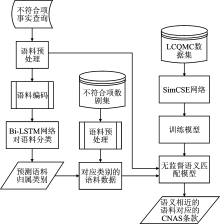
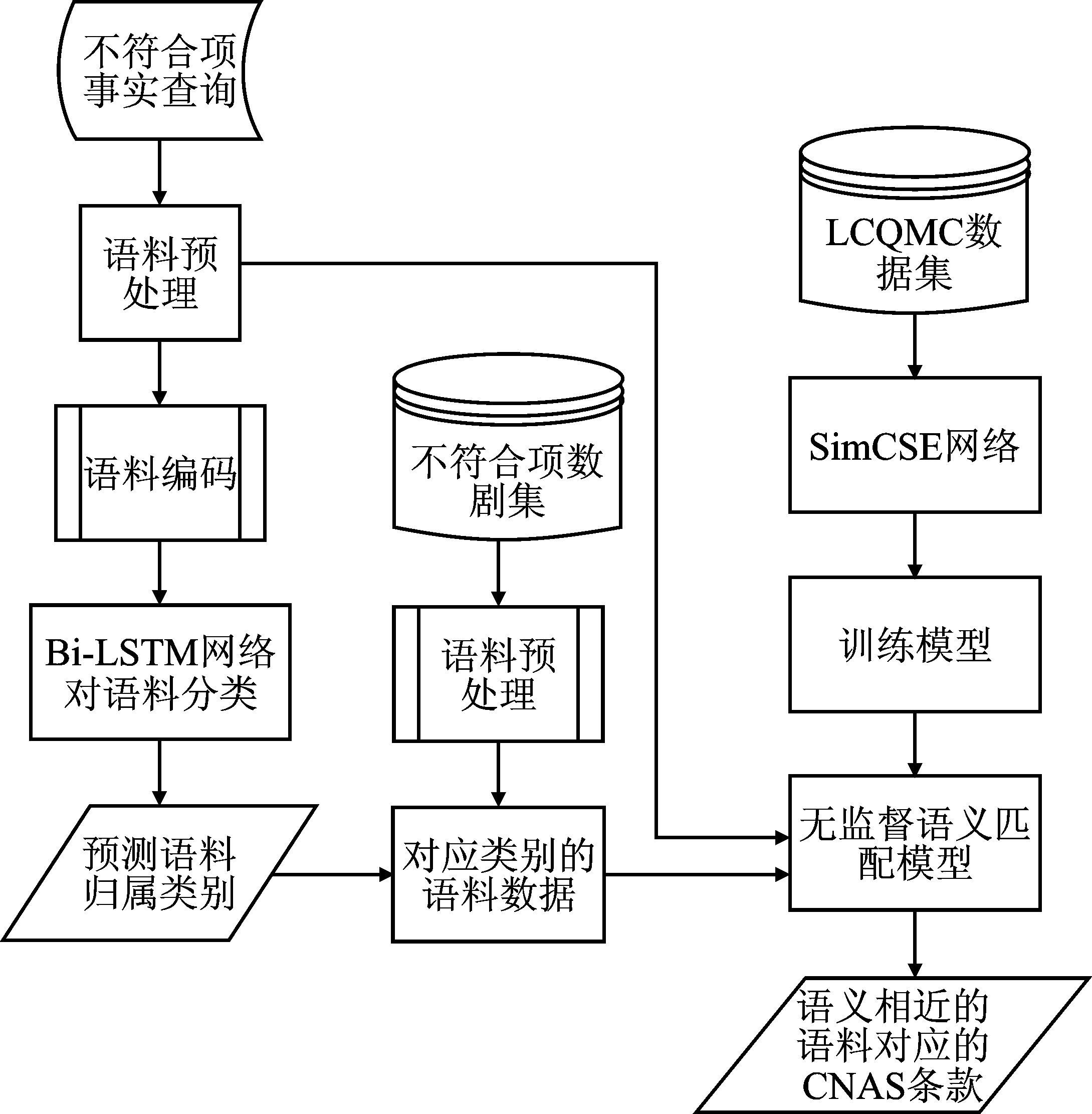
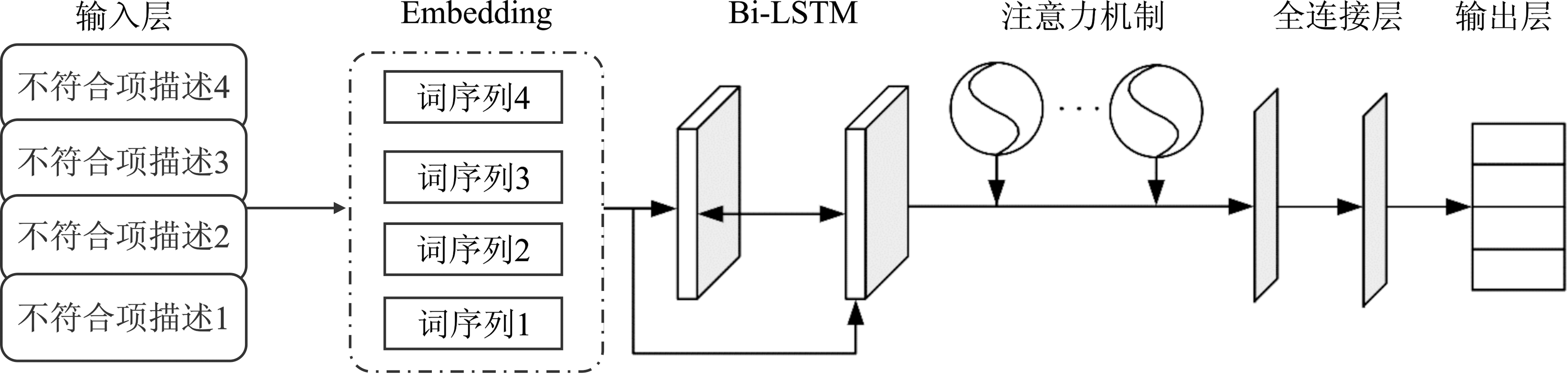
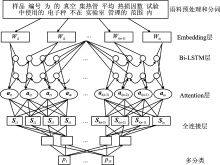
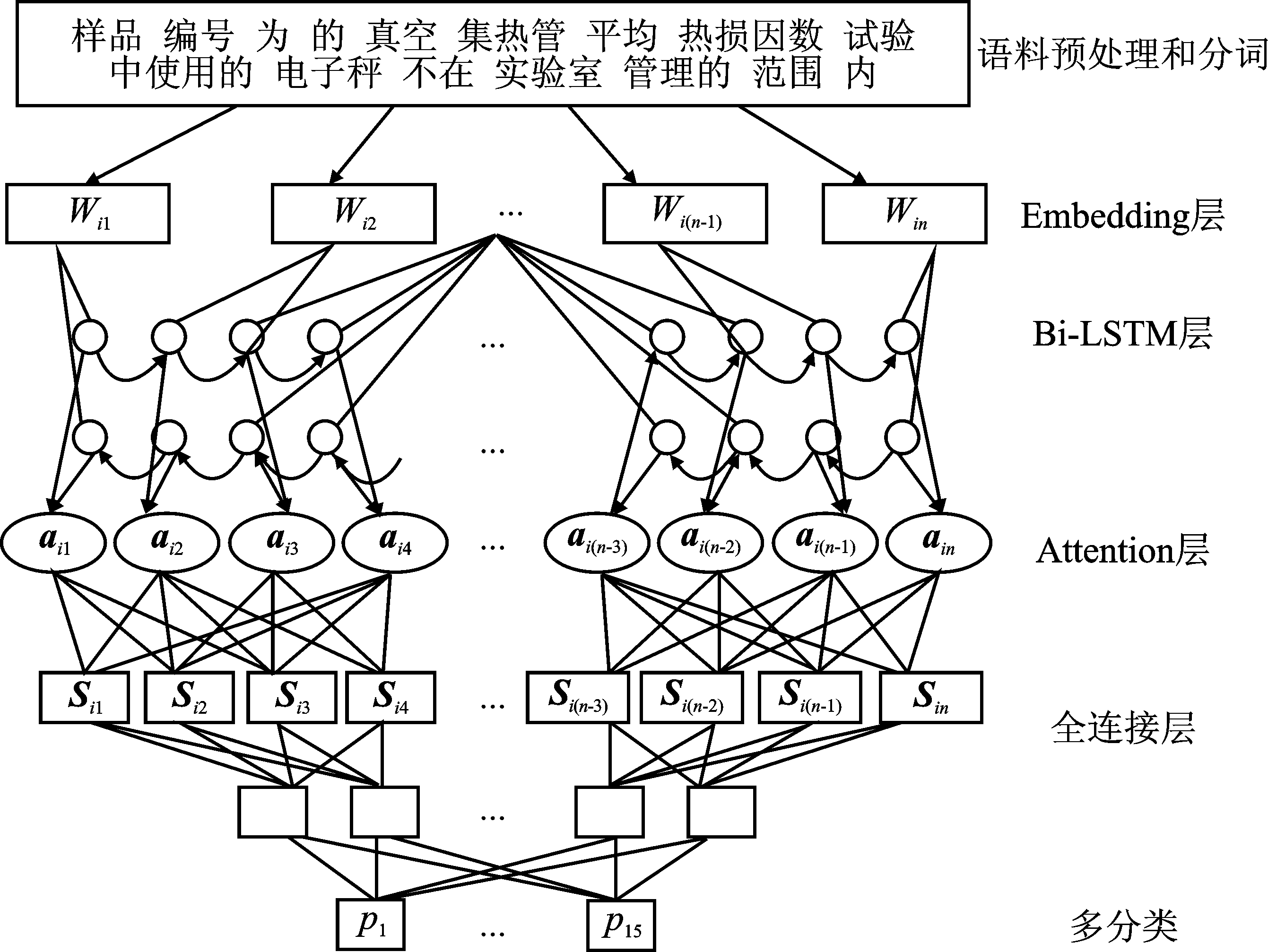
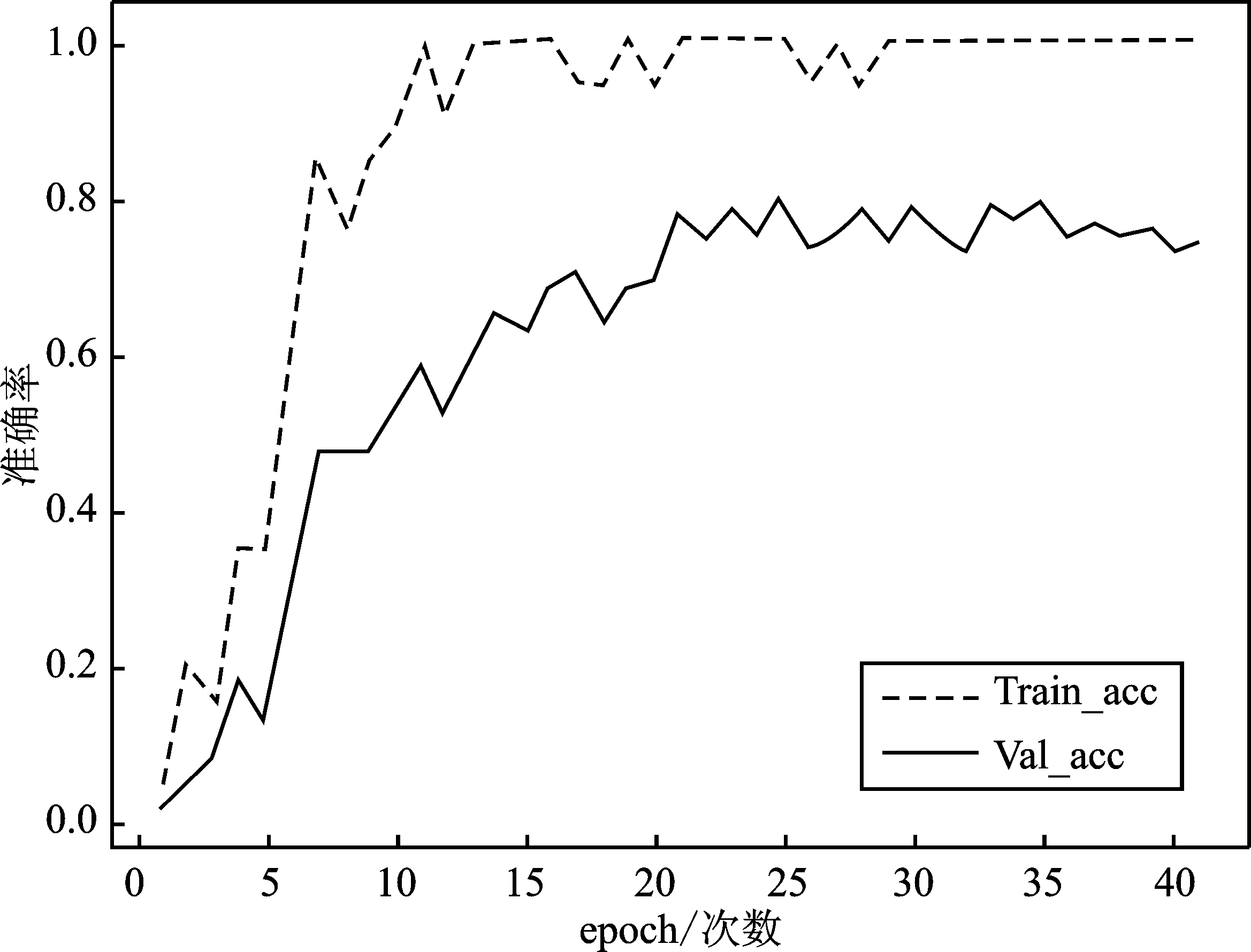
| [1] |
中国合格评定国家认可委员会.ISO/IEC17025:2018. 检测和校准实验室能力认可准则[S]. 北京: 中国标准出版社,2019.
|
|
China National Accreditation Commission for Conformity Assessment.ISO/IEC17025:2018. Accreditation criteria for the competence of testing and calibration laboratories[S]. Beijing: Standards Press of China,2019.
|
| [2] |
中国合格评定国家认可委员会.ISO/IEC17025:2020. 认可标识使用和认可状态声明规则[S]. 北京: 中国标准出版社,2020.
|
|
China National Accreditation Commission for Conformity Assessment.ISO/IEC17025:2020. Rules for use of approval marks and declaration of approval status[S]. Beijing: Standards Press of China,2020.
|
| [3] |
中国合格评定国家认可委员会.ISO/IEC17025:2018. 公正性和保密规则[S]. 北京: 中国标准出版社,2018.
|
|
China National Accreditation Commission for Conformity Assessment.ISO/IEC17025:2018. Fairness and confidentiality rules[S]. Beijing: Standards Press of China,2018.
|
| [4] |
中国合格评定国家认可委员会.ISO/IEC17025: 2019.申诉、 投诉和争议处理规则[S]. 北京: 中国标准出版社,2019.
|
|
China National Accreditation Commission for Conformity Assessment.ISO/IEC17025:2019. Rules for handling complaints, complaints and disputes[S]. Beijing: Standards Press of China,2019.
|
| [5] |
中国合格评定国家认可委员会.ISO/IEC 17025:2019. 实验室认可规则[S]. 北京: 中国标准出版社,2020.
|
|
China National Accreditation Commission for Conformity Assessment.ISO/IEC 17025:2019. Laboratory accreditation rules[S]. Beijing: Standards Press of China,2020.
|
| [6] |
郝超, 裘杭萍, 孙毅, 等. 多标签文本分类研究进展[J]. 计算机工程与应用, 2021, 57(10):48-56.
doi: 10.3778/j.issn.1002-8331.2101-0096
|
|
Hao Chao, Qiu Hangping, Sun Yi, et al. Research progress of multi-label text classification[J]. Computer Engineering and Applications, 2021, 57(10):48-56.
doi: 10.3778/j.issn.1002-8331.2101-0096
|
| [7] |
武永亮, 赵书良, 李长镜, 等. 基于TF-IDF和余弦相似度的文本分类方法[J]. 中文信息学报, 2017, 31(5):138-145.
|
|
Wu Yongliang, Zhao Shuliang, Li Changjing, et al. Text classification method based on TF-IDF and cosine similarity[J]. Journal of Chinese Information Technology, 2017, 31(5):138-145.
|
| [8] |
Li X, Liu N, Yao C, et al. Text similarity measurement with semantic analysis[J]. International Journal of Innovative Computing Information & Control, 2017, 13(5):1693-1708.
|
| [9] |
卢佳伟, 陈玮, 尹钟. 融合TextRank算法的中文短文本相似度计算[J]. 电子科技, 2020, 33(10):51-56.
|
|
Lu Jiawei, Chen Wei, Yin Zhong. Chinese short text similarity calculation based on textrank algorithm[J]. Electronic Science and Technology, 2020, 33(10):51-56.
|
| [10] |
Chen G L, Shi X L, Chen M K. Text similarity semantic calculation based on deep reinforcement learning[J]. International Journal of Security and Networks, 2020, 15(1):22-29.
|
| [11] |
胡艳霞, 王成, 李弼程, 等. 基于多头注意力机制Tree-LSTM的句子语义相似度计算[J]. 中文信息学报, 2020, 34(3):23-33.
|
|
Hu Yanxia, Wang Cheng, Li Bicheng, et al. Sentence semantic similarity computation based on Tree-LSTM with multi-head attention[J]. Journal of Chinese Information Technology, 2020, 34(3):23-33.
|
| [12] |
赵琪, 杜彦辉, 芦天亮, 等. 基于Capsule-BiGRU的文本相似度分析算法[J]. 计算机工程与应用, 2021, 57(15):171-177.
doi: 10.3778/j.issn.1002-8331.2004-0253
|
|
Zhao Qi, Du Yanhui, Lu Tianliang, et al. Algorithm of text similarity analysis based on Capsule-BiGRU[J]. Computer Engineering and Applications, 2021, 57(15):171-177.
doi: 10.3778/j.issn.1002-8331.2004-0253
|
| [13] |
杨泉. 基于遗传算法的词语语义相似度计算研究[J]. 计算机技术与发展, 2021, 31(2):8-13.
|
|
Yang Quan. Research on word semantic similarity calculation based on genetic algorithm[J]. Computer Technology and Development, 2021, 31(2):8-13.
|
| [14] |
于碧辉, 王加存. 孪生网络中文语义匹配方法的研究[J]. 小型微型计算机系统, 2021, 42(2):231-234.
|
|
Yu Bihui, Wang Jiacun. Research on Chinese semantic matching in siamese network[J]. Journal of Chinese Computer Systems, 2021, 42(2):231-234.
|
| [15] |
杨德志, 柯显信, 余其超, 等. 基于RCNN的问题相似度计算方法[J]. 计算机工程与科学, 2021, 43(6):1076-1080.
|
|
Yang Dezhi, Ke Xianxin, Yu Qichao, et al. Problem similarity calculation method based on RCNN[J]. Computer Engineering and Science, 2021, 43(6):1076-1080.
|
| [16] |
赵小虎, 赵成龙. 基于多特征语义匹配的知识库问答系统[J]. 计算机应用, 2020, 40(7):1873-1878.
doi: 10.11772/j.issn.1001-9081.2019111895
|
|
Zhao Xiaohu, Zhao Chenglong. Knowledge base question answering system based on multi-feature semantic matching[J]. Journal of Computer Applications, 2020, 40(7):1873-1878.
doi: 10.11772/j.issn.1001-9081.2019111895
|
| [17] |
牛奉高, 高旭霞. 基于加权网络改进的中文短文本相似性度量模型[J]. 情报学报, 2021, 40(3):278-285.
|
|
Niu Fenggao, Gao Xuxia. An improved similarity measurement model for Chinese short texts based on weighted network[J]. Journal of the China Society for Scientific and Technical Information, 2021, 40(3):278-285.
|
| [18] |
周练. Word2Vec的工作原理及应用探究[J]. 科技情报开发与经济, 2015, 25(2):145-148.
|
|
Zhou Lian. Exploration of the working principle and application of Word2Vec[J]. Science and Technology Information Development and Economy, 2015, 25(2):145-148.
|
| [19] |
朱张莉, 饶元, 吴渊, 等. 注意力机制在深度学习中的研究进展[J]. 中文信息学报, 2019, 33(6):1-11.
|
|
Zhu Zhangli, Rao Yuan, Wu Yuan, et al. Research progress of attention mechanism in deep learning[J]. Journal of Chinese Information Technology, 2019, 33(6):1-11.
|