Electronic Science and Technology ›› 2024, Vol. 37 ›› Issue (4): 1-7.doi: 10.16180/j.cnki.issn1007-7820.2024.04.001
PANG Jiangfei, SUN Zhanquan
Received:2022-10-31
Online:2024-04-15
Published:2024-04-19
Supported by:CLC Number:
PANG Jiangfei, SUN Zhanquan. Multi-Encoder Transformer for End-to-End Speech Recognition[J].Electronic Science and Technology, 2024, 37(4): 1-7.
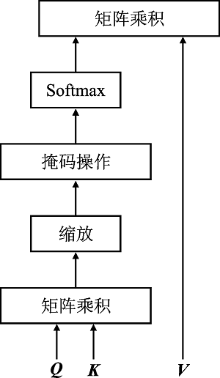
Figure 1.
Scaled dot-product attention"
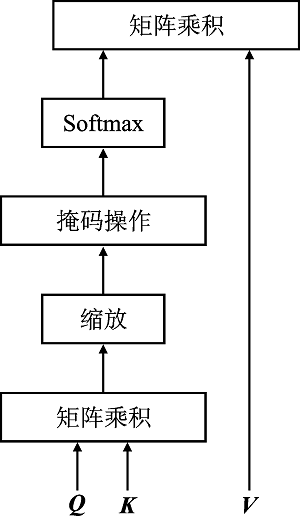

Figure 2.
Multi-head attention"
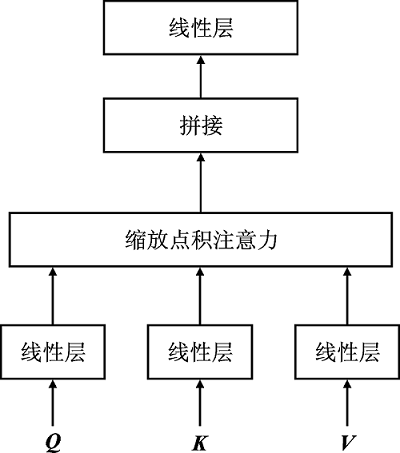

Figure 3.
MET encoder model architecture"
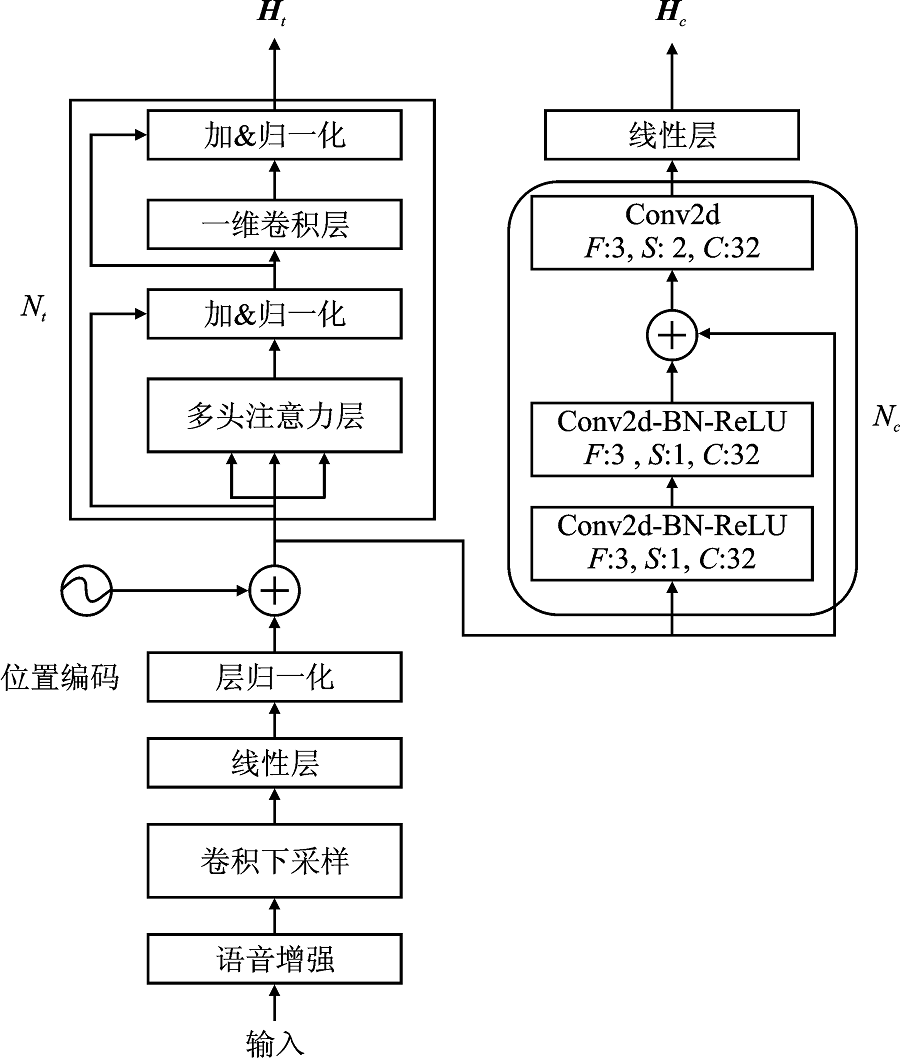
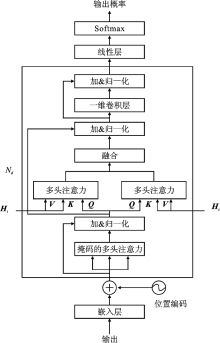
Figure 4.
MET decoder model architecture"
Table 1.
CER of different transformer-based models on the Aishell-1 data set"
| 模型 | 验证集字符错误率/% | 测试集字符错误率/% |
|---|---|---|
| STBD[ | 5.80 | 6.64 |
| LFMMI[ | 6.44 | 7.62 |
| ESPnet(Transformer)[ | 6.00 | 6.70 |
| LDS-REG[ | 9.43 | 10.56 |
| Sync-Transformer[ | 7.91 | 8.91 |
| SSAN[ | - | 6.84 |
| AGS[ | 7.00 | 7.94 |
| Multi-QuartzNet[ | - | 6.77 |
| LAS[ | - | 10.56 |
| ST[ | 7.93 | 8.36 |
| Transformer(本文) | 5.68 | 6.18 |
| MET | 5.54 | 5.93 |
Table 2.
Results on internal Shanghainese dialect data set"
| 模型 | 测试集上的字符错误率/% |
|---|---|
| Transformer(本文) | 19.92 |
| MET | 10.31 |
Figure 5.
Training loss on inner Shanghainese dialect data set"
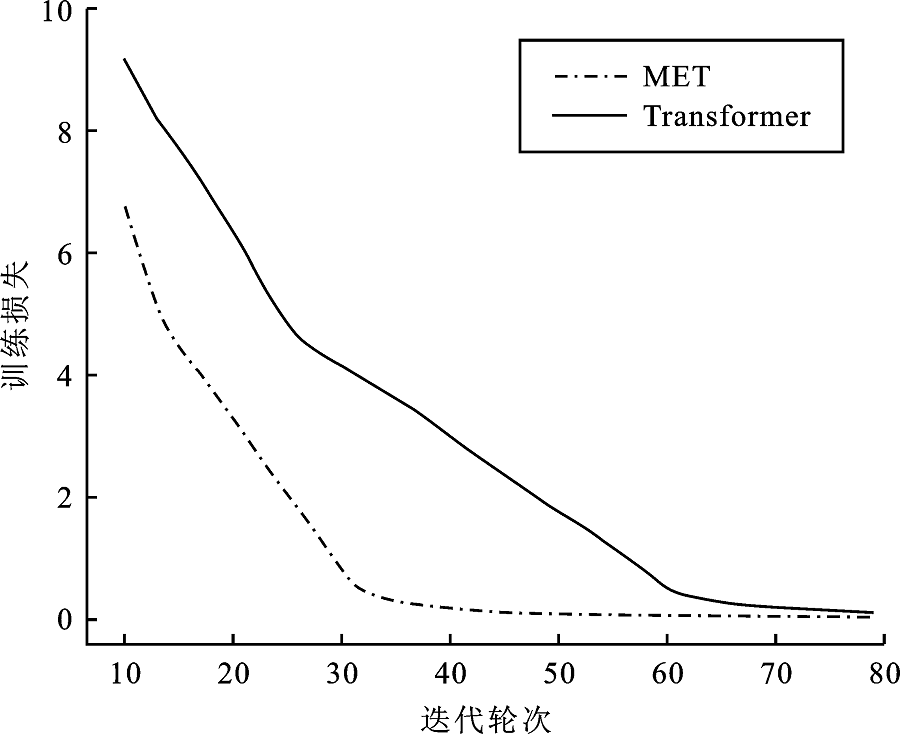
Table 3.
Results of different layers of convolution encoder branch"
| 卷积分支层数 | 测试集上的字符错误率/% |
|---|---|
| 1 | 6.16 |
| 2 | 6.01 |
| 3 | 5.93 |
| 4 | 6.13 |
Table 4.
Results of cross validation"
| 交叉验证批次 | 测试集上的字符错误率/% |
|---|---|
| 第1次 | 11.21 |
| 第2次 | 10.19 |
| 第3次 | 10.47 |
| 平均 | 10.62 |
| [1] |
Rabiner L R. A tutorial on hidden Markov models and selected applications in speech recognition[J]. Proceedings of the IEEE, 1989, 77(2):257-286.
doi: 10.1109/5.18626 |
| [2] | 刘庆峰, 江源, 胡亚军, 等. 基于听感量化编码的神经网络语音合成方法研究[J]. 电子科技, 2019, 32(9):76-79. |
| Liu Qingfeng, Jiang Yuan, Hu Yajun, et al. Research on perception quantification-based neural speech synthesis methods[J]. Electronic Science and Technology, 2019, 32(9):76-79. | |
| [3] | Graves A, Fernández S, Gomez F, et al. Connectionist temporal classification:Labelling unsegmented sequence data with recurrent neural networks[C]. Pittsburgh: Proceedings of the Twenty-third International Conference on Machine Learning, 2006:529-537. |
| [4] | He Y, Sainath T N, Prabhavalkar R, et al. Streaming end-to-end speech recognition for mobile devices[C]. Brig-hton: IEEE International Conference on Acoustics,Speech and Signal Processing, 2019:653-659. |
| [5] | Li B, Chang S, Sainath T N, et al. Towards fast and accurate streaming end-to-end ASR[C]. Barcelona: IEEE International Conference on Acoustics,Speech and Signal Processing, 2020:311-320. |
| [6] | Li S, Dabre R, Lu X, et al. Improving Transformer-based speech recognition systems with compressed structure and speech attributes augmentation[C]. Graz: Proceedings of the Annual Conference of the International Speech Communication Association, 2019:295-303. |
| [7] | Chan W, Jaitly N, Le Q, et al. Listen,attend and spell:A neural network for large vocabulary conversational speech recognition[C]. Shanghai: IEEE International Conference on Acoustics,Speech and Signal Processing, 2016:389-396. |
| [8] | Dong L, Xu S, Xu B. Speech-Transformer:A no-recurre-nce sequence-to-sequence model for speech recognition[C]. Calgary: IEEE International Conference on Acoustics,Speech and Signal Processing, 2018:601-608. |
| [9] | Chen X, Zhang S, Song D, et al. Transformer with bidirectional decoder for speech recognition[C]. Shanghai: Proceedings of the Annual Conference of the International Speech Communication Association, 2020:498-503. |
| [10] | Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]. Long Beach: Advances in Neural Information Processing Systems, 2017:353-361. |
| [11] | Zhou S, Dong L, Xu S, et al. Syllable-based sequence-to-sequence speech recognition with the Transformer in Mandarin Chinese[C]. Hyderabad: Proceedings of the Annual Conference of the International Speech Communication Association, 2018:263-270. |
| [12] | Miao H, Cheng G, Gao C, et al. Transformer-based online CTC/attention end-to-end speech recognition architecture[C]. Barcelona: IEEE International Conference on Acoustics,Speech and Signal Processing, 2020:193-201. |
| [13] | Huang W, Hu W, Yeung Y T, et al. Conv-Transformer tr-ansducer:Low latency,low frame rate,streamable end- to-end speech recognition[C]. Shanghai: Proceedings of the Annual Conference of the International Speech Communication Association, 2020:933-942. |
| [14] | Gulati A, Qin J, Chiu C C, et al. Conformer:Convolution-augmented Transformer for speech recognition[C]. Shanghai: Proceedings of the Annual Conference of the International Speech Communication Association, 2020:801-807. |
| [15] | Lohrenz T, Li Z, Fingscheidt T. Multi-encoder learning and stream fusion for Transformer-based end-to-end automatic speech recognition[C]. Brno: Proceedings of the Annual Conference of the International Speech Communication Association, 2021:711-719. |
| [16] | Bu H, Du J, Na X, et al. Aishell-1:An open-source Mandarin speech corpus and a speech recognition baseline[C]. Seoul: The Twentyth Conference of the Oriental Chapter of the International Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment, 2017:821-827. |
| [17] | He K, Zhang X, Ren S, et al. Deep residual learning forimage recognition[C]. Las Vegas: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016:542-540. |
| [18] | Park D S, Chan W, Zhang Y, et al. Specaugment:A simple data augmentation method for automatic speech recognition[C]. Graz: Proceedings of the Annual Conference of the International Speech Communication Association, 2019:632-638. |
| [19] | Karita S, Chen N, Hayashi T, et al. A comparative study on Transformer vs rnn in speech applications[C]. Singapore: IEEE Automatic Speech Recognition and Understanding Workshop, 2019:578-583. |
| [20] | Guo P, Boyer F, Chang X, et al. Recent developments on ESPnet toolkit boosted by conformer[C]. Toronto: IEEE International Conference on Acoustics,Speech and Signal Processing, 2021:55-60. |
| [21] |
Sun S, Guo P, Xie L, et al. Adversarial regularization for attention based end-to-end robust speech recognition[J]. IEEE/ACM Transactions on Audio,Speech,and Language Processing, 2019, 27(11):1826-1838.
doi: 10.1109/TASLP.6570655 |
| [22] | Tian Z, Yi J, Bai Y, et al. Synchronous Transformers for end-to-end speech recognition[C]. Barcelona: IEEE International Conference on Acoustics,Speech and Signal Processing, 2020:1250-1258. |
| [23] | Luo H, Zhang S, Lei M, et al. Simplified self-attention for Transformer-based end-to-end speech recognition[C]. Shenzhen: IEEE Spoken Language Technology Workshop, 2021:988-995. |
| [24] | Ding F, Guo W, Dai L, et al. Attention-based gated scaling adaptive acoustic model for CTC-based speech recognition[C]. Barcelona: IEEE International Conferenceon Acoustics,Speech and Signal Processing, 2020:555-560. |
| [25] | Luo J, Wang J, Cheng N, et al. Multi-quartznet:Multi-resolution convolution for speech recognition with multilayer feature fusion[C]. Shenzhen: IEEE Spoken Language Technology Workshop, 2021:1128-1135. |
| [26] | Shan C, Weng C, Wang G, et al. Component fusion:Learning replaceable language model component for end- to-end speech recognition system[C]. Brighton: IEEE International Conference on Acoustics,Speech and Signal Processing, 2019:89-95. |
| [27] | Fan Z, Li J, Zhou S, et al. Speaker-aware speech-Transf-ormer[C]. Singapore: IEEE Automatic Speech Recognition and Understanding Workshop, 2019:801-812. |
| [1] | LIANG Chenye, ZHANG Xuanxiong. Research on Multiclass Garbage Classification Algorithm Based on Improved MobileNet Network [J]. Electronic Science and Technology, 2024, 37(4): 38-46. |
| [2] | YU Tao, RAO Junfeng. Simulation Study on Pulse Width Superposition of Solid-State LTD [J]. Electronic Science and Technology, 2024, 37(4): 47-54. |
| [3] | QIN Xiaofei, HE Wen, BAN Dongxian, GUO Hongyu, YU Jing. Research on Fast 3D Hand Keypoint Detection Algorithm Based on Anchor [J]. Electronic Science and Technology, 2024, 37(4): 77-86. |
| [4] | NIE Chunfang, HAO Zhenghang, CHEN Zhuo, HE Puxiang. Research on Electromagnetic Transient Acceleration Simulation Technoloy of New-Type Power System [J]. Electronic Science and Technology, 2024, 37(3): 18-25. |
| [5] | YAN Yaling, WANG Luoguo, YAN Rui, WU Ming. Research on An Improved Closed Loop Decoding Algorithm [J]. Electronic Science and Technology, 2024, 37(3): 26-33. |
| [6] | MA Wenjie, ZHANG Xuanxiong. Research on Blind Roads and Obstacle Recognition Algorithm Based on Deep Learning [J]. Electronic Science and Technology, 2024, 37(3): 75-83. |
| [7] | TIAN Zhixin,XU Zhen,MAO Jian,LIN Binbin,LIAO Wei. Classification Method of Steel Surface Defects Based on Multi-Scale Feature Fusion [J]. Electronic Science and Technology, 2024, 37(2): 87-95. |
| [8] | FU Yizhao,LI Zi. Marx Pulse Source with Multistage Resonant Charging [J]. Electronic Science and Technology, 2024, 37(1): 9-16. |
| [9] | DANG Xiaofang,CAI Xingyu. Transformer-Based Maneuvering Target Tracking [J]. Electronic Science and Technology, 2023, 36(9): 86-92. |
| [10] | ZHA Junwei,ZHANG Hongyan. Dynamic Receptive Field Feature Selection Dehazing Network [J]. Electronic Science and Technology, 2023, 36(7): 56-63. |
| [11] | CUI Zhuodong,CHEN Wei,YIN Zhong. Helmet Wearing Detection Based on Enhanced Feature Fusion Network [J]. Electronic Science and Technology, 2023, 36(4): 44-51. |
| [12] | TONG Zhaojing,QIAO Zhengrui,LI Jinxiang,LAN Mengyue,JING Lifei. Research on Transformer Fault Diagnosis Based on Improved Sparrow Search Algorithm Optimization BN [J]. Electronic Science and Technology, 2023, 36(4): 52-58. |
| [13] | WANG Xuyang,YI Yingping,LI Tianfeng. A Convolutional Neural Network Optimization Method for Fault Diagnosis of Power Transformer [J]. Electronic Science and Technology, 2023, 36(12): 79-86. |
| [14] | WANG Qiao,HU Chunyan,LI Feifei. Scene Recognition Algorithm Based on Deep Transfer Learning and Multi-Scale Feature Fusion [J]. Electronic Science and Technology, 2023, 36(11): 19-27. |
| [15] | QIAN Dingdong,SONG Ke,WANG Wei. Research on Internal Positioning of Transformer Partial Discharge Ultrasound Based on Whale Algorithm [J]. Electronic Science and Technology, 2023, 36(11): 41-46. |
|
||
