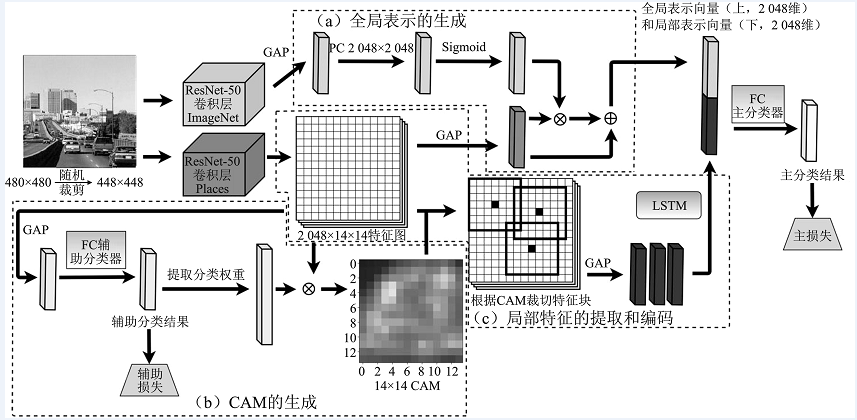
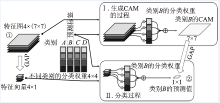
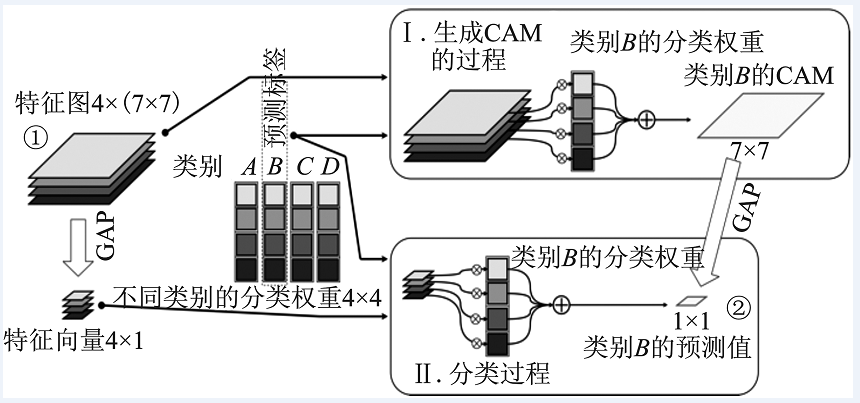
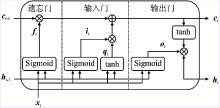
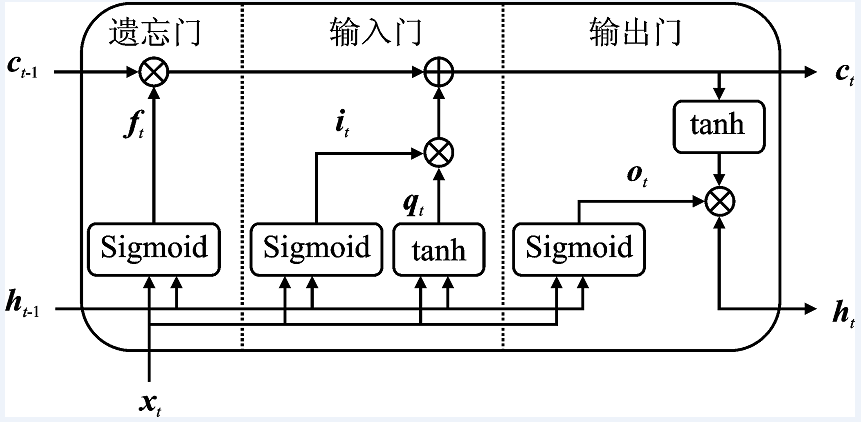
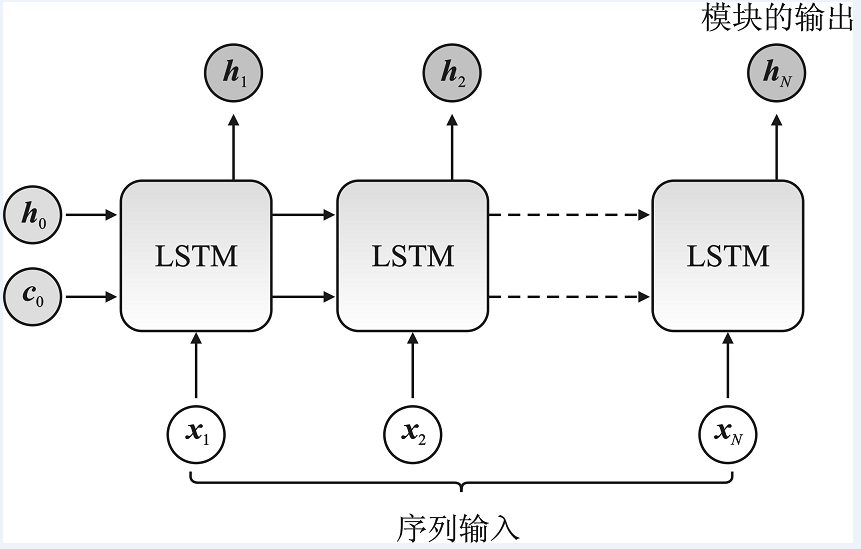
| [1] |
Oliva A, Torralba A. Modeling the shape of the scene: A holistic representation of the spatial envelope[J]. International Journal of Computer Vision, 2001, 42(3):145-175.
doi: 10.1023/A:1011139631724
|
| [2] |
Wu J X, Rehg J M. Centrist: A visual descriptor for scene categorization[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(8):1489-1501.
doi: 10.1109/TPAMI.2010.224
|
| [3] |
Xiao Y, Wu J X, Yuan J S. mCENTRIST: A multi-channel feature generation mechanism for scene categorization[J]. IEEE Transactions on Image Processing, 2014, 23(2):823-836.
doi: 10.1109/TIP.2013.2295756
|
| [4] |
Lowe D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2):91-110.
doi: 10.1023/B:VISI.0000029664.99615.94
|
| [5] |
Dalal N, Triggs B. Histograms of oriented gradients for human detection[C]. San Diego:IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2005.
|
| [6] |
Ojala T, Pietikainen M, Maenpaa T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(7):971-987.
doi: 10.1109/TPAMI.2002.1017623
|
| [7] |
Bay H, Ess A, Tuytelaars T, et al. Speeded-up robust features (SURF)[J]. Computer Vision and Image Understanding, 2008, 110(3):346-359.
doi: 10.1016/j.cviu.2007.09.014
|
| [8] |
Sivic J, Zisserman A. Video Google: a text retrieval approach to object matching in videos[C]. Nice:Proceedings of the Ninth IEEE International Conference on Computer Vision, 2003.
|
| [9] |
Lazebnik S, Schmid C, Ponce J. Beyond bags of features: spatial pyramid matching for recognizing natural scene categories[C]. New York:IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2006.
|
| [10] |
Xie L, Lee F, Liu L, et al. Improved spatial pyramid matching for scene recognition[J]. Pattern Recognition, 2018, 82(1):118-129.
doi: 10.1016/j.patcog.2018.04.025
|
| [11] |
Perronnin F, Sánchez J, Mensink T. Improving the fisher kernel for large-scale image classification[C]. Heidelberg:Proceedings of the European Conference on Computer Vision, 2010.
|
| [12] |
Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6):84-90.
doi: 10.1145/3065386
|
| [13] |
Russakovsky O, Deng J, Su H, et al. Imagenet large scale visual recognition challenge[J]. International Journal of Computer Vision, 2015, 115(3):211-252.
doi: 10.1007/s11263-015-0816-y
|
| [14] |
Gong Y, Wang L, Guo R, et al. Multi-scale orderless pooling of deep convolutional activation features[C]. Zurich:Proceedings of the European Conference on Computer Vision, 2014.
|
| [15] |
Dixit M, Chen S, Gao D, et al. Scene classification with semantic fisher vectors[C]. Boston:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015.
|
| [16] |
Xie L, Lee F, Yan Y, et al. Sparse decomposition of convolutional features for scene recognition[C]. Beijing:Proceedings of the Second IEEE International Conference on Computational Intelligence and Applications, 2017.
|
| [17] |
谢林, 李菲菲, 陈虬. 基于稀疏自动编码机的场景识别算法[J]. 电子科技, 2019, 32(1):38-41.
|
|
Xie Lin, Li Feifei, Chen Qiu. Scene recognition algorithm based on sparse autoencoder[J]. Electronic Science and Technology, 2019, 32(1):38-41.
|
| [18] |
Xie L, Lee F F, Liu L, et al. Hierarchical coding of convolutional features for scene recognition[J]. IEEE Transactions on Multimedia, 2020, 22(5):1182-1192.
doi: 10.1109/TMM.2019.2942478
|
| [19] |
缪冉, 李菲菲, 陈虬. 基于卷积神经网络与多尺度空间编码的场景识别方法[J]. 电子科技, 2020, 33(12):54-58.
|
|
Miao Ran, Li Feifei, Chen Qiu. Scene recognition algorithm based on convolutional neural networks and multi-scale space encoding[J]. Electronic Science and Technology, 2020, 33(12):54-58.
|
| [20] |
Liu B, Liu J, Wang J, et al. Learning a representative and discriminative part model with deep convolutional features for scene recognition[C]. Singapore:Proceedings of the Asian Conference on Computer Vision, 2014.
|
| [21] |
Zhou B, Lapedriza A, Khosla A, et al. Places: A 10 million image database for scene recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40(6):1452-1464.
doi: 10.1109/TPAMI.2017.2723009
|
| [22] |
He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]. Las Vegas:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016.
|
| [23] |
Seong H, Hyun J, Kim E. FOSNet: An end-to-end trainable deep neural network for scene recognition[J]. IEEE Access, 2020(8):82066-82077.
|
| [24] |
Zhao Z, Larson M. From volcano to toyshop: Adaptive discriminative region discovery for scene recognition[C]. Seoul:Proceedings of the Twenty-sixth ACM International Conference on Multimedia, 2018.
|
| [25] |
Zhou B, Khosla A, Lapedriza A, et al. Learning deep features for discriminative localization[C]. Las Vegas:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016.
|
| [26] |
Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural Computation, 1997, 9(8):1735-1780.
pmid: 9377276
|
| [27] |
Quattoni A, Torralba A. Recognizing indoor scenes[C]. Miami:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2009.
|
| [28] |
Yang S, Ramanan D. Multi-scale recognition with DAG-CNNs[C]. Boston:Proceedings of the IEEE International Conference on Computer Vision, 2015.
|
| [29] |
Jiang S, Chen G, Song X, et al. Deep patch representations with shared codebook for scene classification[J]. ACM Transactions on Multimedia Computing,Communications, and Applications, 2019, 15(1s):1-17.
|
| [30] |
Bai S, Tang H, An S. Coordinate CNNs and LSTMs to categorize scene images with multi-views and multi-levels of abstraction[J]. Expert Systems with Applications, 2019, 120(7):298-309.
doi: 10.1016/j.eswa.2018.08.056
|
| [31] |
Xie G S, Zhang X Y, Yan S, et al. Hybrid CNN and dictionary-based models for scene recognition and domain adaptation[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2015, 27(6):1263-1274.
doi: 10.1109/TCSVT.2015.2511543
|
| [32] |
Guo S, Huang W, Wang L, et al. Locally supervised deep hybrid model for scene recognition[J]. IEEE Transactions on Image Processing, 2016, 26(2):808-820.
doi: 10.1109/TIP.2016.2629443
|
| [33] |
Pan Y, Xia Y, Shen D. Foreground fisher vector: encoding class-relevant foreground to improve image classification[J]. IEEE Transactions on Image Processing, 2019, 28(10):4716-4729.
doi: 10.1109/TIP.2019.2908795
|
| [34] |
Herranz L, Jiang S, Li X. Scene recognition with CNNs: objects, scales and dataset bias[C]. Las Vegas:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016.
|
| [35] |
Wang Z, Wang L, Wang Y, et al. Weakly supervised patchnets: Describing and aggregating local patches for scene recognition[J]. IEEE Transactions on Image Processing, 2017, 26(4):2028-2041.
doi: 10.1109/TIP.2017.2666739
pmid: 28207394
|
| [36] |
Liu Y, Chen Q, Chen W, et al. Dictionary learning inspired deep network for scene recognition[C]. New Orleans:Proceedings of the AAAI Conference on Artificial Intelligence, 2018.
|
| [37] |
Cheng X, Lu J, Feng J, et al. Scene recognition with objectness[J]. Pattern Recognition, 2018, 7(2):474-487.
|
| [38] |
López-Cifuentes A, Escudero-Viñolo M, Bescós J, et al. Semantic-aware scene recognition[J]. Pattern Recognition, 2020, 102(1):1-15.
|