.9 |
| √ | - | - | √ | √ | 94.6 | 85.5 | 72.3 | 55.1 |
| - | √ | - | - | - | 94.2 | 86.1 | 73.9 | 56.5 |
| - | √ | - | √ | - | 94.6 | 86.4 | 74.1 | 56.6 |
| - | √ | - | - | √ | 95.1 | 86.5 | 74.4 | 56.9 |
| - | √ | - | √ | √ | 95.5 | 86.7 | 74.7 | 57.2 |
| - | - | √ | - | - | 94.7 | 84.2 | 75.0 | 57.7 |
| - | - | √ | √ | 96.2 | 87.5 | 75.8 | 58.5 | |
| - | - | √ | - | √ | 96.4 | 88.0 | 75.8 | 59.1 |
| - | - | √ | √ | √ | 96.9 | 88.4 | 76.0 | 60.5 |
| [1] | Simonyan K, Zisserman A. Very deep convolutional networks for largescale image recognition[EB/OL].(2015-04-15) [2023-02-02] https://arxiv.org/pdf/1409.1556v4.pdf. |
| [2] | Ioffe S, Szegedy C. Batch normalization:Accelerating deep network training by reducing internal covariate shift[C]. Guangzhou: Proceedings of the Thirty-second International Conference on International Conference on Machine Learning, 2015:448-456. |
| [3] | He K, Zhang X, Ren S, et al. Deep residual learning forimage recognition[C]. Las Vegas: IEEE Conference on Computer Vision and Pattern Recognition, 2016:770-778. |
| [4] | Deng J, Dong W, Socher R, et al. Imagenet:A large-scale hierarchical image database[C]. Miami: IEEE Conference on Computer Vision and Pattern Recognition, 2009:248-255. |
| [5] | Zhou B Lapedriza A, Khosla A, et al. Places:A 10 million image database for scene recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40(6):1452-1464. |
| [6] | Liu Y, Chen Q, Chen W, et al. Dictionary learning inspired deep network for scene recognition[C]. New Orleans: AAAI Conference on Artificial Intelligence, 2018:7178-7185. |
| [7] | Yang S, Ramanan D. Multi-scale recognition with DAG-CNNs[C]. Santiago: IEEE International Conference on Computer Vision, 2015:1215-1223. |
| [8] | Liu S, Tian G, Xu Y. A novel scene classification model combining ResNet based transfer learning and dataaugmentation with a filter[J]. Neurocomputing, 2019, 33(8):191-206. |
| [9] | Cheng X, Lu J, Feng J, et al. Scene recognition with objectness[J]. Pattern Recognition, 2018, 74(2):474-487. |
| [10] | Chen G, Song X, Zeng H, et al. Scene recognition with prototype-agnostic scene layout[J]. IEEE Transactions on Image Processing, 2020, 29(1):5877-5888. |
| [11] | Seong H, Hyun J, Kim E. Fosnet:An end-to-end trainable deep neural network for scene recognition[J]. IEEE Access, 2020(8):82066-82077. |
| [12] | López-Cifuentes A, Escudero-Vinolo M, Bescós J, et al. Semantic-aware scene recognition[J]. Pattern Recognition, 2020, 10(2):107256-107262. |
| [13] | Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16×16 words:Transformers for image recognition at scale[EB/OL].(2021-06-03) [2023-02-03] https://arxiv.org/abs/2010.11929. |
| [14] |
Wang Z, Wang L, Wang Y, et al. Weakly supervised pat-chnets:Describing and aggregating local patches for scene recognition[J]. IEEE Transactions on Image Processing, 2017, 26(4):2028-2041.
doi: 10.1109/TIP.2017.2666739 pmid: 28207394 |
| [15] | Tang P, Wang H, Kwong S. G-MS2F:Goog LeNet based multistage feature fusion of deep CNN for scene recognition[J]. Neurocomputing, 2017, 22(5):188-197. |
| [16] | Wang L, Guo S, Huang W, et al. Knowledge guided disambiguation for largescale scene classification with multi-resolution CNNs[J]. IEEE Transactions on Image Processing, 2017, 26(4):2055-2068. |
| [17] | Zeng H, Song X, Chen G, et al. Amorphous region context modeling for scene recognition[J]. IEEE Transactions on Multimedia, 2020, 24(9):141-151. |
| [18] | Qiu J, Yang Y, Wang X, et al. Scene essence[C]. Online: IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021:8322-8333. |
| [19] | 谢林, 李菲菲, 陈虬. 基于稀疏自动编码机的场景识别算法[J]. 电子科技, 2019, 32(1):38-41. |
| Xie Lin, Li Feifei, Chen Qiu. Scene recognition algorithm based on sparse autoencoder[J]. Electronic Science and Technology, 2019, 32(1):38-41. | |
| [20] | Xie L, Lee F, Liu L, et al. Hierarchical coding of convolutional features for scene recognition[J]. IEEE Transactions on Multimedia, 2019, 22(5):1182-1192. |
| [21] | Hayat M, Khan S H, Bennamoun M, et al. A spatial layout and scale invariant feature representation for indoor scene classification[J]. IEEE Transactions on Image Processing, 2016, 25(10):4829-4841. |
| [22] | 缪冉, 李菲菲, 陈虬. 基于卷积神经网络与多尺度空间编码的场景识别方法[J]. 电子科技, 2020, 33(12):1-7. |
| Miao Ran, Li Feifei, Chen Qiu. Scene recognition algorithm based on convolutional neural networks and multi-scale space encoding[J]. Electronic Science and Technology, 2020, 33(12):1-7. | |
| [23] | Shao X, Zhang J, Bao B K, et al. Automatic scene recognition based on constructed knowledge space learning[J]. IEEE Access, 2019(7):102902-102910. |
| [24] | Lim K L, Jiang X, Yi C. Deep clustering with variational autoencoder[J]. IEEE Signal Processing Letters, 2020, 27(2):231-235. |
| [25] | Song X, Jiang S, Herranz L. Multiscale multi-feature context modeling for scene recognition in the semantic manifold[J]. IEEE Transactions on Image Processing, 2017, 26(6):2721-2735. |
| [26] | He K, Chen X, Xie S, et al. Masked autoencoders are scalable vision learners[C]. New Orleans: IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022:15979-15988. |
| [1] | PANG Jiangfei, SUN Zhanquan. Multi-Encoder Transformer for End-to-End Speech Recognition [J]. Electronic Science and Technology, 2024, 37(4): 1-7. |
| [2] | Bin ,WANG Sen. Visual Detection of Structural Cracks Using Depth Deformable Contour ModelLAI [J]. Electronic Science and Technology, 2023, 36(9): 35-40. |
| [3] | TANG Zenan,MIAO Xiaodan,YANG Jian,YUAN Tianchen. Research on Low Mach Number Transitional Cavity Jet Noise Reduction of High-Speed Train Pantograph [J]. Electronic Science and Technology, 2023, 36(4): 29-35. |
| [4] | CHENG Changwen,CHEN Wei,CHEN Jinhong,YIN Zhong. YOLO-Improve Detection Method of Real-Time Mask Wearing [J]. Electronic Science and Technology, 2023, 36(2): 73-80. |
| [5] | HU Tao,JIANG Quan. PID Parameter Tuning Based on Improved Honey Badger Optimization Algorithm [J]. Electronic Science and Technology, 2023, 36(12): 46-54. |
| [6] | WANG Qiao,HU Chunyan,LI Feifei. Scene Recognition Algorithm Based on Deep Transfer Learning and Multi-Scale Feature Fusion [J]. Electronic Science and Technology, 2023, 36(11): 19-27. |
| [7] | LIU Yongpan,WANG Ran. Minimum Cost of Heterogeneous Directional Sensor Networks for Target Coverage [J]. Electronic Science and Technology, 2022, 35(7): 14-21. |
| [8] | TONG Xiaosen,YANG Jinxian. Drilling Tool Acceleration Denoising Based on GRNN Network Adaptive Filtering [J]. Electronic Science and Technology, 2022, 35(7): 46-51. |
| [9] | SUN Kang,XUAN Xuyang,LIU Penghui,ZHAO Laijun,LONG Jie. Partial Discharge Pattern Recognition of Cable Based on CNN-DCGAN under Small Data [J]. Electronic Science and Technology, 2022, 35(7): 7-13. |
| [10] | SHI Tian,XU Junjie,SUN Shuangyuan,YIN Mingjun,YANG Jun,YIN Zhiping. Electrically Tunable Terahertz Metamaterial Absorber Based on Liquid Crystal [J]. Electronic Science and Technology, 2022, 35(6): 43-47. |
| [11] | Jianpeng WAN,Hongmin LU,Guohua LIU,Min LI. EMI Margin Assessment of Vehicular Communication System [J]. Electronic Science and Technology, 2022, 35(4): 1-7. |
| [12] | Chaowei LIN,Feifei LI,Qiu CHEN. Globaland Local Scene Representation Method Based on Deep Convolutional Features [J]. Electronic Science and Technology, 2022, 35(4): 20-27. |
| [13] | DUAN Jundong,HUANG Hongye,WANG Shuaiqiang. EV Clustering Optimization Community Load Strategy Based on Flexible Optimization Mechanism [J]. Electronic Science and Technology, 2022, 35(12): 64-71. |
| [14] | WANG Wen,LU Hongmin,ZHANG Guangshuo,CHEN Chongchong,ZHANG Shiwei. Quantitative Analysis and Evaluation of the Disturbance Degree of Vehicle-Mounted VHF Radio [J]. Electronic Science and Technology, 2022, 35(11): 1-6. |
| [15] | JIN Tao,HU Xia,YU Lanlan,ZHAO Wenjun,YANG Qi,TUO Ya. Progress in Electrocatalysis Oxygen Reduction for Hydrogen Peroxide Production over Single-Atom Catalysts [J]. Electronic Science and Technology, 2022, 35(11): 90-97. |
|
||
